






阅读全文:Stata:平行趋势敏感性检验-honestdid
作者:王烨文 (天津工业大学)
邮箱:2230131505@tiangong.edu.cn
编者按:本文内容参考自下文,特此致谢!
Source:Robust inference in difference-in-differences and event study designs -Link-
- Title:平行趋势敏感性检验
- Keywords:平行趋势,敏感性检验,honestdid,相对偏离程度限制,平滑性限制
1. 引言
Kahn-Lang 和 Lang (2020) 指出,越来越多的研究者使用统计上不显著的处理前趋势检验来支持“平行趋势假设”。虽然处理前趋势检验对于验证平行趋势假设非常重要,但我们不能因为无法拒绝处理前符合平行趋势假设,就认为处理后也一定符合平行趋势假设 (这是谬误)。简单来说,无法拒绝原假设并不等于证实原假设。
Roth (2022) 进一步指出,处理前的平行趋势检验有效性较低,即使平行趋势假设不满足,也可能不会发现显著的处理前系数。此外,差分法 (DID) 依赖于处理前的平行趋势检验,这本身就存在问题,可能会恶化政策处理后的效应估计。简而言之,处理前的平行趋势检验对于 DID 而言,既不必要,也不充分。为此,Rambachan 和 Roth(2022)提出了平行趋势敏感性检验。
honestdid 命令实现了 Rambachan 和 Roth (2022) 提出的用于差分法 (DID) 和事件研究法的敏感性分析工具。本推文主要介绍这一命令的使用方法。Rambachan 和 Roth (2022) 提出的稳健推断方法认为,处理前的趋势可以帮助我们识别平行趋势假设的违反情况。他们提出了几种不同的方式来说明这一点:
-
相对偏离程度限制:这种方法主要是规定处理后平行趋势的偏离程度不能超过处理前的偏离程度。我们可以通过设定一个参数 M‾M 来限制处理后平行趋势的偏离程度,即处理后的偏离不会超过处理前最大偏离程度的 M‾M 倍。例如,M‾=1M=1 表示处理后平行趋势的偏离程度不会比处理前更严重,M‾=2M=2 表示处理后的偏离程度不会超过处理前最严重情况的两倍。
-
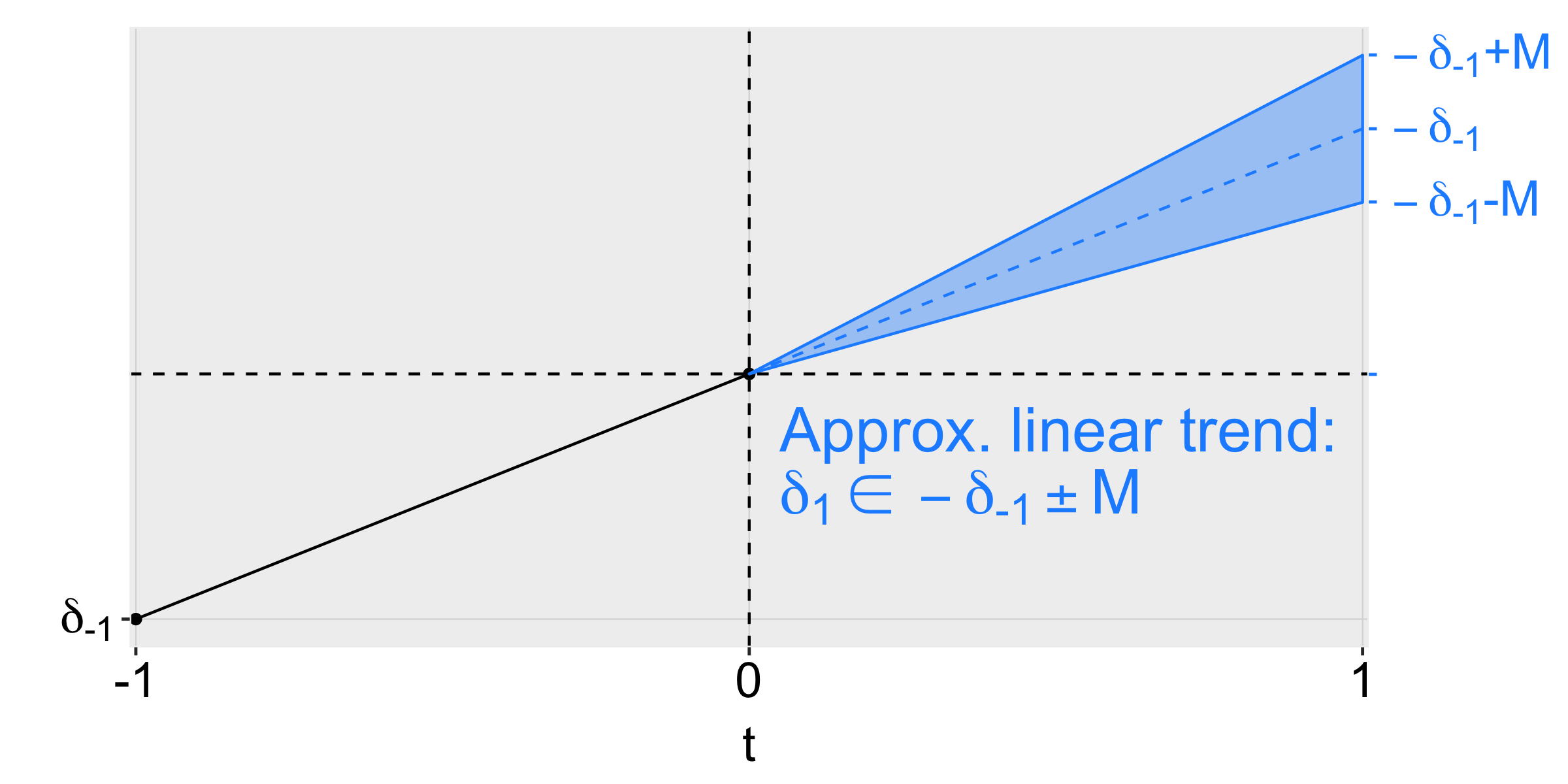
平滑性限制:这种方法主要限制处理后的偏离程度,使其不会显著偏离处理前的线性外推趋势。我们可以引入一个参数 MM,表示处理前趋势斜率在相邻两期之间的变化不会超过 MM。其中,M=0M=0 表示趋势是完全线性的,而 M>0M>0 表示趋势是非线性的。下图是一个时间维度为三期的示例:
- 其他限制:Rambachan 和 Roth (2022) 的框架还允许对趋势差异施加其他各种限制。不过,相关功能计划在未来版本中推出。
在上述类型的限制下,Rambachan 和 Roth (2022) 提供了一种方法来创建稳健的置信区间,这些置信区间可以至少在 95% 的情况下包含真实参数。也就是说,研究者可以在不同的假设下报告置信区间,例如处理后平行趋势被违反的严重程度 (通过不同的 M‾M 或 MM 值)。此外,还可以报告某个结论的“临界值”,即在效应仍然显著的情况下,M‾M 或 MM 的最大值。
2. 命令安装及案例介绍
作者使用来自 ACS 的公开数据来研究 Medicaid 扩展对保险覆盖率的影响。首先,我们加载相关的数据和命令。
. * 下载相应命令
. ssc install honestdid, replace
. ssc install coefplot, replace
. ssc install ftools, replace
. ssc install reghdfe, replace
. ssc install csdid, replace
. * 加载数据
. lxhuse ehec_data.dta, clear这份数据是一个州级别的面板数据集,包含了有关健康保险覆盖率和 Medicaid 扩展的信息。变量 dins 显示了州内低收入无子女成年人的健康保险覆盖率。变量 yexp2 表示某州在平价医疗法案 (Affordable Care Act) 下扩展 Medicaid 覆盖范围的年份,如果该州从未扩展则为缺失值。
为了简单起见,我们首先将重点放在单时点 DID 中的平行趋势敏感性检验上 (关于多时点差分的方法,见下文)。为此,我们将样本限制在 2015 年及之前,并删除在 2015 年开始实施政策的小部分州。这样,我们得到的是一个面板数据集,其中一些州在 2014 年首次接受政策处理,而其余州在整个样本期间内从未处理。然后,我们可以使用事件研究法来估计 Medicaid 扩展的效果,其中 D 表示某个州在 2014 年首次处理,否则为 0。
Yit=αi+λt+∑s≠20131[s=t]×Di×βs+uitYit=αi+λt+s=2013∑1[s=t]×Di×βs+uit
. * Keep years before 2016. Drop the 2016 cohort
. keep if (year < 2016) & (missing(yexp2) | (yexp2 != 2015))
. * Create a treatment dummy
. gen byte D = (yexp2 == 2014)
. gen `:type year' Dyear = cond(D, year, 2013)
. * Run the TWFE spec
. reghdfe dins b2013.Dyear, absorb(stfips year) cluster(stfips) noconstant
. local plotopts ytitle("Estimate and 95% Conf. Int.") title("Effect on dins")
. coefplot, vertical yline(0) ciopts(recast(rcap)) xlabel(,angle(45)) `plotopts'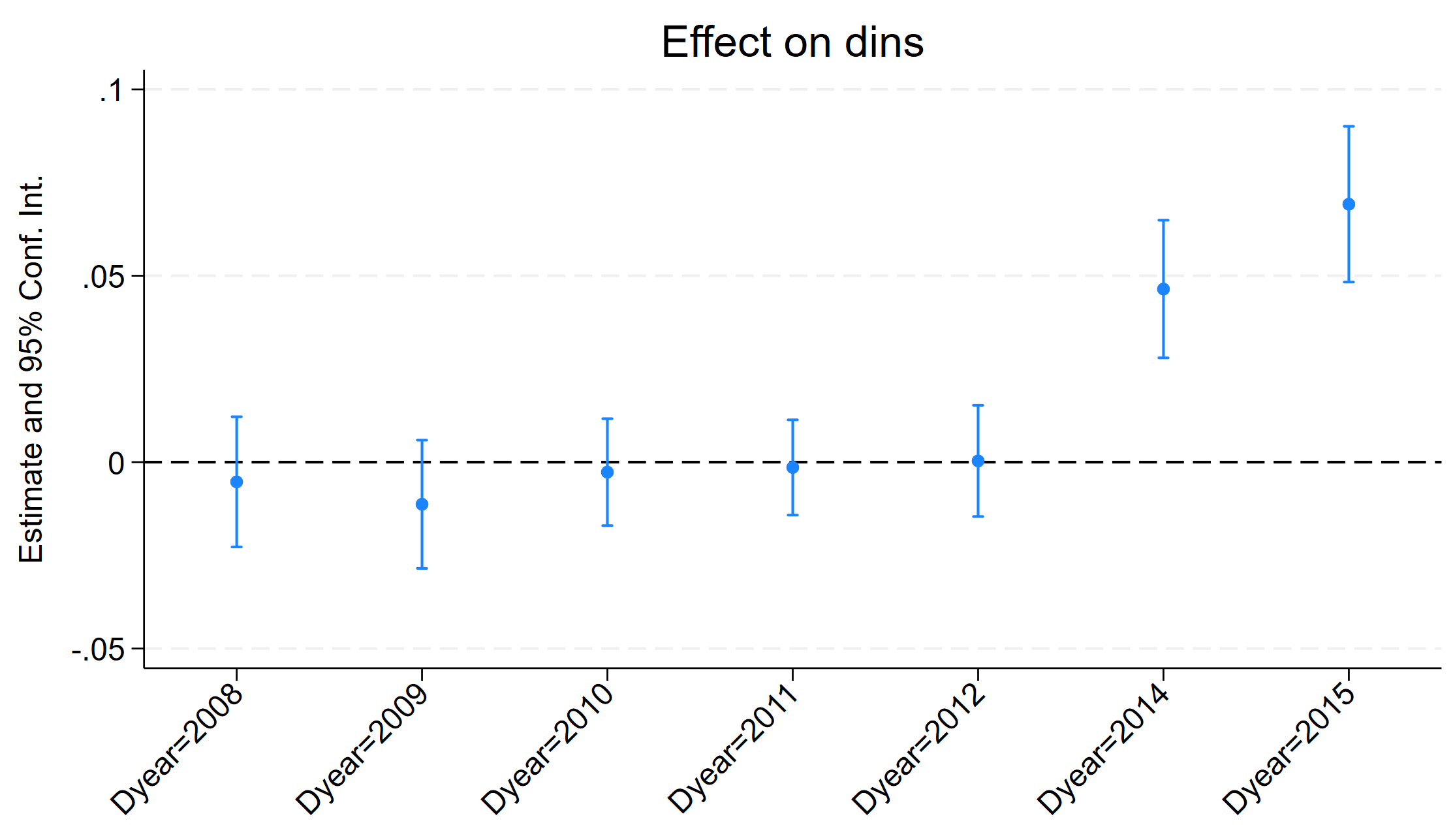

















 1715
1715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









