







文章目录
写在前面
Spark Standalone集群是Master-Slaves架构的集群模式,存在着Master单点故障的问题。为了解决这个问题,Spark有提供一种方案:
基于zookeeper的Standby Master:将spark集群连接到同一个Zookeeper实例,并启动多个Master,利用zookeeper提供的选举和状态保存的功能,可以使一个Master被选举成活着的Master,其他Master处于Standby状态。如果现任的Master挂掉了,另外一个就可通过选举产生,并恢复到旧的Master状态,然后恢复调度。
下面来介绍怎么在zookeeper上搭建高可用的Spark集群。
安装Zookeeper
下载Zookeeper(先在Master上搞)
下载Zookeeper可以到这里下载:ZooKeeper Releases
我选择的版本是3.4.14,不推荐用太新的版本,用新的版本意味着可能要踩别人没踩过的坑,踩别人踩过的坑有利于我们更快地总结问题解决问题。
# 下载下来后解压
tar -zxvf zookeeper-3.4.14.tar.gz -C /usr/local
配置Zookeeper
#把zookeeper目录的操作权限赋给我的hadoop用户
sudo chown -R hadoop /usr/local/zookeeper-3.4.14
#进入Zookeeper的安装目录
cd /usr/local/zookeeper-3.4.14
#拷贝重命名
cp zoo_sample.cfg zoo.cfg
#配置zoo.cfg
vi zoo.cfg
修改如下内容
#存放数据的目录
dataDir=/usr/local/zookeeper-3.4.14/zData
#存放日志的目录
dataLogDir=/usr/local/zookeeper-3.4.14/logs
#zookeeper集群里的主机和端口号
server.1= Master:2888:3888
server.2= Slave1:2888:3888
创建相应的数据和日志目录
修改上面的配置文件后,不要忘记创建相应的数据目录和日志目录
cd /usr/local/zookeeper-3.4.14
mkdir zData
mkdir logs
分发Zookeeper目录
在做好上述配置后,分发配置好的Zookeeper目录到各个机子上去
cd /usr/local
#在Master上分发Zookeeper目录到Slave1的同样路径下
scp -r zookeeper-3.4.14/ Slave1:`pwd`
注意:可以在Slave1执行命令sudo chown -R hadoop /usr/local/zookeeper-3.4.14,把目录的操作权限赋给hadoop用户,因为我是在hadoop用户下搭的集群,假如你的是root用户下搭建的,就省去赋予权限的操作。
创建myid
分发完毕后,到各个机子上创建相对的myid
注意,创建myid不是乱创建,还记得之前配置过的这些字段🐎,要对应起来
server.1= Master:2888:3888
server.2= Slave1:2888:3888
-
为此我在Master的/usr/local/zookeeper-3.4.14/zData下创建myid为1
cd /usr/local/zookeeper-3.4.14/zData echo 1 > myid -
在Slave1的/usr/local/zookeeper-3.4.14/zData下创建myid为2
cd /usr/local/zookeeper-3.4.14/zData echo 2 > myid
启动zookeeper
#在集群的各个主机上启动zookeeper,紧接着查看各自的zookeeper状态,是leading还是following
cd /usr/local/zookeeper-3.4.14/bin
./zkServer.sh start
./zkServer.sh status
安装Spark
安装Spark这一步的详细过程可以查看我的另一篇博文:小坨的Spark分布式集群环境搭建小笔记
按照上面这一篇博文把Spark安装好之后,它的Spark集群架构还是Spark Standalone的Master-Slaves架构的集群模式,存在着Master单点故障的问题。
修改Spark的配置文件
我们只要稍微修改一下里面的配置文件,就能实现Spark集群的高可用。
cd /usr/local/spark/
vi spark-env.sh
注释掉如下内容
#SPARK_MASTER_HOST=192.168.100.10
注释掉master节点的ip,因为高可用部署的master是变化的
添加如下内容
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=Master,Slave1
-Dspark.deploy.zookeeper.dir=/spark"
其中
- recoveryMode,恢复模式(Master重新启动的模式)有三种:Zookeeper、FileSystem、None
- deploy.zookeeper.url,Zookeeper的服务器地址
- deploy.zookeeper.dir,zookeeper上保存集群元数据信息的文件、目录。
启动基于zookeeper的Spark集群
完成上面的操作,我们的基于zookeeper的高可用的Spark集群就搭建起来了,下面我们启动集群看看能不能正常运行。
-
先启动zookeeper,上面已经启动一遍了,这里不重复启动
-
再启动spark
#在Master上 cd /usr/local/spark/sbin ./start-all.sh #在Slave1上 cd /usr/local/spark/sbin ./start-master.sh在Master上执行jps命令,可以看到Master已经启动,至于这里还出现了个Worker,是因为我在Master上也部署了一个Worker。

在Slave1上执行jps命令,可以看到Worker已经启动,至于也出现了个Master,证明我们的基于zookeeper的高可用的Spark集群已经搭建完成了。
验证集群是否高可用
上面我们高可用的Spark集群已经搭建完成了,这里再验证一下集群是否高可用。
在上面启动基于zookeeper的Spark集群,我们看到Spark集群里出现了两个Master,其中一个是alive的Master,一个是 standby的Master,它会在ALIVE的Master宕机或关闭之后,接替ALIVE的Master,控制集群的运行。
这时我在我的http://master:8080/查看到Master节点上的Master是alive的,在 http://slave1:8080/ 查看到Slave1节点上的Master是alive的。
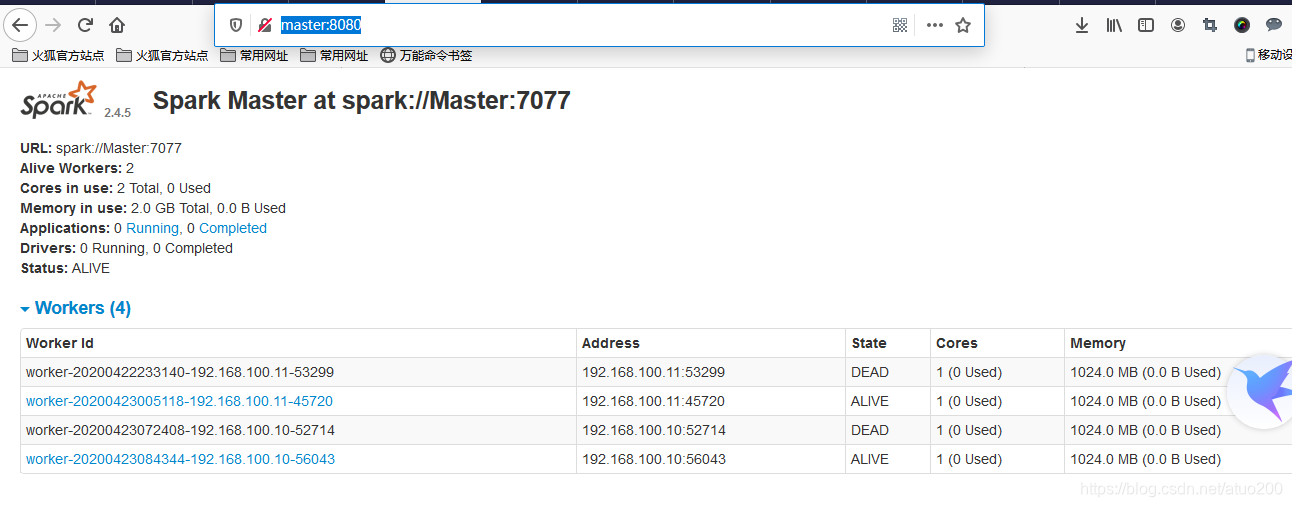
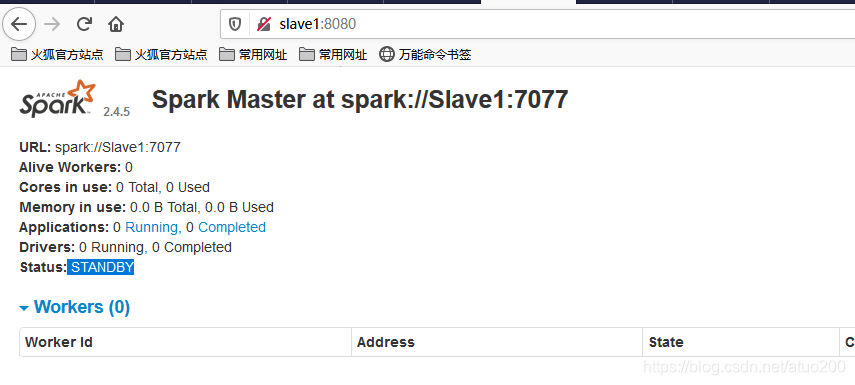
接下来我在Master节点上关闭master,看是否Slave1节点上的Master能接替上来。
cd /usr/local/spark/sbin
./stop-master.sh
这时再重新连接 http://master:8080/页面已经连接不上了,因为我把Master节点上Master进程关闭了。
重新连接 http://slave1:8080/ 发现Slave1上的Master已经从standby状态转为alive。

到这里,我们的基于zookeeper的高可用的Spark集群已经搭建成功,集群的高可用性能验证通过。我们可以跑Spark了,跑Spark之前,我们要对Spark里的RDD有一个基本的认识,可以见我的另一篇博文:Spark之初识RDD

















 374
374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









