







TD3(Twin Delayed Deep Deterministic policy gradient algorithm)算法适合于高维连续动作空间,是DDPG算法的优化版本,为了优化DDPG在训练过程中Q值估计过高的问题。
相较DDPG的改进:
1、运用两个Critic网络。运用两个网络对动作价值函数进行估计。在练习的时分挑选最小的Q值作为估值(为了防止误差累积过高)。
2、运用延迟学习。Critic网络更新的频率要比Actor网络更新的频率要大(类似GAN的思想,先训练好Critic才能更好的对actor指指点点)。
3、运用梯度截取。将Actor的参数更新的梯度截取到某个范围内。
4、加入训练噪声。更新Critic网络时候加入随机噪声,以达到对Critic网络波动的稳定性。
算法流程:
算法的伪代码

代码实现:
actor:
class Actor(nn.Module):
def __init__(self, state_dim, action_dim, net_width, maxaction):
super(Actor, self).__init__()
self.l1 = nn.Linear(state_dim, net_width)
self.l2 = nn.Linear(net_width, net_width)
self.l3 = nn.Linear(net_width, action_dim)
self.maxaction = maxaction
def forward(self, state):
a = torch.tanh(self.l1(state))
a = torch.tanh(self.l2(a))
a = torch.tanh(self.l3(a)) * self.maxaction
return acritic:
class Q_Critic(nn.Module):
def __init__(self, state_dim, action_dim, net_width):
super(Q_Critic, self).__init__()
# Q1 architecture
self.l1 = nn.Linear(state_dim + action_dim, net_width)
self.l2 = nn.Linear(net_width, net_width)
self.l3 = nn.Linear(net_width, 1)
# Q2 architecture
self.l4 = nn.Linear(state_dim + action_dim, net_width)
self.l5 = nn.Linear(net_width, net_width)
self.l6 = nn.Linear(net_width, 1)
def forward(self, state, action):
sa = torch.cat([state, action], 1)
q1 = F.relu(self.l1(sa))
q1 = F.relu(self.l2(q1))
q1 = self.l3(q1)
q2 = F.relu(self.l4(sa))
q2 = F.relu(self.l5(q2))
q2 = self.l6(q2)
return q1, q2
def Q1(self, state, action):
sa = torch.cat([state, action], 1)
q1 = F.relu(self.l1(sa))
q1 = F.relu(self.l2(q1))
q1 = self.l3(q1)
return q1TD3的整体实现:
class TD3(object):
def __init__(
self,
env_with_Dead,
state_dim,
action_dim,
max_action,
gamma=0.99,
net_width=128,
a_lr=1e-4,
c_lr=1e-4,
Q_batchsize=256
):
self.actor = Actor(state_dim, action_dim, net_width, max_action).to(device)
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=a_lr)
self.actor_target = copy.deepcopy(self.actor)
self.q_critic = Q_Critic(state_dim, action_dim, net_width).to(device)
self.q_critic_optimizer = torch.optim.Adam(self.q_critic.parameters(), lr=c_lr)
self.q_critic_target = copy.deepcopy(self.q_critic)
self.env_with_Dead = env_with_Dead
self.action_dim = action_dim
self.max_action = max_action
self.gamma = gamma
self.policy_noise = 0.2 * max_action
self.noise_clip = 0.5 * max_action
self.tau = 0.005
self.Q_batchsize = Q_batchsize
self.delay_counter = -1
self.delay_freq = 1
def select_action(self, state): # only used when interact with the env
with torch.no_grad():
state = torch.FloatTensor(state.reshape(1, -1)).to(device)
a = self.actor(state)
return a.cpu().numpy().flatten()
def train(self, replay_buffer):
self.delay_counter += 1
with torch.no_grad():
s, a, r, s_prime, dead_mask = replay_buffer.sample(self.Q_batchsize)
noise = (torch.randn_like(a) * self.policy_noise).clamp(-self.noise_clip, self.noise_clip)
smoothed_target_a = (
self.actor_target(s_prime) + noise # Noisy on target action
).clamp(-self.max_action, self.max_action)
# Compute the target Q value
target_Q1, target_Q2 = self.q_critic_target(s_prime, smoothed_target_a)
target_Q = torch.min(target_Q1, target_Q2)
'''DEAD OR NOT'''
if self.env_with_Dead:
target_Q = r + (1 - dead_mask) * self.gamma * target_Q # env with dead
else:
target_Q = r + self.gamma * target_Q # env without dead
# Get current Q estimates
current_Q1, current_Q2 = self.q_critic(s, a)
# Compute critic loss
q_loss = F.mse_loss(current_Q1, target_Q) + F.mse_loss(current_Q2, target_Q)
# Optimize the q_critic
self.q_critic_optimizer.zero_grad()
q_loss.backward()
self.q_critic_optimizer.step()
if self.delay_counter == self.delay_freq:
# Update Actor
a_loss = -self.q_critic.Q1(s, self.actor(s)).mean()
self.actor_optimizer.zero_grad()
a_loss.backward()
self.actor_optimizer.step()
# Update the frozen target models
for param, target_param in zip(self.q_critic.parameters(), self.q_critic_target.parameters()):
target_param.data.copy_(self.tau * param.data + (1 - self.tau) * target_param.data)
for param, target_param in zip(self.actor.parameters(), self.actor_target.parameters()):
target_param.data.copy_(self.tau * param.data + (1 - self.tau) * target_param.data)
self.delay_counter = -1
def save(self, episode):
torch.save(self.actor.state_dict(), "ppo_actor{}.pth".format(episode))
torch.save(self.q_critic.state_dict(), "ppo_q_critic{}.pth".format(episode))
def load(self, episode):
self.actor.load_state_dict(torch.load("ppo_actor{}.pth".format(episode)))
self.q_critic.load_state_dict(torch.load("ppo_q_critic{}.pth".format(episode)))网络结构图:
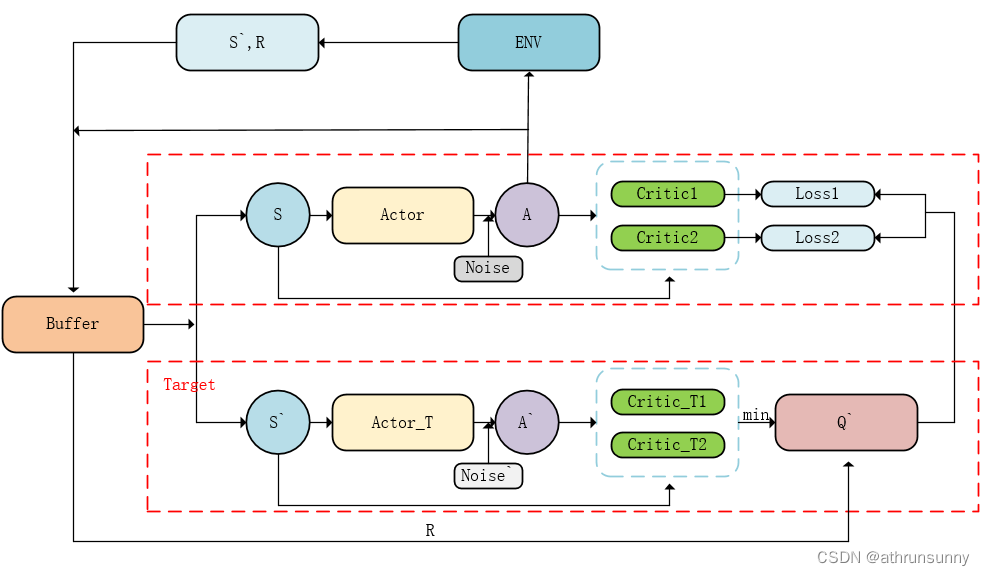
其中actor和target部分的网络参数会延迟更新,也就是说critic1和critic2参数在不断更新,训练好critic之后才能知道actor做出理想的动作。


















 7678
7678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











