






关于DDPM的各种理论,网上已经有很多的文章了。之所以还要写这篇文章,主要还是方便自己梳理和复习。也为了后续的扩散相关文章做一下铺垫。如果你还在学习什么是DDPM,只看这篇文章也足够了。
最佳排版请前往:深度学习指南
【原论文】: Denoising Diffusion Probabilistic Models
原论文从ELBO开始推导,其中扩散过程的推导技巧性太强,一般人很难想到用这样的方式。具体推理,可以参考下面这篇文章。
深入浅出扩散模型(Diffusion Model)系列:基石DDPM(人人都能看懂的数学原理篇) - 知乎 (zhihu.com)
如果对里面关于变分推断、ELBO有疑问,可以参考我之前的文章:
变分推断(Variational Inference,)与证据下界(Evidence Lower Bound, ELBO) - 知乎 (zhihu.com)
背景
生成模型的本质都是为了拟合真实数据对应的分布
P
(
x
)
P(x)
P(x)。DDPM跟VAE一样,都是想基于隐变量,来做分布的“映射”,具体可以表示为
P
(
x
)
=
∫
p
(
z
)
p
(
x
∣
z
)
d
z
P(x) = \int p(z)p(x|z) dz
P(x)=∫p(z)p(x∣z)dz
其中
z
z
z就是所谓的隐变量。那DDPM是如何达到这样的目的呢?
跟GAN一样,DDPM做的事情也有跟作假者和鉴别者一样生动的比喻。我们可以将DDPM做的事情可以概括为,拆楼和建楼。
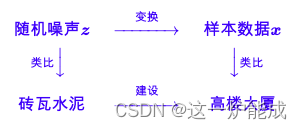
那拆楼和建楼分别是什么意思呢?拆楼在这里,具体是指往当前样本
x
x
x加入噪声
z
z
z,这里的拆,也不是一步就全是拆卸完毕,我们希望共有
T
T
T步( DDPM:
T
=
1000
T=1000
T=1000),来完成这件事,即
x
0
−
x
1
−
x
2
−
.
.
.
.
−
x
t
−
x
t
+
1
−
.
.
.
.
.
−
x
T
x_0 -x_1-x_2-....-x_t-x_{t+1}-.....-x_T
x0−x1−x2−....−xt−xt+1−.....−xT
跟现实拆楼一样,我们希望将高楼大厦,拆干净,即我们希望到了
x
T
x_T
xT步,图像已经基本变成了噪声,比如

建楼呢,则与之相反,DDPM希望从噪声中,一步一步建造一个样本出来(高楼大厦)。即
x
T
−
x
T
−
1
−
.
.
.
.
−
x
t
−
x
t
−
1
−
.
.
.
.
.
−
x
0
x_T -x_{T-1}-....-x_t-x_{t-1}-.....-x_0
xT−xT−1−....−xt−xt−1−.....−x0
所以建楼也就是我们的生成了。
建楼与拆楼
基于上述的出发点,我们希望模型能够学习到
p
(
x
t
−
1
∣
x
t
)
p(x_{t-1}|x_t)
p(xt−1∣xt)所属的分布,然后采样一个
x
t
−
1
x_{t-1}
xt−1出来,然后再预测
p
(
x
t
−
2
∣
x
t
−
1
)
p(x_{t-2}|x_{t-1})
p(xt−2∣xt−1)所属分布,采样一个
x
t
−
2
x_{t-2}
xt−2,循环往复直至得到样本
x
0
x_0
x0。因此,基于这样的想法,让我们根据贝叶斯定理来一步一步推导,是否可以得到原论文的结论。首先,根据贝叶斯公式,我们可以得到
p
(
x
t
−
1
∣
x
t
)
=
p
(
x
t
−
1
)
p
(
x
t
∣
x
t
−
1
)
p
(
x
t
)
p(x_{t-1}|x_t) = \frac{p(x_{t-1})p(x_t|x_{t-1})}{p(x_t)}
p(xt−1∣xt)=p(xt)p(xt−1)p(xt∣xt−1)
单看这个公式,我们计算不出什么,但不要忘了,不管是
x
t
−
1
x_{t-1}
xt−1还是
x
t
x_{t}
xt,都由
x
0
x_0
x0得来的,因此需要将这个公式稍微变换一下
p
(
x
t
−
1
∣
x
t
,
x
0
)
=
p
(
x
t
−
1
∣
x
0
)
p
(
x
t
∣
x
t
−
1
,
x
0
)
p
(
x
t
∣
x
0
)
=
p
(
x
t
−
1
∣
x
0
)
p
(
x
t
∣
x
t
−
1
)
p
(
x
t
∣
x
0
)
p(x_{t-1}|x_t,x_0) = \frac{p(x_{t-1}|x_0)p(x_t|x_{t-1},x_0)}{p(x_t|x_0)} = \frac{p(x_{t-1}|x_0)p(x_t|x_{t-1})}{p(x_t|x_0)}
p(xt−1∣xt,x0)=p(xt∣x0)p(xt−1∣x0)p(xt∣xt−1,x0)=p(xt∣x0)p(xt−1∣x0)p(xt∣xt−1)
可能你会有点懵,为什么可以直接变换成这样?不着急,我理解你的疑惑,让我们推导一下。
p
(
x
t
−
1
∣
x
t
,
x
0
)
=
p
(
x
t
−
1
,
x
t
,
x
0
)
p
(
x
t
,
x
0
)
=
p
(
x
t
−
1
,
x
0
)
p
(
x
t
∣
x
t
−
1
,
x
0
)
p
(
x
t
,
x
0
)
=
p
(
x
t
−
1
∣
x
0
)
p
(
x
0
)
p
(
x
t
∣
x
t
−
1
,
x
0
)
p
(
x
t
∣
x
0
)
p
(
x
0
)
=
p
(
x
t
−
1
∣
x
0
)
p
(
x
t
∣
x
t
−
1
,
x
0
)
p
(
x
t
∣
x
0
)
=
p
(
x
t
−
1
∣
x
0
)
p
(
x
t
∣
x
t
−
1
)
p
(
x
t
∣
x
0
)
(5)
\begin{align*} p(x_{t-1}|x_t,x_0) &= \frac{p(x_{t-1},x_t,x_0)}{p(x_t,x_0)}\\ &= \frac{p(x_{t-1},x_0)p(x_t|x_{t-1},x_0)}{p(x_t,x_0)}\\ &= \frac{p(x_{t-1}|x_0)p(x_0)p(x_t|x_{t-1},x_0)}{p(x_t|x_0)p(x_0)} \\ &= \frac{p(x_{t-1}|x_0)p(x_t|x_{t-1},x_0)}{p(x_t|x_0)} \\ &= \frac{p(x_{t-1}|x_0)p(x_t|x_{t-1})}{p(x_t|x_0)} \end{align*} \tag{5}
p(xt−1∣xt,x0)=p(xt,x0)p(xt−1,xt,x0)=p(xt,x0)p(xt−1,x0)p(xt∣xt−1,x0)=p(xt∣x0)p(x0)p(xt−1∣x0)p(x0)p(xt∣xt−1,x0)=p(xt∣x0)p(xt−1∣x0)p(xt∣xt−1,x0)=p(xt∣x0)p(xt−1∣x0)p(xt∣xt−1)(5)
为什么最后一个等号成立?为了解释这个原因,我们需要先回到“拆楼”的步骤。DDPM将拆楼(加噪)的行为,定义为
x
t
=
α
t
x
t
−
1
+
β
t
ϵ
t
x_t = \sqrt{\alpha_t}x_{t-1} + \sqrt{\beta_t} \epsilon_t
xt=αtxt−1+βtϵt,其中
α
t
=
1
−
β
t
\alpha_t = 1- \beta_t
αt=1−βt 且要满足随着t增大,
β
t
\beta_t
βt也要增大。至于为什么要这样定义,且为什么要满足$ \alpha_t = 1- \beta_t$ ,我们下面再说。
基于这个加噪公式,我们可以将这个行为,扩展到
x
0
x_0
x0
x
t
=
α
t
x
t
−
1
+
β
t
ϵ
t
=
α
t
(
α
t
−
1
x
t
−
2
+
β
t
−
1
ϵ
t
−
1
)
+
β
t
ϵ
t
.
.
.
.
.
.
=
α
t
α
t
−
1
.
.
.
α
1
x
0
+
β
t
ϵ
t
+
α
t
β
t
−
1
ϵ
t
−
1
+
.
.
.
+
α
t
α
t
−
1
.
.
.
α
2
β
1
ϵ
1
\begin{aligned} x_t &= \sqrt{\alpha_t}x_{t-1} + \sqrt{\beta_t} \epsilon_t \\ &= \sqrt{\alpha_t}(\sqrt{\alpha_{t-1}}x_{t-2}+\sqrt{\beta_{t-1}}\epsilon_{t-1}) + \sqrt{\beta_t} \epsilon_t\\ ......\\ &=\sqrt{\alpha_t}\sqrt{\alpha_{t-1}}...\sqrt{\alpha_{1}}x_0 + \sqrt{\beta_t} \epsilon_t + \sqrt{\alpha_t}\sqrt{\beta_{t-1}} \epsilon_{t-1} + ...+ \sqrt{\alpha_t}\sqrt{\alpha_{t-1}}...\sqrt{\alpha_2}\sqrt{\beta_{1}} \epsilon_{1} \end{aligned}
xt......=αtxt−1+βtϵt=αt(αt−1xt−2+βt−1ϵt−1)+βtϵt=αtαt−1...α1x0+βtϵt+αtβt−1ϵt−1+...+αtαt−1...α2β1ϵ1
其中
ϵ
i
∈
N
(
0
,
1
)
\epsilon_i \in \mathcal{N}(0,1)
ϵi∈N(0,1)。因为正太分布的叠加性,从第二项开始直至最后一项,加起来还是服从正态分布且方差为
β
t
+
α
t
β
t
−
1
+
.
.
.
+
α
t
α
t
−
1
.
.
.
α
2
β
1
\beta_{t} + \alpha_t\beta_{t-1} + ... +\alpha_t\alpha_{t-1}...\alpha_{2}\beta_{1}
βt+αtβt−1+...+αtαt−1...α2β1。因为
α
t
=
1
−
β
t
\alpha_t = 1- \beta_t
αt=1−βt,基于这个条件,我们可以得到
α
t
α
t
−
1
.
.
.
α
2
α
1
+
β
t
+
α
t
β
t
−
1
+
.
.
.
+
α
t
α
t
−
1
.
.
.
α
2
β
1
=
1
\alpha_t\alpha_{t-1}...\alpha_{2}\alpha_{1} + \beta_{t} + \alpha_t\beta_{t-1} + ... +\alpha_t\alpha_{t-1}...\alpha_{2}\beta_{1} = 1
αtαt−1...α2α1+βt+αtβt−1+...+αtαt−1...α2β1=1
所以
x
t
=
α
ˉ
t
x
0
+
1
−
α
ˉ
t
ϵ
ˉ
t
x_t = \sqrt{\bar{\alpha}_t}x_{0} + \sqrt{1-\bar{\alpha}_t} \bar{\epsilon}_t
xt=αˉtx0+1−αˉtϵˉt
其中
α
ˉ
t
=
α
t
α
t
−
1
.
.
.
.
α
1
\bar{\alpha}_t = \alpha_t\alpha_{t-1}....\alpha_1
αˉt=αtαt−1....α1,这样我们就得到了
x
0
x_0
x0到任意
x
t
x_t
xt的公式。这个公式的意义是重大的,因为这意味着拆楼,我们不需要一步一步的拆了,我们仅需一次采样就能从
x
0
x_0
x0得到
x
t
x_t
xt! 这就是为什么,DDPM要将加噪的行为定义为
x
t
=
α
t
x
t
−
1
+
β
t
ϵ
t
x_t = \sqrt{\alpha_t}x_{t-1} + \sqrt{\beta_t} \epsilon_t
xt=αtxt−1+βtϵt,且要满足
α
t
=
1
−
β
t
\alpha_t = 1- \beta_t
αt=1−βt的原因了。原论文的设置:
β
1
=
1
0
−
4
\beta_1=10^{-4}
β1=10−4 ,
β
T
=
0.02
\beta_T=0.02
βT=0.02, 即 torch.**linspace**(0.0001, 0.02, T)
理解了拆楼的过程,现在我们可以回到刚才建楼的流程里了。现在再回头看公式5最后一个等号,应该已经可以明白为什么在DDPM里面
p
(
x
t
∣
x
t
−
1
,
x
0
)
=
p
(
x
t
∣
x
t
−
1
)
p(x_t|x_{t-1},x_0) =p(x_t|x_{t-1})
p(xt∣xt−1,x0)=p(xt∣xt−1)了吧? 因为
x
t
−
1
x_{t-1}
xt−1是由
x
0
x_0
x0得到的,
x
t
−
1
x_{t-1}
xt−1成立的同时,也已经涵盖了
x
0
x_0
x0成立了。
p
(
x
t
−
1
∣
x
t
,
x
0
)
=
p
(
x
t
−
1
∣
x
0
)
p
(
x
t
∣
x
t
−
1
)
p
(
x
t
∣
x
0
)
p(x_{t-1}|x_t,x_0) = \frac{p(x_{t-1}|x_0)p(x_t|x_{t-1})}{p(x_t|x_0)}
p(xt−1∣xt,x0)=p(xt∣x0)p(xt−1∣x0)p(xt∣xt−1)
我们仔细观察这个公式,发现不管是分子还是分母,我们都可以写出他们的概率分布密度。因为他们都服从正态分布
x
t
=
α
ˉ
t
x
0
+
1
−
α
ˉ
t
ϵ
ˉ
t
,
x
t
∽
N
(
α
ˉ
t
x
0
,
1
−
α
ˉ
t
)
x
t
−
1
=
α
ˉ
t
−
1
x
0
+
1
−
α
ˉ
t
−
1
ϵ
ˉ
t
−
1
,
x
t
−
1
∽
N
(
α
ˉ
t
−
1
x
0
,
1
−
α
ˉ
t
−
1
)
x
t
=
α
t
x
t
−
1
+
1
−
α
t
ϵ
t
,
x
t
∽
N
(
α
t
x
t
−
1
,
1
−
α
t
)
\begin{aligned} x_t &= \sqrt{\bar{\alpha}_t}x_{0} + \sqrt{1-\bar{\alpha}_t} \bar{\epsilon}_t , x_t \backsim \mathcal{N}(\sqrt{\bar{\alpha}_t}x_{0}, 1-\bar{\alpha}_t) \\ x_{t-1} &= \sqrt{\bar{\alpha}_{t-1}}x_{0} + \sqrt{1-\bar{\alpha}_{t-1}} \bar{\epsilon}_{t-1} , x_{t-1} \backsim \mathcal{N}(\sqrt{\bar{\alpha}_{t-1}}x_{0}, 1-\bar{\alpha}_{t-1}) \\ x_t & = \sqrt{\alpha_t}x_{t-1} + \sqrt{1-\alpha_t} \epsilon_t , x_t \backsim \mathcal{N}(\sqrt{\alpha}_tx_{t-1}, 1-\alpha_t) \end{aligned}
xtxt−1xt=αˉtx0+1−αˉtϵˉt,xt∽N(αˉtx0,1−αˉt)=αˉt−1x0+1−αˉt−1ϵˉt−1,xt−1∽N(αˉt−1x0,1−αˉt−1)=αtxt−1+1−αtϵt,xt∽N(αtxt−1,1−αt)
所以我们可以得到
p
(
x
t
−
1
∣
x
t
,
x
0
)
=
1
2
π
1
−
α
ˉ
t
−
1
exp
−
(
x
t
−
1
−
α
ˉ
t
−
1
x
0
)
2
2
(
1
−
α
ˉ
t
−
1
)
∗
1
2
π
1
−
α
t
exp
−
(
x
t
−
α
t
x
t
−
1
)
2
2
(
1
−
α
t
)
1
2
π
1
−
α
ˉ
t
exp
−
(
x
t
−
α
ˉ
t
x
0
)
2
2
(
1
−
α
ˉ
t
)
p(x_{t-1}|x_t,x_0) = \frac{\frac{1}{\sqrt{2\pi}\sqrt{1-\bar{\alpha}_{t-1}}}\exp^{-\frac{(x_{t-1}-\sqrt{\bar{\alpha}_{t-1}}x_0)^2}{2(1-\bar{\alpha}_{t-1})}}* \frac{1}{\sqrt{2\pi}\sqrt{1-\alpha_t}}\exp^{-\frac{(x_t-\sqrt{\alpha_t}x_{t-1})^2}{2(1-\alpha_t)}}}{\frac{1}{\sqrt{2\pi}\sqrt{1-\bar{\alpha}_t}}\exp^{-\frac{(x_t-\sqrt{\bar{\alpha}_t}x_0)^2}{2(1-\bar{\alpha}_t)}}}
p(xt−1∣xt,x0)=2π1−αˉt1exp−2(1−αˉt)(xt−αˉtx0)22π1−αˉt−11exp−2(1−αˉt−1)(xt−1−αˉt−1x0)2∗2π1−αt1exp−2(1−αt)(xt−αtxt−1)2
很遗憾,这里没有什么便捷计算的方式,只能硬计算。写latex公式实在麻烦,就不一一列举了。简单说一下,拆开后,
x
t
x_t
xt,
x
t
−
1
x_{t-1}
xt−1,
x
0
x_0
x0满足平方差公式,即
(
a
−
b
−
c
)
2
=
a
2
−
2
a
b
−
2
a
c
+
b
2
+
2
b
c
+
c
2
(a-b-c)^2= a^2 -2ab -2ac +b^2 +2bc + c^2
(a−b−c)2=a2−2ab−2ac+b2+2bc+c2,最终可以得到
p
(
x
t
−
1
∣
x
t
,
x
0
)
p(x_{t-1}|x_t,x_0)
p(xt−1∣xt,x0)的对应正态分布的均值和方差
p
(
x
t
−
1
∣
x
t
,
x
0
)
∽
N
(
α
t
(
1
−
α
ˉ
t
−
1
)
1
−
α
ˉ
t
x
t
+
α
ˉ
t
−
1
(
1
−
α
t
)
1
−
α
ˉ
t
x
0
,
(
1
−
α
t
)
(
1
−
α
ˉ
t
−
1
)
1
−
α
ˉ
t
)
p(x_{t-1}|x_t,x_0) \backsim \mathcal{N}(\frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t}x_t+\frac{\sqrt{\bar{\alpha}_{t-1}}(1-\alpha_t)}{1-\bar{\alpha}_t}x_0 , \frac{(1-\alpha_t)(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t})
p(xt−1∣xt,x0)∽N(1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1(1−αt)x0,1−αˉt(1−αt)(1−αˉt−1))
得到
p
(
x
t
−
1
∣
x
t
)
p(x_{t-1}|x_t)
p(xt−1∣xt)的概率密度函数,**这意味着我们每次一步降噪,都可以从当前的概率密度函数里采样得到!**因为公式8,我们还可以对这个分布的均值,做进一步推导,可以得到。
α
t
(
1
−
α
ˉ
t
−
1
)
1
−
α
ˉ
t
x
t
+
α
ˉ
t
−
1
(
1
−
α
t
)
1
−
α
ˉ
t
x
0
=
α
t
(
1
−
α
ˉ
t
−
1
)
x
t
+
α
ˉ
t
−
1
(
1
−
α
t
)
∗
x
t
−
1
−
α
ˉ
t
ϵ
ˉ
t
α
ˉ
t
1
−
α
ˉ
t
=
1
α
ˉ
t
∗
α
t
(
1
−
α
ˉ
t
−
1
)
x
t
+
(
1
−
α
t
)
x
t
−
β
t
1
−
α
ˉ
t
ϵ
ˉ
t
1
−
α
ˉ
t
=
1
α
ˉ
t
(
x
t
−
β
t
1
−
α
ˉ
t
ϵ
ˉ
t
)
(12)
\begin{aligned} \frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t}x_t+\frac{\sqrt{\bar{\alpha}_{t-1}}(1-\alpha_t)}{1-\bar{\alpha}_t}x_0 &= \frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})x_t + \sqrt{\bar{\alpha}_{t-1}}(1-\alpha_t) * \frac{x_t - \sqrt{1-\bar{\alpha}_t}\bar{\epsilon}_t}{\sqrt{\bar{\alpha}_t}}}{1-\bar{\alpha}_t} \\ &= \frac{1}{\sqrt{\bar{\alpha}_t}} * \frac{\alpha_t(1-\bar{\alpha}_{t-1})x_t + (1-\alpha_t)x_t - \beta_t\sqrt{1-\bar{\alpha}_t}\bar{\epsilon}_t}{1-\bar{\alpha}_t} \\ &= \frac{1}{\sqrt{\bar{\alpha}_t}} (x_t -\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}\bar{\epsilon}_t) \end{aligned} \tag{12}
1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1(1−αt)x0=1−αˉtαt(1−αˉt−1)xt+αˉt−1(1−αt)∗αˉtxt−1−αˉtϵˉt=αˉt1∗1−αˉtαt(1−αˉt−1)xt+(1−αt)xt−βt1−αˉtϵˉt=αˉt1(xt−1−αˉtβtϵˉt)(12)
到这里,我们终于得到了跟原论文一摸一样的结果!那这个历经千辛万苦得到的结论,怎么应用到实践呢?
我们知道上述的结论是结合加噪过程得到,因此在当前步骤 t t t,我们模型得到的 x t − 1 x_{t-1} xt−1所属的分布,理论应该要逼近公式12所示的正态分布。
因此在训练的时候,我们的模型应该要生成一个噪声 ϵ θ \epsilon_\theta ϵθ,然后这个噪声要在训练过程逼近 ϵ ˉ t \bar{\epsilon}_t ϵˉt。如何逼近?当然是用基于损失函数训练啦!在生成样本的时候,我们仅需不断的基于当前 x t x_t xt,从公式12所属分布里采样,得到 x t − 1 x_{t-1} xt−1,直至得到 x 0 x_0 x0。
重参数
上述还遗留了两个问题:一:**采样怎么采?**二:我们是想要在加噪(扩散)过程,采样一个噪声,然后在去噪过程中去预测这个噪声,使得模型在预测噪声的过程中习得真实图片的分布。但是实际上,如果是从一个带有参数: u θ u_\theta uθ, σ θ \sigma_\theta σθ 的分布里采样出一个噪声,梯度是无法传递给 u θ u_\theta uθ, σ θ \sigma_\theta σθ的。
无论是采样还是梯度传播问题,都是一个很麻烦的事情,但是因为是高斯分布,事情变得简单了。解决的思路就是,将“从带参数的不确定的分布中采样”转变为“从确定性的分布里采样”,具体来说 N ( u θ , σ θ ) \mathcal{N}(u_\theta,\sigma_\theta) N(uθ,σθ)是带参数的不确定性分布,而 N ( 0 , 1 ) \mathcal{N}(0,1) N(0,1)是一个确定性分布,又因为 $ u_\theta + \sigma_\theta \epsilon \backsim \mathcal{N}(u_\theta,\sigma_\theta)$ ,所以从 N ( u θ , σ θ ) \mathcal{N}(u_\theta,\sigma_\theta) N(uθ,σθ)采样一个Z,我们仅需从 N ( 0 , 1 ) \mathcal{N}(0,1) N(0,1)采样一个 ϵ \epsilon ϵ,然后让 Z = u θ + σ θ ϵ Z = u_\theta + \sigma_\theta \epsilon Z=uθ+σθϵ ,两者是等价的!这样做的同时,也解决了梯度传播问题。
我们将“从一个带参数的分布中进行采样”转变到“从一个确定的分布中进行采样”,以解决梯度无法传递问题的方法,就被称为**“重参数”(reparamterization)。**
实践
笔者手撸了一个DDPM,在Mnist和CIFAR10上做了实验,结果如下。看上去是有学习到东西,不过效果上还需要精调一下。



















 5869
5869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











