








hash_create
创建动态哈希表hash_create函数,形参tabname用于传入表名,nelem用于传入元素(elemets)的最大数量,info传入额外表参数结构体指针,flags用于传入用于指示从Info取哪些参数的掩码。
以InitShmemIndex函数为例(PostgreSQL数据库共享内存——小管家InitShmemIndex函数),向hash_create函数传入的HASHCTL结构体和flags如下所示。
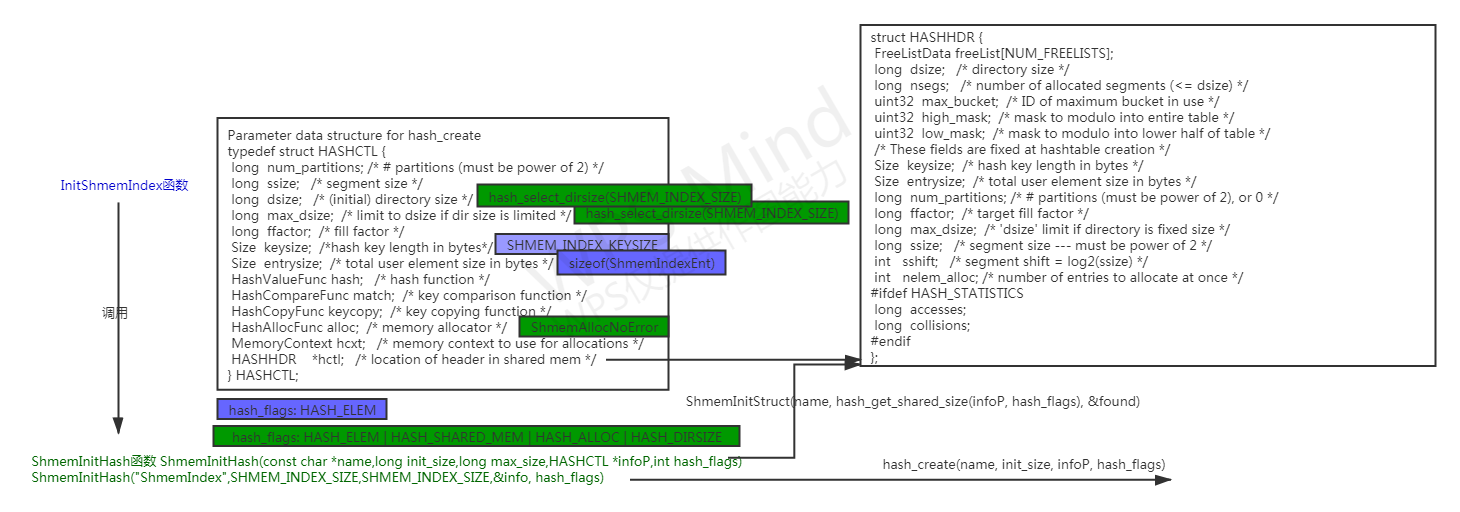
对于共享哈希表,local哈希头(HTAB结构体)会被分配在TopMemoryContext,其他的都会被分配在共享内存中。对于非共享哈希表,所有结构体都被分配在专门为哈希表创建的内存上下文中,该内存上下文是调用者的内存上下文的子级,如果没有指定任何内存上下文,则使用TopMemoryContext。如果flags指定了HASH_SHARED_MEM标志,是共享哈希表,否则是非共享哈希表。
HTAB *hash_create(const char *tabname, long nelem, HASHCTL *info, int flags) {
HTAB *hashp;
HASHHDR *hctl;
if (flags & HASH_SHARED_MEM) {
/* Set up to allocate the hash header */
CurrentDynaHashCxt = TopMemoryContext;
}else{
/* Create the hash table's private memory context */
if (flags & HASH_CONTEXT) CurrentDynaHashCxt = info->hcxt;
else CurrentDynaHashCxt = TopMemoryContext;
CurrentDynaHashCxt = AllocSetContextCreate(CurrentDynaHashCxt,"dynahash",ALLOCSET_DEFAULT_SIZES);
}
初始化哈希头,并将table名拷贝到HTAB结构体中的tabname成员。
/* Initialize the hash header, plus a copy of the table name */
hashp = (HTAB *) DynaHashAlloc(sizeof(HTAB) + strlen(tabname) + 1);
MemSet(hashp, 0, sizeof(HTAB));
hashp->tabname = (char *) (hashp + 1);
strcpy(hashp->tabname, tabname);
/* If we have a private context, label it with hashtable's name */
if (!(flags & HASH_SHARED_MEM))
MemoryContextSetIdentifier(CurrentDynaHashCxt, hashp->tabname);
选择合适的哈希函数,如果指定了HASH_FUNCTION标志,则使用info->hash,如果使用HASH_BLOBS标志,则使用uint32_hash或tag_hash,否则使用string_hash。同样处理比较函数和键拷贝函数以及内存分配函数。
/* Select the appropriate hash function (see comments at head of file). */
if (flags & HASH_FUNCTION)
hashp->hash = info->hash;
else if (flags & HASH_BLOBS){
/* We can optimize hashing for common key sizes */
Assert(flags & HASH_ELEM);
if (info->keysize == sizeof(uint32))
hashp->hash = uint32_hash;
else
hashp->hash = tag_hash;
}else
hashp->hash = string_hash; /* default hash function */
if (flags & HASH_COMPARE)
hashp->match = info->match;
else if (hashp->hash == string_hash)
hashp->match = (HashCompareFunc) string_compare;
else
hashp->match = memcmp;
/* Similarly, the key-copying function defaults to strlcpy or memcpy. */
if (flags & HASH_KEYCOPY)
hashp->keycopy = info->keycopy;
else if (hashp->hash == string_hash)
hashp->keycopy = (HashCopyFunc) strlcpy;
else
hashp->keycopy = memcpy;
/* And select the entry allocation function, too. */
if (flags & HASH_ALLOC)
hashp->alloc = info->alloc;
else
hashp->alloc = DynaHashAlloc;
对于HASH_SHARED_MEM来说,ctl结构体和目录是预先分配好的,并且需要设置isshared为true;否则需要设置hctl和dir为null,不预先分配,且isshared为false,后续使用alloc函数为hctl分配内存。
if (flags & HASH_SHARED_MEM){
hashp->hctl = info->hctl;
hashp->dir = (HASHSEGMENT *) (((char *) info->hctl) + sizeof(HASHHDR));
hashp->hcxt = NULL;
hashp->isshared = true;
/* hash table already exists, we're just attaching to it */
if (flags & HASH_ATTACH){
/* make local copies of some heavily-used values */
hctl = hashp->hctl;
hashp->keysize = hctl->keysize;
hashp->ssize = hctl->ssize;
hashp->sshift = hctl->sshift;
return hashp;
}
}else{
/* setup hash table defaults */
hashp->hctl = NULL;
hashp->dir = NULL;
hashp->hcxt = CurrentDynaHashCxt;
hashp->isshared = false;
}
if (!hashp->hctl){
hashp->hctl = (HASHHDR *) hashp->alloc(sizeof(HASHHDR));
if (!hashp->hctl) ereport(ERROR,(errcode(ERRCODE_OUT_OF_MEMORY),errmsg("out of memory")));
}
以下为针对HASH_PARTITION、HASH_SEGMENT、HASH_FFACTOR、HASH_ELEM的处理。
hashp->frozen = false;
hdefault(hashp);
hctl = hashp->hctl;
if (flags & HASH_PARTITION){
/* Doesn't make sense to partition a local hash table */
Assert(flags & HASH_SHARED_MEM);
Assert(info->num_partitions == next_pow2_int(info->num_partitions));
hctl->num_partitions = info->num_partitions;
}
if (flags & HASH_SEGMENT){
hctl->ssize = info->ssize;
hctl->sshift = my_log2(info->ssize);
/* ssize had better be a power of 2 */
Assert(hctl->ssize == (1L << hctl->sshift));
}
if (flags & HASH_FFACTOR) hctl->ffactor = info->ffactor;
/* SHM hash tables have fixed directory size passed by the caller. */
if (flags & HASH_DIRSIZE){
hctl->max_dsize = info->max_dsize;
hctl->dsize = info->dsize;
}
/* hash table now allocates space for key and data but you have to say how much space to allocate */
if (flags & HASH_ELEM){
Assert(info->entrysize >= info->keysize);
hctl->keysize = info->keysize;
hctl->entrysize = info->entrysize;
}
/* make local copies of heavily-used constant fields */
hashp->keysize = hctl->keysize;
hashp->ssize = hctl->ssize;
hashp->sshift = hctl->sshift;
调用init_htab函数构建hash目录结构。
/* Build the hash directory structure */
if (!init_htab(hashp, nelem)) elog(ERROR, "failed to initialize hash table \"%s\"", hashp->tabname);
对于共享哈希表,预分配需要数量的元素会降低运行时out of shared memory的几率,对于非共享哈希表来说,预分配需要梳理的元素(数量小于nelem_alloc)会降低空间浪费。
if ((flags & HASH_SHARED_MEM) || nelem < hctl->nelem_alloc){
int i,freelist_partitions,nelem_alloc,nelem_alloc_first;
/* If hash table is partitioned, give each freelist an equal share of the initial allocation. Otherwise only freeList[0] is used. */
if (IS_PARTITIONED(hashp->hctl))
freelist_partitions = NUM_FREELISTS;
else
freelist_partitions = 1;
nelem_alloc = nelem / freelist_partitions;
if (nelem_alloc <= 0)
nelem_alloc = 1;
/* Make sure we'll allocate all the requested elements; freeList[0] gets the excess if the request isn't divisible by NUM_FREELISTS. */
if (nelem_alloc * freelist_partitions < nelem)
nelem_alloc_first =
nelem - nelem_alloc * (freelist_partitions - 1);
else
nelem_alloc_first = nelem_alloc;
for (i = 0; i < freelist_partitions; i++){
int temp = (i == 0) ? nelem_alloc_first : nelem_alloc;
if (!element_alloc(hashp, temp, i))
ereport(ERROR,(errcode(ERRCODE_OUT_OF_MEMORY),errmsg("out of memory")));
}
}
if (flags & HASH_FIXED_SIZE)
hashp->isfixed = true;
return hashp;
}
init_htab
init_htab建立哈希表目录和段数组。计算哈希桶的数量next_pow2_int((nelem - 1) / hctl->ffactor + 1),计算segment数量next_pow2_int((nbuckets - 1) / hctl->ssize + 1),
static bool init_htab(HTAB *hashp, long nelem) {
HASHHDR *hctl = hashp->hctl;
HASHSEGMENT *segp;
int nbuckets, nsegs, i;
/* initialize mutexes if it's a partitioned table */
if (IS_PARTITIONED(hctl))
for (i = 0; i < NUM_FREELISTS; i++)
SpinLockInit(&(hctl->freeList[i].mutex));
/* Divide number of elements by the fill factor to determine a desired
* number of buckets. Allocate space for the next greater power of two
* number of buckets */
nbuckets = next_pow2_int((nelem - 1) / hctl->ffactor + 1);
/* In a partitioned table, nbuckets must be at least equal to
* num_partitions; were it less, keys with apparently different partition
* numbers would map to the same bucket, breaking partition independence.
* (Normally nbuckets will be much bigger; this is just a safety check.) */
while (nbuckets < hctl->num_partitions)
nbuckets <<= 1;
hctl->max_bucket = hctl->low_mask = nbuckets - 1;
hctl->high_mask = (nbuckets << 1) - 1;
/* Figure number of directory segments needed, round up to a power of 2 */
nsegs = (nbuckets - 1) / hctl->ssize + 1;
nsegs = next_pow2_int(nsegs);
/* Make sure directory is big enough. If pre-allocated directory is too small, choke (caller screwed up). */
if (nsegs > hctl->dsize){
if (!(hashp->dir))
hctl->dsize = nsegs;
else
return false;
}
/* Allocate a directory */
if (!(hashp->dir)){
CurrentDynaHashCxt = hashp->hcxt;
hashp->dir = (HASHSEGMENT *)hashp->alloc(hctl->dsize * sizeof(HASHSEGMENT));
if (!hashp->dir) return false;
}
/* Allocate initial segments */
for (segp = hashp->dir; hctl->nsegs < nsegs; hctl->nsegs++, segp++) {
*segp = seg_alloc(hashp);
if (*segp == NULL) return false;
}
/* Choose number of entries to allocate at a time */
hctl->nelem_alloc = choose_nelem_alloc(hctl->entrysize);
return true;
}



















 2707
2707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









