







本文是在看李沐大神在b站上的视频时所做的笔记,视频链接如下:对比学习论文串烧
1.百花齐放
1.1 Instance Discrimination(InstDisc)
这篇文章可以说是巨人的肩膀,提出了Instance Discrimination(个体判别)这个代理任务。
这篇文章受到有监督学习的启发,如果我们将一张豹子的照片放到一个已经用有监督学习方法训练好的模型中,这个模型给出的分类结果往往都和豹子相关,如猎豹,雪豹等


这篇文章简单来说就是想通过一个卷积神经网络,将图片编码成一个特征,使得这些特征在最后的特征空间中尽可能的分开。(个体判别任务意味着每张图片都是一个类,所以希望他们尽可能分开)
这个卷积神经网络是通过对比学习的方法训练出来的,正样本就是这个图片本身(或者经过了一些数据增强的方法),负样本就是其他所有的图片。负样本的特征都存在memory bank中。
整个前向过程:我们假设batch_size为256,经过一个res50,最终得到的维度为2048维,再通过降维将其降为128维。batch_size为256就意味着有256个正样本,负样本就从memory bank中随机选取(这篇论文是抽取4096个)。这样有了正样本和负样本,就能够算NCELoss,然后反向传播进行特征的更新,更新之后就可以将最终的特征放入memory bank中进行更新。然后反复进行更新,得到最终的特征。
1.2 InvaSpread
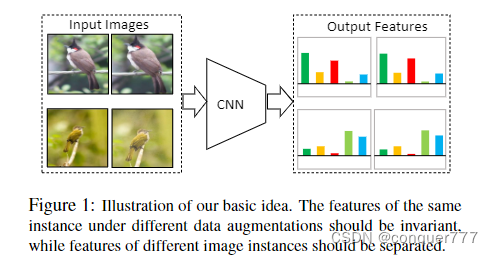
对于相似的物体,其特征应该保持一致性,对于不同的物体,其特征的差别应该会很大。
这篇文章的代理任务也是个体判别,先看一下前向过程

如果batch_size为256,这256张图片首先经过数据增强,得到下面的256张图片。对于图中的
x
1
x_1
x1来说,其经过数据增强后的图片
x
^
1
\hat{x}_1
x^1就是他的正样本,它的负样本是剩下所有的图片(包括原始的图片和数据增强后的图片)。也就是说,在一个batch中,正样本数量是256.负样本数量是
(
256
−
1
)
∗
2
(256-1)*2
(256−1)∗2
这个方法和InstDisc的不同之处在于,该方法的所有正负样本都是在一个batch中的,而InstDIsc的负样本是从memory bank中随机选取的。所有正负样本在一个batch中的好处在于这样就可以用一个编码器(是指对图中上面和下面的CNN是共享参数的,相当于一个编码器)去做端到端的训练
最终得到特征在空间中的分布,应该是原图和数据增强后的图片较为接近,而不同的图片相差较远。
这篇文章和simCLR很像,但是他的效果没有那么好,主要是因为他的负样本数量不够多
2.CV双雄
2.1 MoCo
将之前的对比学习方法都归纳为了字典查询的问题,主要提出了两个东西,一个是队列,一个是动量编码器,从而形成一个很大的字典来帮助对比学习
可以参考精读视频Moco精读
2.2 SimCLR
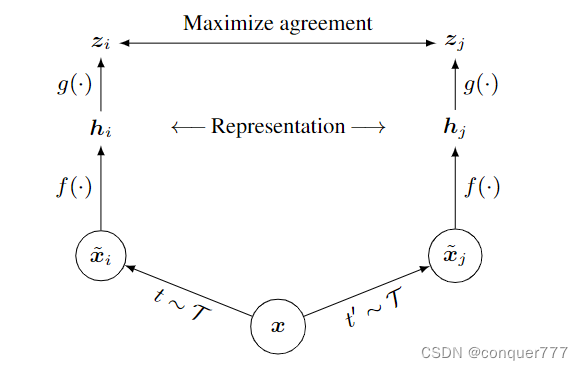
我们对一个batch里面的图片x进行不同的数据增强,分别得到
x
~
i
\tilde x_i
x~i和
x
~
j
\tilde x_j
x~j。同一个图片延伸得到的两个图片就是正样本,也就是如果一个batch有N个样本,那么就得到2N个样本。给定一个正样本对(就是由同一个图片经过数据增加得到的两个图片),那其他的
2
(
N
−
1
)
2(N-1)
2(N−1)个样本就都是负样本。然后通过一个编码器f,这里的两个f是共享权重的(所以其实只有一个编码器)。在得到
h
i
h_i
hi和
h
j
h_j
hj之后,再经过一个g(projection head),这里的g其实是一个单隐藏层的MLP,最终得到
z
i
z_i
zi和
z
j
z_j
zj,最终要衡量
z
i
z_i
zi和
z
j
z_j
zj是否有最大的一致性,他们采用的损失函数如下:

这里面的g是只有在训练时候才用,而在做下游任务时,就不用这个g了。
SimCLR和Inva Spread是非常非常相像的,其主要区别如下:
- 1.SimCLR用了更多了数据增强
- 2.加了g函数,也就是一个可学习的非线性变换
- 3.使用了更大的batchsize
接下来是SimCLR中的一些实验
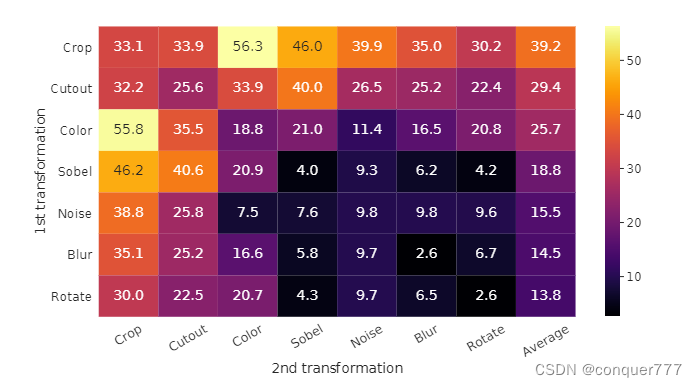
这个图对比了不同的数据增强方式的效果,可以发现Crop(随机剪裁)和Color(色彩变换)进行组合时候,效果最好(对应图中的55.8和56.3这两个数值)

这个图是对比了是否使用非线性变换(也就是前面提到的g函数)的效果,图中的non-linear就是有g,None就是没有g,Linear是最后加一个不带激活函数的MLP。
2.3 MoCo v2
其实就是将SimCLR中的技术拿过来直接用,比如更多的数据增强,以及最后的projection head(非线性的g函数)

从上表可以看出,只加一个projection head就涨了6个点,后面再使用更多的数据增强,使用cos(cosine learning rete schedule 余弦学习率衰减),训练更多的epoch,最终涨到了71.1。
2.4 SimCLR v2
从SimCLR v1到v2主要有以下的区别:
- .在无监督学习中,模型越大效果越好。v1中的f是一个50层的resnet,在v2中换成了152层的resnet,同时用了selective kernels(SK net),即相当于加强了骨干网络。
- 加深projection head,最后发现两层的MLP效果更好
- 使用了MoCo中提出的动量编码器
2.5 SwAV(swap assignments views)
这篇文章的想法是:给定同一张图片,生成不同的视角,我们希望可以用一个视角的特征去预测另外一个视角的特征,因为所有的特征理论上应该是非常相似的。
SwAV是将对比学习和聚类的方法结合了起来。
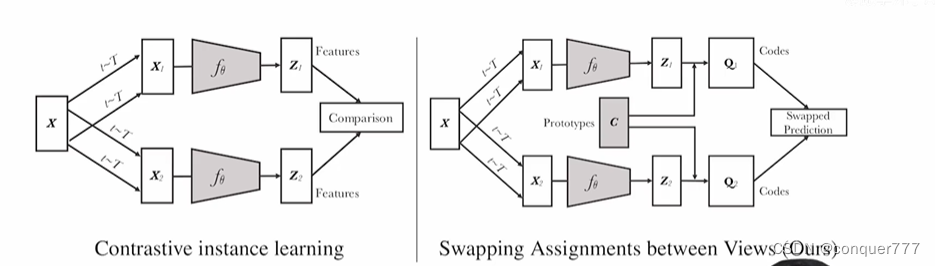
左边是原来对比学习的方法,右边是SwAV这篇论文的方法。SwAV在得到
z
i
z_i
zi和
z
j
z_j
zj之后,不是直接用
z
i
z_i
zi和
z
j
z_j
zj进行对比,而是让他们都和聚类中心c对比。c是D*K维的,D特征的维度,K是聚类中心的数目,这里是3000。让z和c去生成一个目标,也就是图中的q1和q2。q1和q2就相当于ground truth一样的东西。如果x1和x2是一对正样本的话,那z1和z2的特征应该是非常接近的,那么用z1点乘c,就能预测q2,同样的,用z2点乘c,就能预测q1。这就是图中的swap prediction的代理任务。
聚类的好处:
如果要和很多的负样本作对比,那么需要成千上万个负样本,而且即便如此也只是一个近似。而如果跟聚类中心进行对比,我们可以只用几百个或者最多3000个聚类中心进行对比。第二点是因为聚类中心有明确的含义,如果像之前那样只是随机选取负样本,那么由于可能将正样本选为负样本,而且负样本的类别也可能不均衡,所以不如聚类中心有效
3.不用负样本
3.1 BYOL(Bootstrap Your Own Latent)
bootstrap是提升的意思,latent,feature,embeding,hidden在AI的论文里面基本都是特征的意思。BYOL的意思其实就是自己和自己学,不需要负样本。
首先要说明为什么在对比学习里面需要负样本:
在有负样本的情况下,我们需要是要使得正样本之间的特征尽可能相似,正负样本之间的特征尽可能不相似。
假如没有了负样本,那么我们就只需要让正样本之间的特征尽可能相似,这时候就有一个明显的捷径:一个模型无论输入什么,都给同样的输出。也就是说所有的样本的特征都是一样的,这样显然是满足让正样本之间的特征尽可能相似的要求的,我们计算的损失函数永远是0。这样就相当于模型什么都不需要学,loss永远为0。而如果加上了负样本这个约束,就是让相似的物体有相似的特征,不相似的物体有不相似的特征,这样如果模型输出的特征全都是一样的,计算负样本之间的loss时,模型大小就是无穷大,这样模型才有动力去学,而不是走这个捷径。
所以说负样本在对比学习里面是必须的,很多论文里把模型学到捷径称作model collapse(模型坍塌)或者learning collapse(学习坍塌)。
BYOL在没有用负样本的情况下,也达到了非常高的精度
BYOL的架构如下:

对于一个输入的图片x,经过不同的数据增强后得到
v
v
v和
v
′
v^{'}
v′,
v
v
v经过编码器
f
θ
f_{\theta}
fθ,
v
′
v^{'}
v′经过编码器
f
ξ
f_{\xi}
fξ。这两个编码器是架构是一样的,但是参数不同。
f
θ
f_{\theta}
fθ是随着梯度的更新而更新的,而
f
ξ
f_{\xi}
fξ是使用了动量编码器。将得到的特征和SimCLR一样,通过一个projection head(就是一个MLP)得到
z
θ
z_{\theta}
zθ,
z
θ
z_{\theta}
zθ在这里是256维,比之前的128大。
z
ξ
′
z_{\xi}^{'}
zξ′是通过
g
ξ
g_{\xi}
gξ得到的,
g
ξ
g_{\xi}
gξ的结构和
g
θ
g_{\theta}
gθ是一样的,也是一个MLP,不过是通过动量的方法来更新。在之前的方法中,得到
z
θ
z_{\theta}
zθ和
z
ξ
′
z_{\xi}^{'}
zξ′后,需要让他们的特征尽可能的接近,也就是达到maximum agreement。但是BYOL没有这么做,在得到
z
θ
z_{\theta}
zθ之后,在后面加上了
q
θ
q_{\theta}
qθ这一层,
q
θ
q_{\theta}
qθ的结构和
g
θ
g_{\theta}
gθ是一样的,也是一个MLP,这样就得到了一个新的特征
q
θ
(
z
θ
)
q_{\theta}(z_{\theta})
qθ(zθ)。我们最终的目的是想让预测的
q
θ
(
z
θ
)
q_{\theta}(z_{\theta})
qθ(zθ)和
z
ξ
′
z_{\xi}^{'}
zξ′尽可能的一致,训练用的损失函数就是一个MSELoss,就是算
q
θ
(
z
θ
)
q_{\theta}(z_{\theta})
qθ(zθ)和
z
ξ
′
z_{\xi}^{'}
zξ′之间的MSELoss。
在训练完成之后,后面的MLP部分就被去掉了,就用得到的
y
θ
y_{\theta}
yθ来做下游的任务
3.2 SimSiam
SimSiam是一个总结性的工作,他和其他工作的对比如下:

可以看到,SimSiam与BYOL最大的区别就是没有使用动量编码器,左右两个编码器的架构一样而且共享参数,所以叫做Siamese(孪生)网络
4.Transformer
4.1 MoCo v3
伪代码如下:

使用了动量编码器,使用了proj head和pred mlp,最后的目标函数是对比学习的loss,并且也是算的对称项,所以他说一个MoCov2和SimSiam的一个结合,然后将backbone换成了ViT。
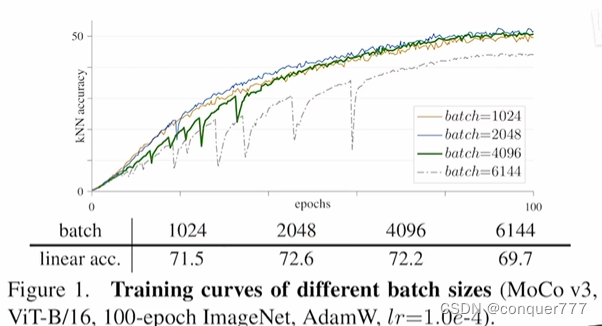
当batch比较小时候,曲线还比较平滑,但是当batch变大时候,就会出现训练很不稳定的情况。
作者最后发现是在ViT最开始进行patch划分时候出现的问题,所以他们将最开始划分patch的MLP层冻住,就是随机初始化参数后就不再更改。















 356
356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









