




| 公司 | 应用场景 | 应用效果 |
|---|---|---|
| 蚂蚁集团 | 支付宝 “支小宝” 的政务问答和医疗问答 | 政务问答准确率提升到 91%,医疗问答垂直的指标解读准确率可达 90% 以上 |
| 搜索引擎的问答系统 | 当用户搜索时,系统不仅返回相关文本,还会从知识图谱中提取结构化信息,增强回答准确性 | |
| 阿里达摩院 | 知识增强 AIGC 系统 | 利用知识图谱为大模型提供背景知识,生成更准确、一致的内容,可扩展为支持多语言生成和个性化推荐 |
| eBay | 商品推荐系统 | 利用知识图谱存储商品属性,结合大模型生成个性化的推荐列表,提升推荐精准度 |
| 阿里云 | 基于 PolarDB + 通义千问 + LangChain 搭建 GraphRAG 系统 | 以股票知识图谱为例,通过图 + 向量联合搜索,增强问答准确性,减少大模型幻觉 |
| 武汉大学水工程科学研究院 | 水利领域知识问答 | 构建水利领域知识图谱,结合大语言模型搭建问答平台,提高答案准确性与可信度,增强回答可解释性 |
| 郑州工程技术学院 | 智能教学平台 | 通过知识图谱关联学科知识点,大模型提供实时辅导,生成个性化学习路径,提升教学精准度和学习效率 |

1、《核电运维数据知识图谱构建及其LLM应用》
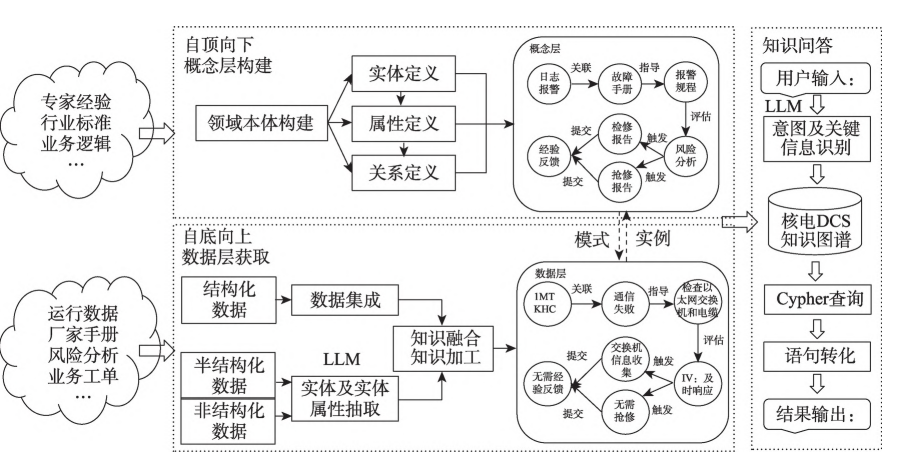
基于LLM和KG的智能问答
核心思想:知识图谱构建+LLM自主意图识别
该应用主要涵盖概念层设计、数据层获取和智能问答三个关键方面。
1.1 知识图谱的构建方法
1.1.1 本体及概念层设计。
概念层采用自顶向下的方式构建,以核电运维专家对 DCS 报警响应操作和过程控制的认识,同时参考行业标 准规范,构建核电 DCS 运维知识图谱本体库;结合电厂运维人员和专家经验,细化本体库覆盖的实体、关系以及属性类型,完成知识图谱本体及概念层框架设计。
知识图谱概念层主要包 括 实体(entity)、关系(relation)、属 性(attribute)等知识类的层次结构和层级关系定义,用来约束数据层的具体知识形式。按照知识图谱构建三要素原则,需要明确“实体-关系-实体属性”或“实体-关系-实体”三要素。
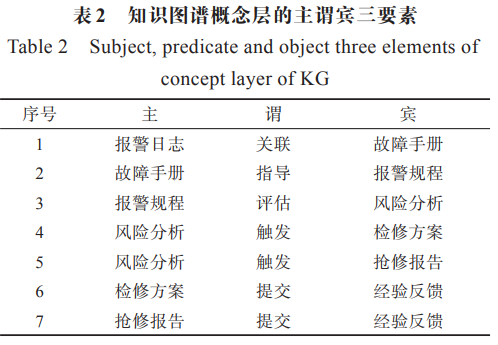
本文从电厂 DCS 运维需求出发, 在核电专家的指导下,结合专家经验、核电 DCS 报警 响应规程等,构建了报警日志、故障手册、报警规程、 风险分析、检修方案、抢修报告等 7类本体要素,以及 实体间、实体与属性间的关系。表1为核电 DCS概念 层知识图谱的实体及实体属性,

表2为概念层不同实体间主谓宾三要素,即实体与实体间的关系。
关于自顶向下设计请参考:
1.1.2 数据层获取
就是获取知识图谱需要的数据的意思。
数据层采用自底向上的方式构建,对 DCS 运维数据进行数据采集、数据清洗及数据预处理工作。搭建基于分步提示的大语言模型方法,开展核电 DCS 数据层知识抽取。采用文本匹配和语义相似计算方法进行数据集成、知识融合和知识加工,完成知识图谱数据层实体、实体属性以及实体之间关系匹配,构建领域知识图谱。
1.1.2.1 数据处理
数据预处理:
PDF数据中提取文本内容,处理页眉、页脚和水印等非正文内容,去除多余的空格、换行符,最终将其转化成标准格式文本数据。使用正则表达式提取字段。
数据清洗:
填补、删除、插补缺失数据,处理数据中的缺失值。删除或修正数据中的异常值或错误记录,删除重复的数据记录等步骤。
最终目标,将数据源,转换为知识图谱需要的标准的文本数据。
1.1.2.2 数据获取
知识图谱数据层是以事实三元组为单位,存储具体的数据信息。
一般表示为:
![]()
其中,G是表示知识图谱,E表示实体集合,实体e是知识图谱中最基本的组成元素,在图谱中用结点进行表示,R表示关系集合
,关系r是知识图谱中的边,表示不同实体间的联系。F表示事实集合
,每一个事实f又被定义为一个三元组
。其中,h表示头实体,r 表示关系,t 表示尾实体。
从领域数据源获取与概念层设计的实体及实体属性对应的数据信息,并以三元组的形式存储到知识图谱数据库中。
1.1.2.3 结构化和半结构化知识抽取
结构化数据:如风险分析表、工单数据。针对字段定义明确的结构化数据,经过预处理后,获得知识图谱概念层实体及属性对应字段的数据,经数据预处理后可直接集成作为知识图谱数据层信息。
半结构化数据:如报警日志,采用正则表达式匹配、词典匹配、模板匹配等基于规则的方式,抽取实体及属性信息。

非结构化数据:如故障手册。可以使用“基于大模型的知识抽取模型”,利用 Promptn 和少样本学习,将知识抽取的序列标记任务转化为大语言模型的文本生成任务。Prompt 允许用户以指令的方式指导和抽取故障信息[28] ,利用 LLM进行多次抽取来训练与优化Prompt,直到抽取效 果达到预期的性能水平[29] 。
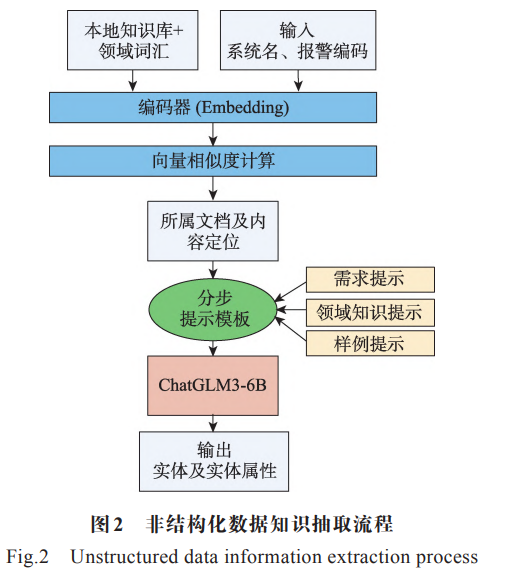
该流程以本地知识库为基础,通过向量匹配定位报警信息关联文档,最终实现关键实体属性抽取,具体步骤如下:
1)构建本地向量知识库
-
数据输入:预处理后的核电 DCS 故障手册、领域词汇(需确保数据格式规范、内容准确,排除冗余或错误信息)。
-
文本处理:将上述长文本按自然段落进行截断与分块(保证每个文本块语义完整,避免拆分逻辑连贯的内容)。
-
向量编码:采用 Embedding 技术对分块后的文本进行向量编码,将文本语义转化为可计算的向量形式。
-
知识库生成:整合所有编码后的文本向量,构建核电 DCS 领域专属的向量知识库。
2)报警异常信息匹配定位
-
输入信息:报警日志中提取的报警编码、异常描述等核心信息(需筛选关键信息,去除无关冗余字段)。
-
相似度计算:将输入的报警异常信息转化为向量后,与步骤 1 构建的向量知识库进行相似度计算(常用计算方法如余弦相似度、欧氏距离等)。
-
定位结果输出:根据相似度计算结果,确定报警异常信息在本地知识库中对应的所属文档,并精准定位该信息在文档中的具体位置(如段落序号、页码等)。
3)关键实体属性信息抽取
-
需求分析:结合核电 DCS 运维、故障排查等实际业务需求,明确需抽取的关键实体类型(如故障原因、处理措施、关联设备型号等)及对应属性。
-
Prompt 设计:根据确定的抽取需求,设计针对性的 Prompt 提示(需清晰定义抽取规则、格式要求,确保 AI 理解抽取目标)。
-
实体抽取:将步骤 2 定位到的文档内容与设计好的 Prompt 结合,输入至模型中,完成关键实体属性信息的抽取,输出结构化结果(如表格、JSON 等格式)。
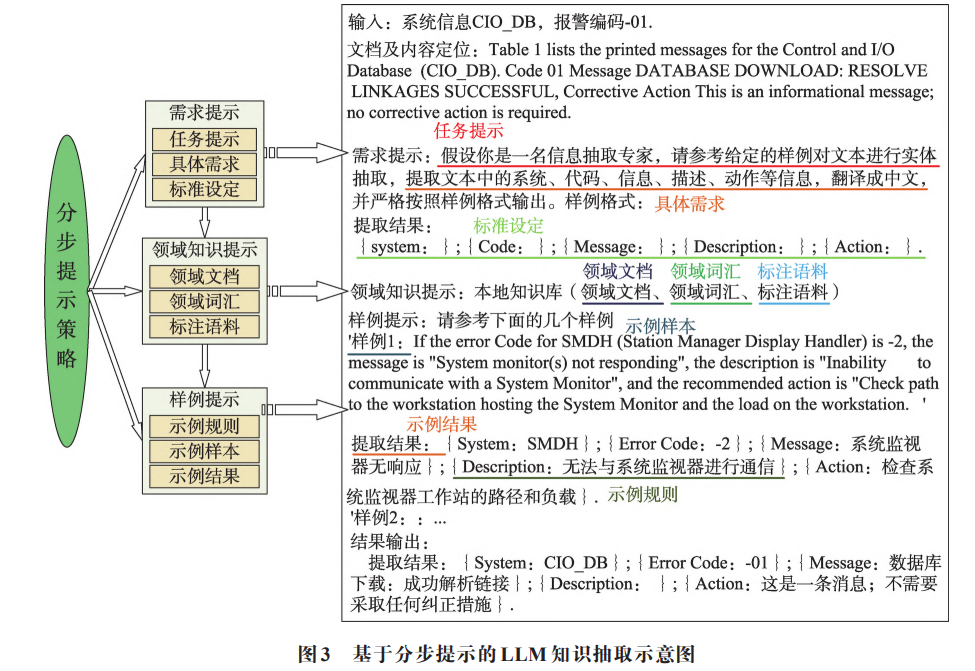
1.1.2.4 非结构化数据抽取的 Prompt 提示
Prompt 提示设计方面,采用分布提示:需求提示、领域知识提示、样例提示。
- 领域知识:是通过提供领域相关的背景知识和标注语料,帮助模型理解任务的领域特征和数据特点。
- 标注语料:展示如何从数据中识别和抽取实体,以便模型能够更好地理解和应用相关概念。
- 样例提示:给出具体示例进行指导,通过提供示例、逐步解释、对比分析,使模型逐步理解每个步骤的操作,提高模型对人物的分析和执行能力。
要求:
- 明确任务:旨在定义模型需要扮演的任务角色, 让模型明确用户的目标和期望。
- 罗列需求:列出具体的需求细节,确保用户清楚任务的具体要求。
- 设定标准:设定输出结果的格式和评估标准,以确保结果的一致性和可评估性。
1.1.2.5 知识融合与加工
知识融合与知识加工是指在知识图谱构建时,对新获得的知识进行整合以消除矛盾和歧义的过程[30] 。 本文通过对提取的同类别实体、实体属性进行文本相 似度计算,并对语义错误或同义描述的词进行标准 语义替换,完成知识融合;采用文本匹配进行知识加工,以形成一个大规模的知识体系。
本文采用自顶向下的构建思路,以预定义概念层为核心框架,逐步完成实体、属性及关系的映射与整合,最终形成完整知识图谱,具体步骤如下:
1)构建知识图谱概念层
- 构建方式:采用自顶向下策略,优先搭建知识图谱的顶层概念框架。
- 核心内容:提前定义知识图谱所需的全部关系类型,并将其规整至概念层中(具体关系类型可参考表 2),为后续实体与属性的匹配提供统一标准。
2)实体与属性匹配
- 数据输入:使用经过知识融合、知识加工处理后的实体数据及实体属性数据(确保数据准确性、一致性,消除冗余与冲突)。
- 匹配规则:将处理后的实体、实体属性数据,与概念层中预定义的 “实体类型”“实体属性规范” 进行一一对应匹配,明确每个实体所属的概念类别及符合规范的属性信息。
3)完成知识图谱全要素构建与整合
- 要素整合:基于步骤 2 的匹配结果,结合概念层中预定义的关系类型,关联对应实体、实体属性及实体间关系。
- 最终输出:整合所有实体、实体属性及关系信息,形成结构完整、逻辑一致的知识图谱。
1.2 智能问答系统构建
基于知识图谱的可视化智能问答。依托所构建的知识图谱,开展数据查询和可视化分析,采用大语言模型方法提取问题中关键实体信息; 利用 TF-IDF 特征提取器[26] 和朴素贝叶斯分类器[27] 明 确用户问题意图,基于知识图谱搜寻节点并将答案以自然语言形式返回至用户,完成报警响应对话问答。
用户意图识别是引入知识图谱最关键的一步,决定了查询(检索)的知识图谱实体的准确程度。
1.2.1 用户意图识别
因用户问题输入表达相同语境的中文句式因人 而异,如何识别用户意图和问句中的实体信息是实 现基于图谱智能问答的关键点。本文通过设计二次意图分类模型,对用户的意图进行判断,如图4。
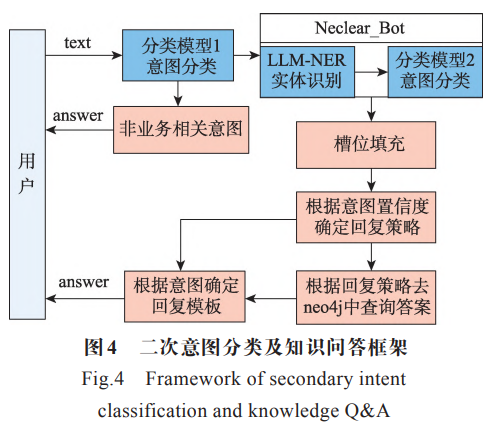
第一次意图和信息识别:结合电厂 DCS 运维人员的工作需求,从核电常见问答中收集了182条DCS相关的问答并进行意图分类。然后定义了 TF-IDF 特征提取器和朴素贝叶斯分类器的意图模型。再基于 JIEBA 分词对用户问句中的词组进行分割,并与实体特征词库进行相似度计算匹配,最终实现用户意图和问句实体的理解。
TF-IDF 是一种常用于文本特征提取的技术,它 用于衡量一个词对于文档的重要性。 TF 为词频,表 示词在用户问句中出现的频率,IDF 为逆文档频率, 表示词在整个语料库中的稀有程度。 TF_IDF 特征 提取器将文本数据转换为向量表示。
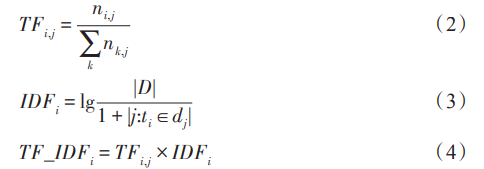

朴素贝叶斯被广泛用于文档分类中,它假设文 本的特征(单词、词组等)之间相互独立,然后基于训 练数据中的问句特征和问句意图分类标签计算每个 类别的条件概率,最后通过贝叶斯定理计算出用户 问句属于每个意图类别的概率,并选择概率最高的 类别作为预测结果,表示为:
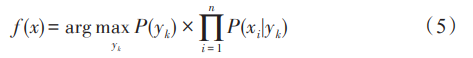

第二次意图查询:
以特征词构建的领域 AC-Tree,进行分类。领域 AC 树是一种基于 trie 树的数据结构,能够在单词文本扫描中匹配多个模式字符串。
具体操作:
1) 结合电厂运维人员经验,给每类问句意图设计关键特征词,得到关键词的类别词典;以特征词构建的领域 AC-tree进行关键词匹配,确定用户意图识别。最终, 将两次意图识别结果进行交集并确定回复策略。
2)结果查询:将提取的实体信息与用户意图联合构建Cypher 语言,并在Neo4j中执行查询操作,再将查询结果基于 Djanno框架 以自然语言形式返回给前端用户。
1.3 实验结果分析
1.3.1 实验结果指标
知识抽取指标:
精确率 P (precision):![]()
召回率 R (recall):![]()
F1值:![]()
其中,TP 表示模型正确识别为目标类别的实例数, FP 表示模型错误识别为目标类别的实例数,FN 表 示模型漏掉的目标类别的实例数。
1.3.2 知识图谱可视化应用
知识图谱涉及 7类 实体和 7种关系,包含了 36110个实体,形成了 36622 对三元组,并利用Neo4j 提供的可视化工具进行展示。
数据查询:知识图谱涉及 7类 实体和 7种关系,包含了 36110个实体,形成了 36622 对三元组,并利用 Neo4j 提供的可视化工具进行展示。
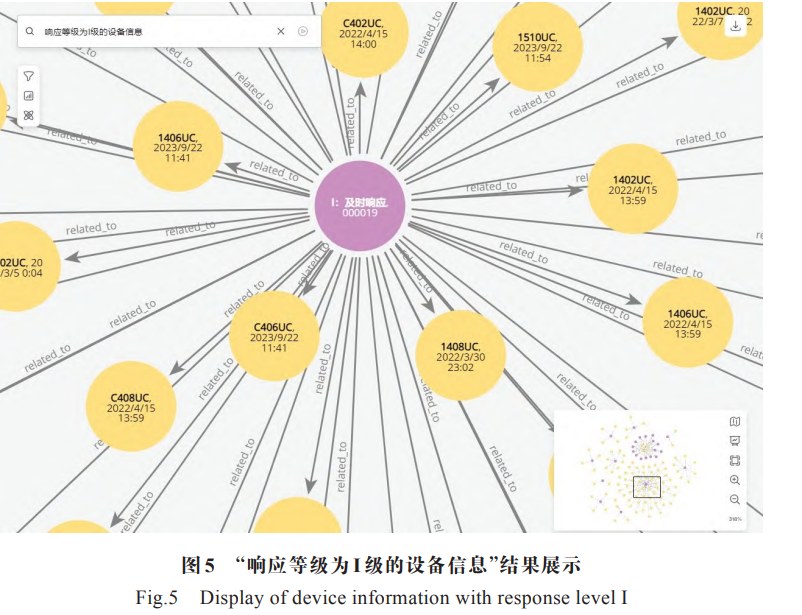
示例:


















 1357
1357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









