






背景
开源stella-base-zh-v2和stella-large-zh-v2, 效果更好且使用简单,不需要任何前缀文本。
训练代码和复现结果的代码如下:
https://github.com/SmartLi8/stella
基本思路
本人在工作中发现一些场景需要检索的文本块长度超过了512,但是现在的主流开源模型只能处理小于512长度文本,所以本人希望能否在现有模型的基础上把长度扩展到1024甚至更多。事实上512能满足很多需求了,1024则更让人感到可靠。
关键问题
基于上边的关键思路,不可避免的要解决三个关键问题:
如何让模型支持大于512的长度?
本人思考了很多种方法,但是最后选择了最简单的方法,当然在我看来也是最有效的方法(起码在有训练数据的情况下是最有效的),即直接扩充模型原来最大长度,相当于是把position_embedding有(512,768)的shape变为(1024,768),那么下面的问题就是如何初始化新的512-1024的position embedding了,最终采用了苏神的层次分解位置编码 进行初始化。
如何构造长度大于512的训练数据?
- 开源数据
首先自然的就会想到开源数据集中长度大于512的数据,但是这些数据的关键信息都集中在了文本块的前半部分,模型只需要重点专注前半部分就可以判断是否匹配,根本不需要看后半部分。
这里举个例子说明这个问题:
query: 小明在哪上大学?
passage:小明在北京读大学,今年20岁了,学的是计算机专业…
可以发现不关这个passage有多长,模型只需要重点编码前面十几个字就行。
不幸的是此类数据在开源长数据中占比非常高,若直接拿这些数据训练,虽然长度是大于了512,但是训练出的模型却会走捷径,只关注靠前部分的文字,实际提升非常有限!
既然发现了问题,那么解决方案也非常简单:对于开源数据中的长数据,将其切分成句子,然后依次和query计算集合相似度,相似度最高的句子如果处于passage后半段那么就纳入训练数据,否则就以一定的比例舍弃。
- LLM合成数据
现在LLM的能力已经非常强大,所以还会考虑找一些长度大于512的无监督文本块,让LLM来生成相关query。其中无监督文本块取自wudao语料库开源的200GB,网上可以自行下载。LLM使用了HFL的Chinese-Alpaca2-13B。具体构造方法为:抽取文本块后面的几个句子,然后模型生成对应的query。prompt比较简单,就不分享了。重点在于要让模型生成文本块后面的几个句子,这样在训练时才会逼着模型学习对文本块后面的文本进行编码
如何确保训练模型时不会有灾难性遗忘
我们希望在训练模型时,不要让模型遗忘掉原有的知识。stella模型是在piccolo基础上训练的,piccolo本身就拥有极强的文本编码能力。
经过反复实验发现,向量模型的灾难性遗忘问题极其严重,学了新的,基本就把旧的忘了一大半。为了解决这个问题,主要采用了2个策略:
1)Replay,即在训练数据中混合模型原有的训练数据和已有文本匹配数据
2)EWC,Elastic Weights Consolidation,openai的一篇论文,主要思想是对参数做一个约束,让新模型参数不至于偏离原模型太远。实际操作时,移除了需要在原始训练集计算的参数权重,转而使用固定值,权重设为了10,对于512-1024的position embedding,权重为0,因为这块参数是需要进行更新学习的,因此不做约束。
loss非常简单,就是新旧模型参数的mse乘以权重。
训练细节
Train Data:
1)开源数据(wudao_base_200GB、m3e和simclue),着重挑选了长度大于512文本,小于512的文本以一定概率舍弃
2)在通用语料库上使用LLM构造一批(question, paragraph)和(sentence, paragraph)数据
Test Data:
CMTEB测试数据不能准确的评估长文本编码能力:
1)长度大于512的过少
2)即便大于512,对于检索而言也只需要前512的文本内容
因此本人搜集了相关开源数据并使用规则进行过滤,最终整理了6份长文本测试集,他们分别是:
CMRC2018,通用百科
CAIL,法律阅读理解
DRCD,繁体百科,已转简体
Military,军工问答
Squad,英文阅读理解,已转中文
Multifieldqa_zh,清华的大模型长文本理解能力评测数据
处理规则是选取答案在512长度之后的文本,短的测试数据会欠采样一下,长短文本占比约为1:2,所以模型既得理解短文本也得理解长文本。 除了Military数据集,我们提供了其他5个测试数据的下载地址:https://drive.google.com/file/d/1WC6EWaCbVgz-vPMDFH4TwAMkLyh5WNcN/view
Loss function:
- 对比学习损失函数,最经典的batch内负例,缩放系数为30
- 带有难负例的对比学习损失函数(分别基于bm25和vector构造了难负例)
- EWC(Elastic Weights Consolidation)
- cosent loss,用于训练带标签的文本对
我们可以发现这次训练有多种数据集,对应多种loss,在实际操作时,我们采用了交替训练的方式,即每一步选取一种数据集计算对应的loss然后更新权重,下一步继续随机选取其他的数据集计算loss并更新权重。
这样做有2个好处:1)缓解了类不平衡问题,每次都从不同数据中采样一个batch训练。2)避免了loss尺度不一致的问题,因为是单独计算互不影响。至于相加会不会更好,本人没做实验也不敢乱说。
实验结果
CMTEB
CMTEB榜单的结果大家已经可以看到了,个人认为是站在了巨人肩膀上,侥幸拿到了top1,本人的初衷是在CMTEB榜单效果会有所下降,毕竟自己只拿了一点数据进行训练了,但是没想到效果反而有了提升,因此推测可能是长文本也能反过来促进整体的编码能力吧。
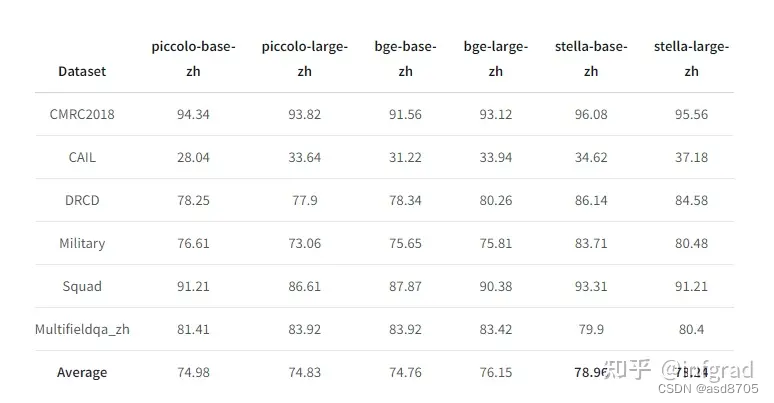
长文本编码能力测试
评测指标为Recall@5, 结果如下:















 7479
7479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









