








©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 追一科技
研究方向 | NLP、神经网络
相信很多读者都听说过甚至读过克莱因的《高观点下的初等数学》[1] 这套书,顾名思义,这是在学到了更深入、更完备的数学知识后,从更高的视角重新审视过往学过的初等数学,以得到更全面的认知,甚至达到温故而知新的效果。类似的书籍还有很多,比如《重温微积分》[2]、《复分析:可视化方法》[3] 等。
回到扩散模型,目前我们已经通过三篇文章从不同视角去解读了DDPM,那么它是否也存在一个更高的理解视角,让我们能从中得到新的收获呢?当然有,《Denoising Diffusion Implicit Models》[4] 介绍的 DDIM 模型就是经典的案例,本文一起来欣赏它。

思路分析
在《生成扩散模型漫谈:DDPM = 贝叶斯 + 去噪》中,我们提到过该文章所介绍的推导跟 DDIM 紧密相关。具体来说,文章的推导路线可以简单归纳如下:
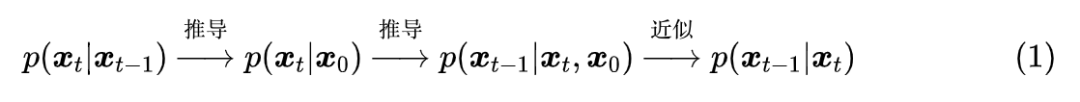
这个过程是一步步递进的。然而,我们发现最终结果有着两个特点:
1. 损失函数只依赖于 ;
2. 采样过程只依赖于 。
也就是说,尽管整个过程是以 为出发点一步步往前推的,但是从结果上来看,压根儿就没 的事。那么,我们大胆地“异想天开”一下:
高观点1:既然结果跟 无关,可不可以干脆“过河拆桥”,将 从整个推导过程中去掉?
DDIM 正是这个“异想天开”的产物!

待定系数
可能有读者会想,根据上一篇文章所用的贝叶斯定理:
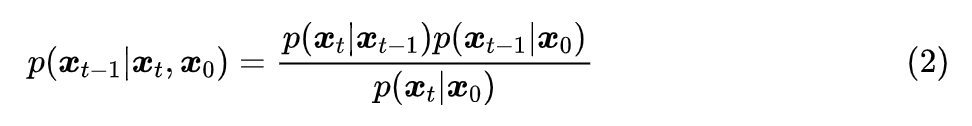
没有给定 怎么能得到 ?这其实是思维过于定式了,理论上在没有给定 的情况下, 的解空间更大,某种意义上来说是更加容易推导,此时它只需要满足边际分布条件:
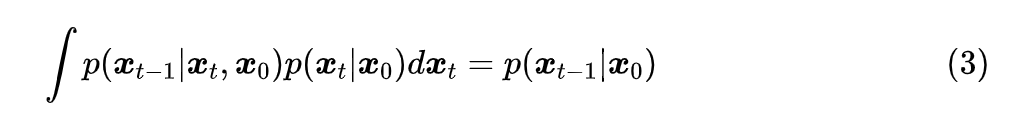
我们用待定系数法来求解这个方程。在上一篇文章中,所解出的 是一个正态分布,所以这一次我们可以更一般地设:

其中 都是待定系数,而为了不重新训练模型,我们不改变 和 ,于是我们可以列出:

其中,并且由正态分布的叠加性我们知道 。对比 的两个采样形式,我们发现要想(1)成立,只需要满足两个方程:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2106
2106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









