







📢作者: 小小明-代码实体
📢博客主页:https://blog.csdn.net/as604049322
📢欢迎点赞 👍 收藏 ⭐留言 📝 欢迎讨论!
昨天我们处理Word文档的自动编号,详见《Python解析Word文档的自动编号》
链接:https://xxmdmst.blog.csdn.net/article/details/139638262
今天我们处理一下Word文档的目录和文本框,例如:

如果我们按照传统方式读取,是无法读取目录和文本框的。
这时,我们只需要想办法目录和文本框中的P节点与普通P节点一起被读取即可。
查看其xml结构后知道,w:sdt是目录节点,文本框节点存在于p里面的v:textbox节点下。
可以写出如下代码:
from docx import Document
from docx.oxml import ns
from docx.text.paragraph import Paragraph
doc = Document('目录测试.docx')
ns.nsmap.update(doc.element.nsmap)
body = doc.element.body
paragraphs = []
for p in body.xpath('w:p | w:sdt/w:sdtContent/w:p | w:p//v:textbox//w:p'):
paragraphs.append(Paragraph(p, body))
注意上面的代码使用Paragraph(p, body)封装是为了让paragraphs的结果类型与doc.paragraphs保存一致,可以看到其源码为:
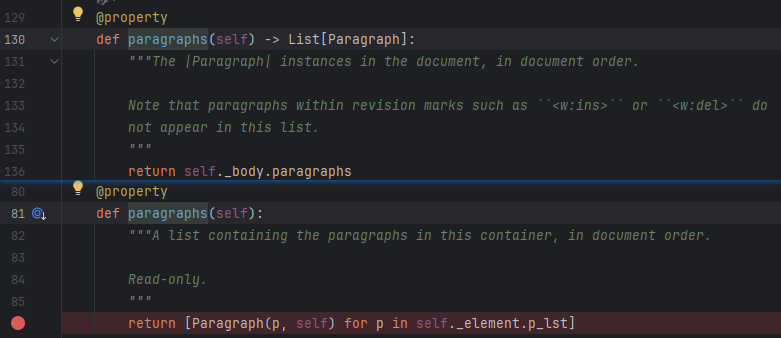
如果不需要Paragraph的特殊功能,仅做基本的数据读取,也可以不封装。
然后就能将普通段落和目录内的段落以及文本框内的段落,都按顺序读取:
for paragraph in paragraphs:
print(paragraph.text)
如果这时,我们需要将自动编号也读取进来,需要注意文本框内的段落是单独计数的。
最后我们将该功能整合到上次的代码中:
import logging
import re
import traceback
from functools import lru_cache
from docx import Document, ImagePart
from docx.oxml import register_element_cls, CT_DecimalNumber, CT_String, CT_Tbl
from docx.oxml.ns import nsmap
from docx.oxml.simpletypes import ST_DecimalNumber
from docx.oxml.xmlchemy import BaseOxmlElement, RequiredAttribute, ZeroOrMore, OneAndOnlyOne, ZeroOrOne
from docx.table import Table
from docx.text.paragraph import Paragraph
class CT_Lvl(BaseOxmlElement):
ilvl = RequiredAttribute("w:ilvl", ST_DecimalNumber)
start = ZeroOrOne("w:start")
numFmt = ZeroOrOne("w:numFmt")
lvlText = OneAndOnlyOne("w:lvlText")
suff = ZeroOrOne("w:suff")
def get_style(self):
style = {
"start": self.start.val if self.start is not None else 1,
"numFmt": self.numFmt.val if self.numFmt is not None else "decimal",
"lvlText": self.lvlText.val
}
if self.suff is not None:
style["suff"] = self.suff.val
return style
class CT_AbstractNum(BaseOxmlElement):
abstractNumId = RequiredAttribute("w:abstractNumId", ST_DecimalNumber)
lvl = ZeroOrMore("w:lvl")
class CT_Numbering(BaseOxmlElement):
num = ZeroOrMore("w:num", successors=("w:numIdMacAtCleanup",))
abstractNum = ZeroOrMore("w:abstractNum", successors=("w:numIdMacAtCleanup",))
register_element_cls("w:numbering", CT_Numbering)
register_element_cls("w:abstractNum", CT_AbstractNum)
register_element_cls("w:lvl", CT_Lvl)
register_element_cls("w:start", CT_DecimalNumber)
register_element_cls("w:numFmt", CT_String)
register_element_cls("w:lvlText", CT_String)
register_element_cls("w:suff", CT_String)
class WithNumberDocxReader:
ideographTraditional = "甲乙丙丁戊己庚辛壬癸"
ideographZodiac = "子丑寅卯辰巳午未申酉戌亥"
def __init__(self, docx, gap_text="\t", include_table_content=True, style_optimization=False, debug=False):
self.preview_cache = {
}
self.debug = debug
self.style_optimization = style_optimization
self.heading_level_numpr = {
}
self.style_level = {
}
self.style2numId = {
}
self.level2numpr = {
}
self.parts = []
self.docx = Document(docx)
self.include_table_content = include_table_content
nsmap.update(self.docx.element.nsmap)
self.numId2style = {
}
self.get_style_data()
self.key2level = {
}
self.gap_text = gap_text
self.cnt = {
}
self.cache = {
}
self.result = []
def replace_number2text(self):
body = self.docx.element.body
for p in body.xpath('w:p | w:sdt/w:sdtContent/w:p | w:p//v:textbox//w:p | w:tbl//w:p'):
paragraph = Paragraph(p, body)
text = paragraph.text.strip()
if not text:
continue
number_text = self.get_number_text(paragraph)
line = number_text + text
paragraph.text = line
paragraph.paragraph_format.element.pPr._remove_numPr()
for style in self.docx.part.styles.element.style_lst:
if style.pPr is not None and style.pPr.numPr is not None:
style.pPr._remove_numPr()
def save(self, file):
self.docx.save(file)
@property
def texts(self):
if self.result:
return self.result.copy()
self.clear()
for paragraph in self.tablesAndParagraphs:
if isinstance(paragraph, Table):
for row in paragraph.rows:
line = "\t".join([cell.text.strip() for cell in row.cells])
if line:
self.result.append(line)
else:
number_text = self.get_number_text(paragraph)
line = number_text + paragraph.text.strip()
if line:
self.result.append(line)
if self.debug:
print("---------------debug-------------------")
return self.result.copy()
def clear(self):
self.result.clear()
self.cnt 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3204
3204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











