







1 稀疏
本人尝试过的稀疏算法有限,目前尝试过阈值稀疏、admm稀疏方式和简易pattern pruning,在此做一小结。
日后若有别的这方面尝试,会继续加。
稀疏的好处:减少存储,减少运算量,软硬件都可用。
- 网络层数多,结构复杂,往往有更多的冗余
- 不同场景下需求不一样。大数据集训练,小数据集测试可以带来更高的稀疏度
- 本身参数值就小,可能更容易有更高的稀疏度
- 针对不同网络层,采用不同的稀疏度
1.1 结构化稀疏
1) layer pruning
直接将某一层全部置零
2) channel pruning
某些通道全为零
3) intra-kernel pruning
某些行(列)全为零
pattern pruning
- 预先设置一些pattern作为mask,
- 针对weight的每个通道,选择与各pattern相乘之后,绝对值和最大的那个pattern
- 训练
1.2 非结构化稀疏
1) 阈值稀疏
简言之,就是将绝对值小的值置为零。
这里细分还可以分为 按层(per-layer) 和 按通道(per-channel)
- 随机初始化再稀疏有时候比pretrain后稀疏效果好,特别是稀疏度较高的情况下
2) admm稀疏
将稀疏问题,转化为了优化问题,使用admm方法解之,得到凸优化解法,具体看paper。

分三步:
第一步:得到pretrain模型
第二步admm_prune: 修改loss函数,加上正则化项,引入Z,U
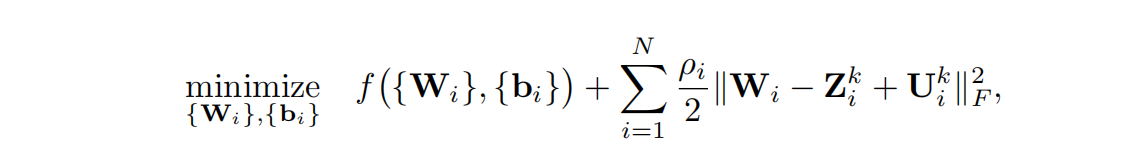
更新W,b

更新Z
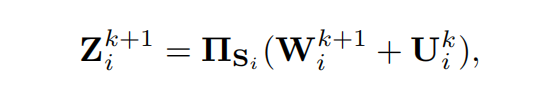
更新U
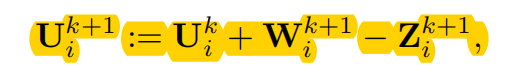
不断更新Z, U ,直到W 趋向于 Z或者正则化项收敛(Z趋于W稀疏后的结果, W趋于Z)
第三步retrain : 对W小的值置零,且对应位置保持为零,不再更新
- 调参:稀疏度,学习率,net_loss和admm_loss的比例














 148
148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









