






在深入神经网络的具体细节之前,我们先快速浏览一下本周的内容。上一周我们讨论了逻辑回归,了解了这个模型(下图左)如何与下面的公式(下图右)建立联系。
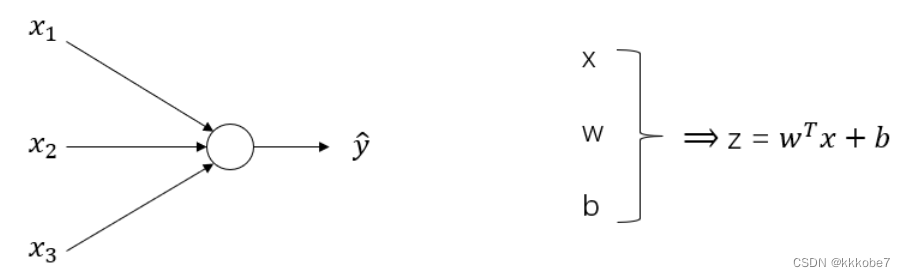
如上所示,首先你需要输入特征
x
x
x,参数
w
w
w和
b
b
b,通过这些你就可以计算出
z
z
z。
x
w
b
}
⟹
z
=
w
T
x
+
b
⟹
α
=
σ
(
z
)
⟹
L
(
a
,
y
)
\begin{aligned} &\left.\begin{array}{l} x \\ w \\ b \end{array}\right\} \Longrightarrow z=w^{T} x+b \Longrightarrow \alpha=\sigma(z) \Longrightarrow L(a, y) \end{aligned}
xwb⎭⎬⎫⟹z=wTx+b⟹α=σ(z)⟹L(a,y)
接下来就可以计算出 a a a。我们将符号 α \alpha α换为 a a a表示输出 y ^ ⇒ a = σ ( z ) \hat{y} \Rightarrow a = \sigma(z) y^⇒a=σ(z),然后可以计算出损失函数loss function L ( a , y ) L(a, y) L(a,y)。
神经网络看起来是如下图这个样子,我们将许多sigmoid单元堆叠起来形成一个神经网络。对于其中的节点,它包含了之前讲的计算的两个步骤:首先通过公式计算出值 z z z,然后通过 σ ( z ) \sigma(z) σ(z)计算值 a a a。
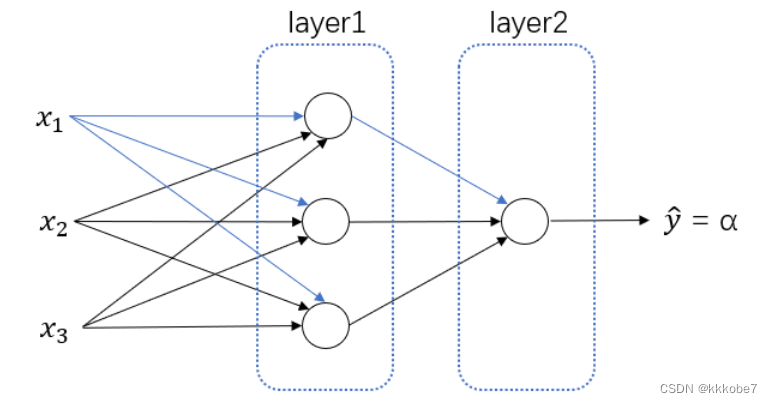
在这个神经网络对应的3个节点,首先计算第一层网络中的各个节点相关的数 z [ 1 ] z^{[1]} z[1],接着计算 α [ 1 ] \alpha^{[1]} α[1],在计算下一层网络同理。在这里,我们使用符号 [ m ] ^{[m]} [m]表示第 m m m层网络中节点相关的数,这些节点的集合被称为第 m m m层网络。这样可以保证 m ^{m} m不会和我们之前用来表示单个的训练样本的 ( i ) ^{(i)} (i)(即我们用来表示第 i i i个训练样本)混淆。
整个计算过程如下
x
W
[
1
]
b
[
1
]
}
⟹
z
[
1
]
=
W
[
1
]
x
+
b
[
1
]
⟹
a
[
1
]
=
σ
(
z
[
1
]
)
\left.\begin{array}{r} x \\ W^{[1]} \\ b^{[1]} \end{array}\right\} \Longrightarrow z^{[1]}=W^{[1]} x+b^{[1]} \Longrightarrow a^{[1]}=\sigma\left(z^{[1]}\right)
xW[1]b[1]⎭⎬⎫⟹z[1]=W[1]x+b[1]⟹a[1]=σ(z[1])
x d W [ 1 ] d b [ 1 ] } ⇐ d z [ 1 ] = d ( W [ 1 ] x + b [ 1 ] ) ⇐ d α [ 1 ] = d σ ( z [ 1 ] ) \left.\begin{array}{r} x \\ d W^{[1]} \\ d b^{[1]} \end{array}\right\} \Leftarrow d z^{[1]}=d\left(W^{[1]} x+b^{[1]}\right) \Leftarrow d \alpha^{[1]}=d \sigma\left(z^{[1]}\right) xdW[1]db[1]⎭⎬⎫⇐dz[1]=d(W[1]x+b[1])⇐dα[1]=dσ(z[1])
类似逻辑回归,在向前计算后需要向后计算,接下来你需要使用另外一个线性方程对应的参数计算
z
[
2
]
z^{[2]}
z[2],计算
a
[
2
]
a^{[2]}
a[2],此时
a
[
2
]
a^{[2]}
a[2]就是整个神经网络最终的输出,用
y
^
\hat{y}
y^表示。
d
a
[
1
]
=
d
σ
(
z
[
1
]
)
d
W
[
2
]
d
b
[
2
]
}
⟸
d
z
[
2
]
=
d
(
W
[
2
]
α
[
1
]
+
b
[
2
]
)
⟸
d
a
[
2
]
=
d
σ
(
z
[
2
]
)
⟸
d
L
(
a
[
2
]
,
y
)
\begin{aligned} &\left.\begin{array}{r} d a^{[1]}=d \sigma\left(z^{[1]}\right) \\ d W^{[2]} \\ d b^{[2]} \end{array}\right\} \Longleftarrow d z^{[2]}=d\left(W^{[2]} \alpha^{[1]}+b^{[2]}\right) \Longleftarrow d a^{[2]}=d \sigma\left(z^{[2]}\right) \Longleftarrow d L\left(a^{[2]}, y\right) \end{aligned}
da[1]=dσ(z[1])dW[2]db[2]⎭⎬⎫⟸dz[2]=d(W[2]α[1]+b[2])⟸da[2]=dσ(z[2])⟸dL(a[2],y)
在这个神经网络中,我们反复的计算
z
z
z和
a
a
a,计算
a
a
a和
z
z
z,最后得到了最终输出loss function。
你应该记得逻辑回归中,有一些从后向前的计算用来计算导数 d a 、 d z da、dz da、dz。同样,在神经网络中我们也有从后向前的计算,看起来就像之前的公式一样,最后会计算 d a [ 2 ] 、 d z [ 2 ] da^{[2]}、dz^{[2]} da[2]、dz[2],计算出来之后,然后计算 d w [ 2 ] 、 d b [ 2 ] dw^{[2]} 、 db^{[2]} dw[2]、db[2]等,如公式中的箭头一样,从右到左反向计算。
这一节中我们有很多的新符号和细节,我们会在接下来的几节中仔细讨论具体细节。















 1055
1055











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









