






 本文聚焦结构化剪枝神经网络的对抗训练。介绍了结构化剪枝主流方案及优缺点,梳理了相关研究成果与不足。通过MNIST数据集和LeNet网络开展实验,记录细节并分析结果,发现模型容量有下限要求,还探讨了剪枝与对抗训练冲突原因及解决思路。
本文聚焦结构化剪枝神经网络的对抗训练。介绍了结构化剪枝主流方案及优缺点,梳理了相关研究成果与不足。通过MNIST数据集和LeNet网络开展实验,记录细节并分析结果,发现模型容量有下限要求,还探讨了剪枝与对抗训练冲突原因及解决思路。
课题:结构化剪枝神经网络的对抗训练
课题背景
2014 年,神经网络被发现易受到对抗样本(adversarial examples)[1-2]的攻 击。对抗训练(adversarial training)[3]是防御对抗样本的主流方法之一。剪枝 (pruning)[4,5,8]是模型稀疏化方法,通过剪掉神经网络中不重要的参数,减小 模型存储空间并提高推理速度。现有研究工作提出了非结构化剪枝的对抗训练 [6-7],能够使得剪枝过后的神经网络同时满足稀疏性和鲁棒性的要求。非结构化 剪枝的缺点是其部署困难,需要以精心设计的稀疏化矩阵的存储和计算优化方法作为底层支持,且实际压缩比和加速比往往达不到理论值。相比之下,结构化剪 枝[9]更容易部署,然而却鲜有研究探讨结构化剪枝神经网络的对抗训练问题。
任务要求
1. 阅读提供的参考文献并进行一定程度的自主调研,回答以下问题:
(1) 结构化剪枝的主流实现方案有哪些,各自的优缺点如何?
结构化剪枝方法在通道或甚至层的层次上进行修剪。由于原始卷积结构仍然保留,因此不需要专用的硬件/库来实现。
结构化剪枝的主流实现方式有:依赖权重、基于激活图、正则化、动态剪枝、神经结构搜索。
-
依赖权重:取决于权重的标准根据滤波器的权重来评估滤波器的重要性。
优点:
-
良好的可解释性:依赖权重的剪枝方法直接基于权重的重要性进行剪枝,因此剪枝后的模型结构相对简单,更易于解释和理解。
-
运行速度快:相较于其他复杂的结构化剪枝方案,依赖权重的结构化剪枝方案计算相对简单。
缺点:
-
需要人工选择阈值:依赖权重的剪枝方法通常需要人工选择剪枝率或阈值,这需要进行实验和调整,增加了实现和调参的难度。
-
不适用于动态任务:对于动态任务或需要在线学习的场景,依赖权重的剪枝可能不太适用,因为模型结构在动态环境中可能需要频繁调整。
-
-
基于激活图:基于激活图的滤波器剪枝。激活通道剪枝是另一种形式的滤波器剪枝,因为去除激活图的通道相当于去除滤波器。
优点:
-
考虑数据相关性:该方法利用激活图来剪枝,因此能够更好地反映网络对于输入数据的响应情况,剪枝的目标更贴合于具体的数据集。
-
抑制过拟合:剪枝可以降低网络的复杂性,从而抑制过拟合的风险,提高模型的泛化能力。
缺点:
-
计算开销较大:计算激活图需要消耗一定的计算资源,尤其是在大型网络上,可能会增加训练时间和内存占用。
-
需要适当阈值选择:基于激活图的剪枝方法也需要设置合适的剪枝阈值或剪枝率,这需要进行实验和调整,可能需要额外的试错。
-
-
正则化:正则化可以通过添加不同的稀疏正则 R s ( − ) R_s(-) Rs(−)来学习结构稀疏网络。
优点:
- 简单有效:正则化的剪枝方法相对简单易实现,不需要额外的计算资源和训练过程,只需在损失函数中添加正则化项即可实现剪枝。
缺点:
-
超参数选择:正则化项的系数需要手动调整,选择合适的超参数是一项挑战性任务,可能需要进行实验和调参。
-
剪枝率不确定:与依赖权重或基于激活图的剪枝方法相比,正则化的剪枝方法往往不能直接确定具体的剪枝率,因此可能无法获得特定剪枝率的模型。
-
依赖初始化:正则化的剪枝方法对于初始权重的选择较为敏感,可能需要特定的初始化策略来取得较好的剪枝效果。
-
动态剪枝:也被称为软剪枝。动态剪枝可以在训练和推理过程中进行。训练过程中的动态剪枝旨在通过在训练过程中保持动态剪枝掩码来保持模型的代表性。
优点:
-
自适应剪枝:动态剪枝可以根据实时的训练情况和梯度信息来调整模型结构,使得模型能够更好地适应不断变化的数据分布和任务要求。
-
更高的剪枝率:相比静态剪枝,动态剪枝往往可以获得更高的剪枝率,因为它根据实时梯度信息更准确地选择要剪枝的目标。
缺点:
-
计算开销较大:动态剪枝需要在每个训练步骤中实时计算梯度和调整模型结构,这增加了计算开销和训练时间。
-
实现复杂:相对于静态剪枝,动态剪枝的实现较为复杂,需要设计合适的剪枝策略和调整方法
-
可能带来不稳定性:动态剪枝的实时调整可能导致模型结构的不稳定性,可能需要更多的训练步骤来稳定模型性能。
-
-
神经结构搜索:由于手动确定与剪枝相关的超参数(如层间剪枝率)非常麻烦,因此提出了神经架构搜索(NAS)来自动寻找剪枝结构。
优点:
-
自动化:NAS剪枝是自动化的方法,不需要人工介入。它可以通过搜索算法自动寻找最优的神经网络结构,并应用剪枝技术来进一步优化模型。
-
个性化模型:NAS剪枝可以针对特定任务和数据集搜索得到最适合的网络结构,从而实现个性化的模型优化。
缺点:
-
过于复杂:由于NAS剪枝融合了神经结构搜索和剪枝技术,其实现和调整可能比较复杂,需要专业的知识和经验。
-
计算开销较大:NAS剪枝需要在搜索过程中进行大量的模型训练和评估,计算开销较大,需要较长的时间。
-
超参数选择:NAS剪枝涉及到一些超参数的选择,如搜索空间的大小、搜索算法的选择等,这些参数需要谨慎选择,可能需要进行大量的试验。
-
(2) 是否有研究工作探讨了结构化剪枝的对抗训练、对抗鲁棒性等相关问题?如果有,现有研究的最新结论是什么?现有研究尚存在哪些不足之处值得进一步解决?
目前有研究工作探讨了结构化剪枝的对抗训练、对抗鲁棒性等相关问题。
2019年,在Adversarial robustness vs. model compression, or both?[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 111-120.中:
- 作者使用基于ADMM的修建,构建了一个框架,通过实现并发权值修剪和对抗性训练来实现对抗性鲁棒性和模型压缩。
- 作者发现,在对抗设置中,权值剪枝对于减小网络模型规模至关重要,即使从大模型继承初始化,也无法同时获得对抗鲁棒性和高标准精度。
- 作者系统的研究了不同剪枝方案对与对抗鲁棒性和模型压缩的影响,发现在对DNN模型进行修剪时,不规则修剪方案最能保持标准精度和对抗鲁棒性。
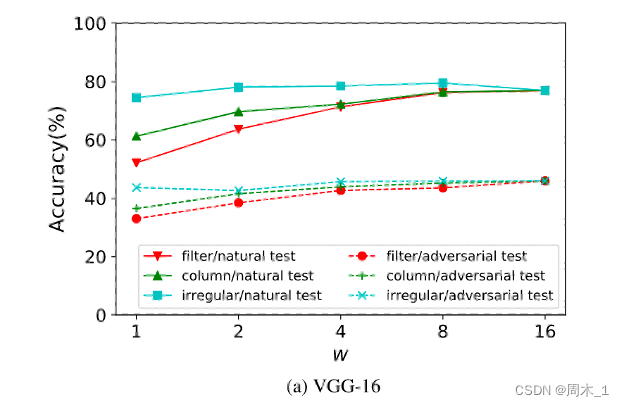
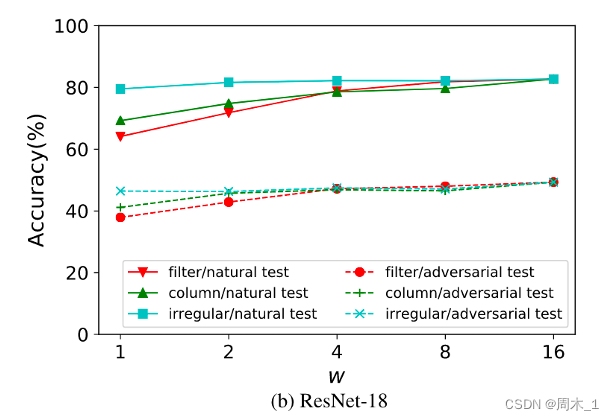
2020年,在Hydra: Pruning adversarially robust neural networks[J]. Advances in Neural Information Processing Systems, 2020, 33: 19655- 19666.中:
- 作者通过将其公式化为经验风险最小化问题,开发出一种新的剪枝技术,该剪枝策略能够注意到鲁棒性训练的目标。作者采用了一种基于重要性评分的优化技术,并提出了重要性评分的比例初始化(scaled initialization of importance scores)。
- 作者证明了非鲁棒或弱鲁棒网络中存在高度鲁棒的子网络。特别是,在没有可验证鲁棒性的经验鲁棒网络中,作者能够找到具有已验证鲁棒精度的接近最新技术的子网络。
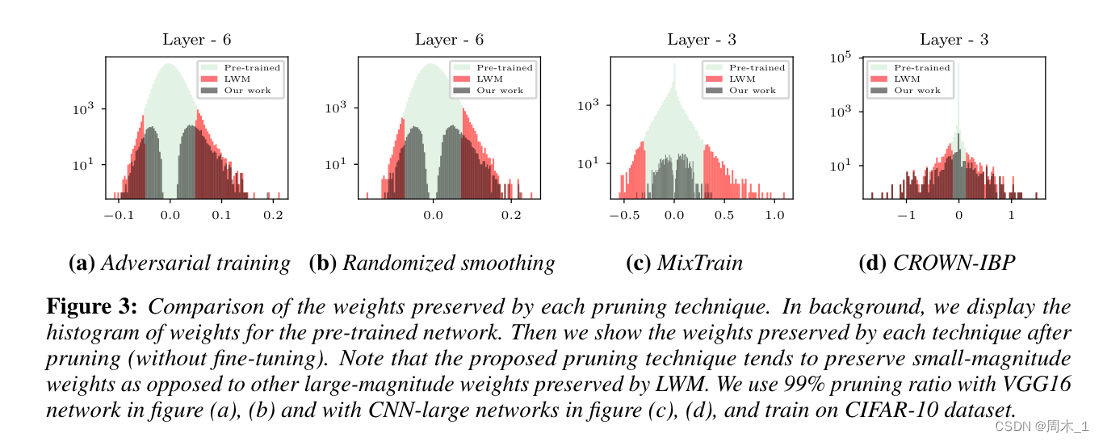
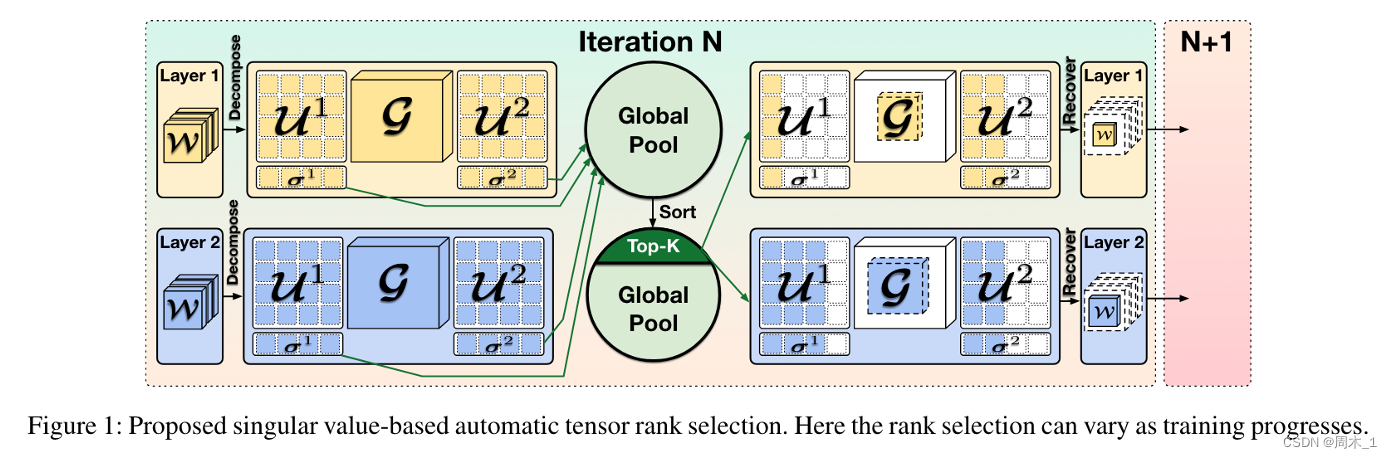
2022年,在CSTAR: Towards Compact and STructured Deep Neural Networks with Adversarial Robustness[J]. arXiv preprint arXiv:2212.01957, 2022.中:
- 作者提出一个统一约束化问题的低秩性和鲁棒性的框架,并在此基础上给出了一种对抗训练的流程,可以同时确保高压缩性和鲁棒性。
- 作者提出一种低成本的自动秩选择方案,从而避免了繁琐的手动排序,同时保证了高性能。
2023年,在Robust Tickets Can Transfer Better: Drawing More Transferable Subnetworks in Transfer Learning[J]. arXiv preprint arXiv:2304.11834, 2023.中:
-
作者发现鲁棒性门票(robust tickets)可以很好的进行迁移。
-
作者开发新的流水线更有效的将子网络迁移到下游任务,推动了可实现的可转移性和稀疏性权衡。
-
作者实证分析了鲁棒彩票可转移性背后的潜在原因,发现鲁棒彩票的可转移性与其处理领域间隙的能力高度相关。
现有研究的尚存在的值得改进之处:
从大的方向来说
- “如何同时兼具高压缩性和鲁棒性”是所有当前研究都面临的问题,开发出一套完整的具有高压缩性和鲁棒性的训练流程自然是可以改进的方向。
- “如何保持网络原有的性能”也是所有研究需要面临的问题,在剪枝和对抗性训练这两个单独方向的研究中,保持网络原有的性能都是一个重要的目的。对于剪枝和对抗性训练结合的课题而言,保持网络性能也是一个重要的改进方向。
从细节上来说:
- 以2023年Robust Tickets Can Transfer Better: Drawing More Transferable Subnetworks in Transfer Learning一文为例,文中提出了鲁棒彩票的可转移性与其处理领域间隙的能力高度相关,即观察到在处理领域间隙(FID)较小的情况下,鲁棒彩票低于/等于自然彩票,但是却未给出相应的解决方案,该点可能可以继续深挖。
2. 在现有开源代码的基础上,开展实验实现结构化剪枝的对抗训练:
(1) 详细记录实验细节,包括:所用数据集、模型;是如何将结构化剪枝和对抗训练结合起来的;剪枝粒度是如何考虑的(要求包含尽可能多的粒度);各个环节的超参数如何设置;模型性能(包括模型正常准确率、对抗鲁棒性、结构化剪枝稀疏度)的测评方法和结果。
主要参考:Adversarial robustness vs. model compression, or both?
数据集:MNIST数据集。
模型:LeNet网络。值得一提的是,该实验使用width_multiplier关键字来控制LeNet网络的宽度,所以本实验中的网络容量和传统LeNet网络容量是不同的。
实验原理/实验步骤(如何将结构化剪枝和对抗训练结合起来的):
- pretrain
- ADMM
- retrain
该实验采用基于ADMM(交替方向乘子方法)的并发对抗训练和权重剪枝,具体的实验原理和步骤如下。
我们制定一个方便应用ADMM的问题如下:
min
θ
i
E
(
x
,
y
)
∼
D
[
max
δ
∈
Δ
L
(
θ
,
x
+
δ
,
y
)
]
+
∑
i
=
1
N
g
i
(
z
i
)
s
.
t
.
θ
i
=
z
i
,
i
=
1
,
.
.
.
,
N
\min_{ \theta_i}{\mathbb{E}_{(x, y)\sim D}[ \max_{\delta \in \Delta}{ L(\theta, x+\delta, y)}] +\sum^N_{i=1}g_i(z_i)} \\ s.t.\ \ \ \theta_i=z_i,\ i=1,...,N
θiminE(x,y)∼D[δ∈ΔmaxL(θ,x+δ,y)]+i=1∑Ngi(zi)s.t. θi=zi, i=1,...,N
其中,
θ
i
\theta_i
θi是每一层的权重参数。
g
i
(
θ
i
)
=
{
0
i
f
θ
i
∈
S
i
+
∞
o
t
h
e
r
w
i
s
e
g_i(\theta_i)= \begin{cases} 0\ \ \ \ \ \ if\theta_i\in S_i \\ +\infty\ \ \ \ otherwise \end{cases}
gi(θi)={0 ifθi∈Si+∞ otherwise
是一个约束权重稀疏的指标函数。不同的权重剪枝方案通过一组定义的
S
i
S_i
Si来实现。
z
i
z_i
zi是辅助变量,让使用ADMM称为可能。
ADMM是建立在一个增广拉格朗日问题上的,在这个问题上,增广拉格朗日函数的形式如下:
ℓ
(
{
θ
i
}
,
{
z
i
}
,
{
u
i
}
)
=
E
(
x
,
y
)
∼
D
[
max
δ
∈
Δ
L
(
θ
,
x
+
δ
,
y
)
]
+
∑
i
=
1
N
g
i
(
z
i
)
+
∑
i
=
1
N
u
T
(
θ
i
−
z
i
)
+
ρ
2
∑
i
=
1
N
∣
∣
θ
i
−
z
i
∣
∣
2
2
\ell(\{\theta_i\}, \{z_i\}, \{u_i\})= {\mathbb{E}_{(x, y)\sim D}}[\max_{\delta \in \Delta}{L(\theta, x+\delta, y)}]+ \sum^N_{i=1}g_i(z_i)+\sum^N_{i=1}u^T(\theta_i-z_i)+\frac{\rho}{2}\sum^N_{i=1}||\theta_i-z_i||^2_2
ℓ({θi},{zi},{ui})=E(x,y)∼D[δ∈ΔmaxL(θ,x+δ,y)]+i=1∑Ngi(zi)+i=1∑NuT(θi−zi)+2ρi=1∑N∣∣θi−zi∣∣22
其中,
{
u
i
}
\{u_i\}
{ui}是等式约束相关的拉格朗日乘子,
ρ
>
0
\rho>0
ρ>0是给定的增强参数。通过形成增广拉格朗日函数,ADMM将问题分解为两个字问题:
{
θ
i
k
}
=
a
r
g
min
θ
i
ℓ
(
{
θ
i
}
,
{
z
i
k
−
1
}
,
{
u
i
k
−
1
}
)
{
z
i
k
}
=
a
r
g
min
z
i
ℓ
(
{
θ
i
k
}
,
{
z
i
}
,
{
u
i
k
−
1
}
)
\{\theta_i^k\}=arg\ \min_{\theta_i}\ell(\{\theta_i\}, \{z_i^{k-1}\}, \{u_i^{k-1}\}) \\ \{z_i^k\}=arg\ \min_{z_i}\ell(\{\theta_i^k\}, \{z_i\}, \{u_i^{k-1}\})
{θik}=arg θiminℓ({θi},{zik−1},{uik−1}){zik}=arg ziminℓ({θik},{zi},{uik−1})
其中,
k
k
k是迭代指数。拉格朗日乘子通过
u
i
k
:
=
u
i
k
−
1
+
ρ
(
θ
i
k
−
z
i
k
)
u_i^k:=u_i^{k-1}+\rho(\theta_i^k-z_i^k)
uik:=uik−1+ρ(θik−zik)更新。
第一个问题的显式如下:
min
θ
i
E
(
x
,
y
)
∼
D
[
max
δ
∈
Δ
L
(
θ
,
x
+
δ
,
y
)
]
+
ρ
2
∑
i
=
1
N
∣
∣
θ
i
−
z
i
+
u
i
k
∣
∣
2
2
\min_{ \theta_i}{\mathbb{E}_{(x, y)\sim D}[ \max_{\delta \in \Delta}{ L(\theta, x+\delta, y)}] +\frac{\rho}{2}\sum^N_{i=1}||\theta_i-z_i+u_i^k||^2_2}
θiminE(x,y)∼D[δ∈ΔmaxL(θ,x+δ,y)]+2ρi=1∑N∣∣θi−zi+uik∣∣22
上式中,第一项是一个min-max问题,与对抗训练的loss function一致,在此处我们可以使用PGD对抗训练,以T次迭代和随机初始值来解决内部的max问题。第二项是由于增广拉格朗日函数中的增广项存在而产生的。给定扰动参数
δ
\delta
δ之后,我们可以使用随机梯度下降方法来解决整个最小化问题。
第二个问题的显式如下:
min
z
i
∑
i
=
1
N
g
i
(
z
i
)
+
ρ
2
∑
i
=
1
N
∣
∣
θ
i
−
z
i
+
u
i
k
∣
∣
2
2
\min_{z_i}{\sum^N_{i=1}g_i(z_i)+\frac{\rho}{2}\sum^N_{i=1}||\theta_i-z_i+u_i^k||^2_2}
zimini=1∑Ngi(zi)+2ρi=1∑N∣∣θi−zi+uik∣∣22
g
i
(
.
)
g_i(.)
gi(.)是由
S
i
S_i
Si指定的指示函数,因此该问题可以使用解析法求解,其解析解是:
z
i
k
+
1
=
Π
S
i
(
θ
i
k
+
1
+
u
i
k
)
z_i^{k+1}=\Pi_{S_i}(\theta_i^{k+1}+u_i^k)
zik+1=ΠSi(θik+1+uik)
其中
Π
S
i
(
.
)
\Pi_{S_i}(.)
ΠSi(.)是
θ
i
k
+
1
+
u
i
k
\theta_i^{k+1}+u_i^k
θik+1+uik在
S
i
S_i
Si上的欧几里得投影。
剪枝粒度(剪枝粒度是如何考虑的):主要分为滤波器剪枝、列剪枝、不规则剪枝。
将 θ i \theta_i θi还原为四维张量形式,即 θ i ∈ R N i × C i × H i × W i \theta_i \in R^{N_i\times C_i\times H_i\times W_i} θi∈RNi×Ci×Hi×Wi,其中 N i , C i , H i , W i N_i, C_i, H_i, W_i Ni,Ci,Hi,Wi分别表示滤波器的个数、滤波器的通道数、滤波器的高度和滤波器的宽度。
-
滤波器剪枝:
θ i ∈ S i : = { θ i ∣ ∣ ∣ θ i ∣ ∣ n = 0 < = α i } \theta_i \in S_i :=\{\theta_i|\ ||\theta_i||_{n=0}<=\alpha_i\} θi∈Si:={θi∣ ∣∣θi∣∣n=0<=αi}
其中, ∣ ∣ θ i ∣ ∣ n = 0 ||\theta_i||_{n=0} ∣∣θi∣∣n=0表示包含非零元素的滤波器的数量。在上述约束下,为了得到 z i k + 1 = Π S i ( θ i k + 1 + u i k ) z_i^{k+1}=\Pi_{S_i}(\theta_i^{k+1}+u_i^k) zik+1=ΠSi(θik+1+uik)的解,我们首先计算 O n = ∣ ∣ ( θ i k + 1 + u i k ) n , : , : , : ∣ ∣ 2 2 O_n=||(\theta_i^{k+1}+u^k_i)_{n,:,:,:}||^2_2 On=∣∣(θik+1+uik)n,:,:,:∣∣22。然后我们保留 O n O_n On中最大的 α i \alpha_i αi,并且将其余值设置为0。 -
列剪枝:
θ i ∈ S i : = { θ i ∣ ∣ ∣ θ i ∣ ∣ c , h , w = 0 < = β i } \theta_i \in S_i :=\{\theta_i|\ ||\theta_i||_{c,h,w=0}<=\beta_i\} θi∈Si:={θi∣ ∣∣θi∣∣c,h,w=0<=βi}
其中, ∣ ∣ θ i ∣ ∣ c , h , w = 0 ||\theta_i||_{c,h,w=0} ∣∣θi∣∣c,h,w=0表示第 i i i层所有的滤波器中相同位置上包含非零元素的元素的个数。同样的,我们先计算 O n = ∣ ∣ ( θ i k + 1 + u i k ) : , c , h , w ∣ ∣ 2 2 O_n=||(\theta_i^{k+1}+u^k_i)_{:,c,h,w}||^2_2 On=∣∣(θik+1+uik):,c,h,w∣∣22,然后保留 O c O_c Oc中最大的 β i \beta_i βi,将其余的设置为0。 -
不规则剪枝:
θ i ∈ S i : = { θ i ∣ ∣ ∣ θ i ∣ ∣ 0 < = γ i } \theta_i \in S_i :=\{\theta_i|\ ||\theta_i||_{0}<=\gamma_i\} θi∈Si:={θi∣ ∣∣θi∣∣0<=γi}
在这种特殊情况下,我们限制第 i i i层的滤波器中也就是 θ i \theta_i θi的非零元素数目。我们在 θ i \theta_i θi中保留 γ i \gamma_i γi个最大幅值元素,其余元素都设置为0。
超参数设置(各个环节的超参数如何设置):
由于超参数数目较多,本部分仅仅提及重要的超参数,具体的超参数设置可以查看config.yaml。
- PGD超参数设置:
- 扰动上下限 ϵ \epsilon ϵ:0.3
- 迭代次数 T T T:40
- 损失函数 l o s s f u n c t i o n loss\ function loss function:交叉熵损失函数
- pretrain超参数设置:
- 初始学习率 l r lr lr:0.01
- epochs数量 e p o c h s epochs epochs:40
- 学习率调度器 l r _ s c h e d u l e r lr\_scheduler lr_scheduler:adam
- 优化器 o p t i m i z e r optimizer optimizer:adam
- admm超参数设置:
- 初始学习率 l r lr lr:0.01
- epochs数目 e p o c h s epochs epochs:40
- 优化器 o p t i m i z e r optimizer optimizer:sgd
- 初始
ρ
\rho
ρ:0.001。在admm阶段中,会多次调用
admm_multi_rho_scheduler(),每次会导致 ρ = 1.3 ∗ ρ \rho=1.3*\rho ρ=1.3∗ρ。
- retrain超参数设置:
- 初始学习率 l r lr lr:0.005
- epochs数目 e p o c h s epochs epochs:40
- 学习率调度器 l r _ s c h e d u l e r lr\_scheduler lr_scheduler:adam
- 优化器 o p t i m i z e r optimizer optimizer:adam
- 剪枝率超参数:
- 卷积层1 c o n v 1. w e i g h t conv1.weight conv1.weight:0.8
- 卷积层2 c o n v 2. w e i g h t conv2.weight conv2.weight:0.947
- 全连接层1 f c 1. w e i g h t fc1.weight fc1.weight:0.99
- 全连接层2 f c 2. w e i g h t fc2.weight fc2.weight:0.93
评估模型方法:
评估模型正常准确率、对抗鲁棒性是通过mian.py下test()完成的,而评估结构化剪枝稀疏度是通过admm.py下的test_sparsity()完成的,下面是两者的基本步骤:
-
test():-
初始化变量,用于累积自然状态和对抗状态的损失和正确分类数量。
-
在不计算梯度的情况下,循环遍历测试集中的每个批次。执行模型的前向传播,得到自然状态和对抗状态的输出。
-
计算自然状态和对抗状态的交叉熵损失、自然状态和对抗状态的正确分类数量、自然状态和对抗状态的平均损失。
-
计算自然状态和对抗状态的准确率,通过正确分类数量除以测试集样本数量得到百分比。
-
如果当前对抗准确率更高,并且不是ADMM阶段,则保存当前模型,并更新最佳对抗准确率。
-
打印自然状态和对抗状态的平均损失和准确率。
-
-
test_sparsity():由于每种剪枝粒度对应的测试步骤不完全相同,此处叙述滤波器剪枝的结构化剪枝稀疏度测试步骤- 遍历神经网络中的每一层参数(权重矩阵),对于每一层,检查是否在
config.prune_ratios中,如果在其中,则表示该层需要进行稀疏性测试,继续执行以下步骤。 - 获取当前层的权重矩阵,将权重矩阵重塑为 2D 数组,使得每一行表示一个滤波器的权重。
- 计算每个滤波器的权重在空间维度上的 L2 范数,得到一个行向量。计算 L2 范数为 0 的行(滤波器)的数量,以及 L2 范数不为 0 的行(滤波器)的数量。
- 输出当前层的滤波器稀疏性,即 L2 范数为 0 的行的比例。
- 累加当前层权重矩阵中为 0 的元素和不为0的元素的总数。
- 继续处理下一层参数,直到所有涉及的层都被处理完毕。
- 输出整体的压缩率,即所有涉及层的权重矩阵中零元素和非零元素的比例。
- 遍历神经网络中的每一层参数(权重矩阵),对于每一层,检查是否在
评估模型结果:
| 𝜔 | 4 | 8 | 16 |
|---|---|---|---|
| nat acc | 0.9704 | 0.9741 | 0.9777 |
| adv acc | 0.9488 | 0.9511 | 0.961 |
| compression rate | 13.6 | 14.66 | 15.4 |
filter(滤波器剪枝)下,𝜔=4, 8, 16时,nat acc(自然正确率)、adv acc(对抗正确率)和compression rate(压缩率)。其中conpression rate=全体元素的数目/非零元素的数目
分析:
在表1中,ω=8, 16两种情况下网络宽度增加1倍,压缩率仅仅相差0.74,这说明ω=16的模型在剪枝之后仍大约比ω=8的模型大2倍。相应的,在自然正确率和对抗正确率上ω=16要比ω=8的模型更加优秀,这是说明在同一种剪枝方式下,对抗训练需要网络拥有更大的容量。实验结果符合我们的预期。
| conv1 | conv2 | fc1 | fc2 | compression rate | |
|---|---|---|---|---|---|
| filter | 0.7812 / 0.8 | 0.9375 / 0.947 | // | // | 15.4 |
| column | 0.8 / 0.8 | 0.9462 / 0.947 | // | // | 17.85 |
| irregular | 0.8 / 0.8 | 0.9469 / 0.947 | 0.9899 / 0.99 | 0.9299 / 0.93 | 91.68 |
在𝜔=16时,filter(滤波器剪枝)、column(列剪枝)和irregular(不规则剪枝)在conv1、conv2、fc1、fc2的稀疏度以及compression rate(整体压缩率)。表中,a / b表示预期规定稀疏度为b,实际运行结果为a。由于在滤波器剪枝和列剪枝中并未对fc1和fc2层进行剪枝,所以表中为空。全体压缩率是指整个模型的元素数目/模型中非零元素个数。
| nat acc | adv acc | |
|---|---|---|
| filter | 0.9777 | 0.961 |
| column | 0.9758 | 0.9605 |
| irregular | 0.9837 | 0.9635 |
在𝜔=16时,filter(滤波器剪枝)、column(列剪枝)和irregular(不规则剪枝)的nat acc(自然正确率)和adv acc(对抗正确率)
分析:
在表2中,剪枝粒度越细的部分,最终剪枝结果就越贴合我们在给其设定的剪枝比例。值得一提的是,不规则剪枝应当归属于非结构剪枝,所以下面的分析是基于滤波器剪枝和列剪枝进行的。
从表2中可以看出,列剪枝相较于滤波器剪枝,压缩率更高。而在表3中,列剪枝的自然正确率和对抗正确率反而低于滤波器剪枝。这和我们在分析表1时得出的结论一致,即对抗训练需要更大的网络容量。这一结论并不因为剪枝方式的不同而发生转移,而是对抗训练的内在属性。
| before | prune | epoch1 | epoch2 | epoch3 | … | epoch40 | |
|---|---|---|---|---|---|---|---|
| nat acc | 0.9859 | 0.9859 | 0.98 | 0.9797 | 0.9721 | … | 0.9777 |
| adv acc | 0.9697 | 0.9712 | 0.9635 | 0.963 | 0.9476 | … | 0.9614 |
在𝜔=16时,使用filter(滤波器剪枝)的retrain阶段,训练过程中nat acc(自然正确率)和adv acc(对抗正确率)的变化。Before指训练刚开始,未对神经网络进行剪枝。Prune指刚对神经网络剪枝之后的正确率。在retrain阶段中,训练epoch数目为40,换句话说表格包含了整体的训练趋势。
分析:
表4和前文不同,该表旨在尝试解释retrain阶段的合理性。
从表中我们可以得知,在进行剪枝操作之后,自然正确率并为发生改变,而对抗正确率有小幅度的提高,这是由于剪枝操作删去模型中的部分参数,使得模型的泛化能力增强,进而提高了对抗正确率。
而在后续的重训练过程中,自然正确率和对抗正确率上下轻微波动,可见模型的性能在训练中变得更加稳定。
(2) 观察分析实验结果,思考在什么情况下结构化剪枝能很好地与对抗训练结合,什么情况下不能?
当我们将自然正确率和对抗正确率作为对抗训练的评价指标,压缩率作为结构化剪枝的评价指标。从 表1 中可以看出,当一个模型初始容量较大时,相比较初始容量不足的模型,更容易获得更好的自然正确率、对抗正确率和压缩率。
值得一提的是,如果我们在实验中将ω=1,面对容量如此小的模型,最终的结果是nat acc=11.35%, adv acc=11.35%,并且无论如何修改学习率都无法改变这样的结果。相比较下,表1 中ω=4时的模型,非但自然正确率和对抗正确率优于ω=1的模型,剪枝后的模型大小也更小,显然是符合上文的结论。当我们尝试将结构化剪枝和对抗训练结合时,我们所使用的模型容量有一定的下限要求。
(3) 分析结构化剪枝和对抗训练冲突的深层次原因在哪里,思考如何解决?
结构化剪枝和对抗训练的冲突深层次原因:网络容量。
在Towards deep learning models resistant to adversarial attacks. International Conference on Learning Representations、Theoretically principled trade-off between robustness and accuracy和Towards deep learning models resistant to adversarial attacks中均有提及为了可靠的抵抗强大的对抗攻击,网络需要的容量要比仅正确分类良性样本的容量更大。也就是说,对抗训练青睐于容量较大的网络。
总所周知,剪枝这一操作就是对网络容量的缩小。也就是说,剪枝的目标是容量较小的网络。结构化剪枝和对抗训练在此处产生了分歧,这也是结构化剪枝和对抗训练冲突的深层次原因。
-
如何解决:
-
将剪枝融入到训练目标中:同上文中提及的基于ADMM的训练方法,将剪枝目的融入到训练过程中。在训练过程中,神经网络的权重便自然而然的获得了对抗训练带来的鲁棒性和适合剪枝的特性。但是从上文的实验结果分析中可得,该方法没有完全消除其冲突,而是尽可能的将其淡化。
-
将训练目标融入剪枝过程中:
在CIFS: Improving Adversarial Robustness of CNNs via Channel-wise Importance-based Feature Selection[9]中,说明了对抗训练使得对抗通道激活和自然通道激活相对齐,进而产生了对齐两者激活进而提高其鲁棒性的想法。
那么对于剪枝来说,也可以利用相关的思想。通过比对对抗训练前后各个粒度的激活情况,来制定相关的剪枝方案,进而提高模型的鲁棒性。
(虽然只停留在初步猜想阶段,但可以预料到该方案并不能预设剪枝比例。)
-
参考文献
[1] Wang, H., Wang, Z., Liu, J., & Zeng, N. (2020). Structured Pruning for Deep Convolutional Neural Networks: A survey.
[2] Wang, Z., Dong, Y., Sun, Z., & Liu, Y. (2019). Adversarial robustness vs. model compression, or both?
[3] Ye, M., Ji, H., & Li, C. (2019). Hydra: Pruning adversarially robust neural networks.
[4] Wang, Z., Li, C., Liu, Y., & Rehg, J. M. (2021). CSTAR: Towards Compact and STructured Deep Neural Networks with Adversarial Robustness.
[5] Wang, Z., Wang, K., Liu, Y., & Zhang, T. (2021). Robust Tickets Can Transfer Better: Drawing More Transferable Subnetworks in Transfer Learning.
[6] Sinha, A., Namkoong, H., & Duchi, J. (2018). Towards deep learning models resistant to adversarial attacks. International Conference on Learning Representations.
[7] Qian, C., Yuille, A. L., & Soatto, S. (2019). Theoretically principled trade-off between robustness and accuracy.
[8] Gowal, S., Dvijotham, K., Stanforth, R., Duchi, J., & Stanforth, R. (2019). Towards deep learning models resistant to adversarial attacks.
[9] Huang, L., Liu, Y., Maaten, L., & Weinberger, K. Q. (2019). CIFS: Improving Adversarial Robustness of CNNs via Channel-wise Importance-based Feature Selection.

















 1803
1803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









