







整理收录了wiki和http://www.nocow.cn的一部分算法:
迪科斯彻算法(Dijkstra's algorithm)
伪代码
在下面的算法中,u := Extract_Min(Q) 在顶点集合 Q 中搜索有最小的 d[u] 值的顶点 u。这个顶点被从集合 Q 中删除并返回给用户。
1 function Dijkstra(G, w, s) 2 for each vertex v in V[G] // 初始化 3 d[v] := infinity // 将各点的已知最短距离先设置成无穷大 4 previous[v] := undefined // 各点的已知最短路径上的前趋都未知 5 d[s] := 0 // 因为出发点到出发点间不需移动任何距离,所以可以直接将s到s的最小距离设为0 6 S := empty set 7 Q := set of all vertices 8 while Q is not an empty set // Dijkstra演算法主體 9 u := Extract_Min(Q) 10 S.append(u) 11 for each edge outgoing from u as (u,v) 12 if d[v] > d[u] + w(u,v) // 拓展边(u,v)。w(u,v)为从u到v的路径长度。 13 d[v] := d[u] + w(u,v) // 更新路径长度到更小的那个和值。 14 previous[v] := u // 记录前趋顶点
如果我们只对在 s 和 t 之间查找一条最短路径的话,我们可以在第9行添加条件如果满足 u = t 的话终止程序。
通过推导可知,为了记录最佳路径的轨迹,我们只需记录该路径上每个点的前趋,即可通过迭代来回溯出 s 到 t 的最短路径(当然,使用后继节点来存储亦可。但那需要修改代码):
1 s := empty sequence 2 u := t 3 while defined u 4 insert u to the beginning of S 5 u := previous[u] //previous数组即为上文中的p
现在串行 S 就是从 s 到 t 的最短路径的顶点集。
自然语言描述
对有向图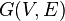 ,用贝尔曼-福特算法求以
,用贝尔曼-福特算法求以 为源点的最短路径的过程:
为源点的最短路径的过程:
- 建立
![dist[]](http://upload.wikimedia.org/wikipedia/zh/math/3/f/7/3f7f80041804420daae37d92481ab98b.png) ,表示目前已知源点到各个节点的最短距离,起始值
,表示目前已知源点到各个节点的最短距离,起始值 ![dist[s]=0](http://upload.wikimedia.org/wikipedia/zh/math/d/c/6/dc6d7fc331d836ed78fa6337a0e677a9.png) ,其余皆为
,其余皆为 。
。 - 建立
![Pred[]](http://upload.wikimedia.org/wikipedia/zh/math/8/9/8/89844cee875da9946e053f0f5442a9eb.png) ,表示某节点路径上的父节点,起始值皆为NULL。
,表示某节点路径上的父节点,起始值皆为NULL。 - 对
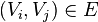 ,比较
,比较![dist[V_i]+(V_i,V_j)](http://upload.wikimedia.org/wikipedia/zh/math/f/d/1/fd104bc4611ac87e202ef54dd1e22acc.png) 和
和![dist[V_j]](http://upload.wikimedia.org/wikipedia/zh/math/6/5/f/65f6fec3452b685532a6c193fef999b8.png) ,并将小的赋给,如果修改了则
,并将小的赋给,如果修改了则![pred[V_j]=V_i](http://upload.wikimedia.org/wikipedia/zh/math/e/a/9/ea90c74edc895e97c36043b6fb121db0.png) (松弛操作)
(松弛操作) - 重复以上操作
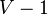 次
次 - 再重复操作3一次,如
![dist[V_j]>dist[V_i]+(V_i,V_j)](http://upload.wikimedia.org/wikipedia/zh/math/0/8/8/088a98fee2fca21f98bc6c3bd9642f0f.png) ,则此图存在负权环。[1]
,则此图存在负权环。[1]
伪代码表示
BellmanFord(G,s) for i = 0 to n-1 do dist[i]= ∞ Pred[i]= 0 dist[s]=0 for i = 0 to n-2 do foreach∈
do if
do
![dist[V_j]=dist[V_i]+(V_i,V_j)](http://upload.wikimedia.org/wikipedia/zh/math/3/d/f/3dff3bd90245081880bfe15f5a2946f1.png)
foreach
松弛
每次松弛操作实际上是对相邻节点的访问,第 次松弛操作保证了所有深度为n的路径最短。由于图的最短路径最长不会经过超过条边,所以可知贝尔曼-福特算法所得为最短路径。
次松弛操作保证了所有深度为n的路径最短。由于图的最短路径最长不会经过超过条边,所以可知贝尔曼-福特算法所得为最短路径。
负边权操作
与迪科斯彻算法不同的是,迪科斯彻算法的基本操作“拓展”是在深度上寻路,而“松弛”操作则是在广度上寻路,这就确定了贝尔曼-福特算法可以对负边进行操作而不会影响结果。
负权环判定
因为负权环可以无限制的降低总花费,所以如果发现第次操作仍可降低花销,就一定存在负权环。
优化
循环的提前跳出
在实际操作中,贝尔曼-福特算法经常会在未达到V-1次前就出解,V-1其实是最大值。于是可以在循环中设置判定,在某次循环不再进行松弛时,直接退出循环,进行负权环判定。
SPFA算法
SPFA算法优化在于,在贝尔曼-福特算法中,松弛操作必定只会发生在最短路径前导节点松弛成功过的节点上,SPFA用一个队列记录松弛过的节点,避免了冗余计算。[2]
SPFA(Shortest Path Faster Algorithm)是Bellman-Ford算法的一种队列实现,减少了不必要的冗余计算。
算法流程
算法大致流程是用一个队列来进行维护。 初始时将源加入队列。 每次从队列中取出一个元素,并对所有与他相邻的点进行松弛,若某个相邻的点松弛成功,则将其入队。 直到队列为空时算法结束。
这个算法,简单的说就是队列优化的bellman-ford,利用了每个点不会更新次数太多的特点发明的此算法
SPFA——Shortest Path Faster Algorithm,它可以在O(kE)的时间复杂度内求出源点到其他所有点的最短路径,可以处理负边。SPFA的实现甚至比Dijkstra或者Bellman_Ford还要简单:
设Dist代表S到I点的当前最短距离,Fa代表S到I的当前最短路径中I点之前的一个点的编号。开始时Dist全部为+∞,只有Dist[S]=0,Fa全部为0。
维护一个队列,里面存放所有需要进行迭代的点。初始时队列中只有一个点S。用一个布尔数组记录每个点是否处在队列中。
每次迭代,取出队头的点v,依次枚举从v出发的边v->u,设边的长度为len,判断Dist[v]+len是否小于Dist[u],若小于则改进Dist[u],将Fa[u]记为v,并且由于S到u的最短距离变小了,有可能u可以改进其它的点,所以若u不在队列中,就将它放入队尾。这样一直迭代下去直到队列变空,也就是S到所有的最短距离都确定下来,结束算法。若一个点入队次数超过n,则有负权环。
SPFA 在形式上和宽度优先搜索非常类似,不同的是宽度优先搜索中一个点出了队列就不可能重新进入队列,但是SPFA中一个点可能在出队列之后再次被放入队列,也就是一个点改进过其它的点之后,过了一段时间可能本身被改进,于是再次用来改进其它的点,这样反复迭代下去。设一个点用来作为迭代点对其它点进行改进的平均次数为k,有办法证明对于通常的情况,k在2左右。
SPFA算法(Shortest Path Faster Algorithm),也是求解单源最短路径问题的一种算法,用来解决:给定一个加权有向图G和源点s,对于图G中的任意一点v,求从s到v的最短路径。 SPFA算法是Bellman-Ford算法的一种队列实现,减少了不必要的冗余计算,他的基本算法和Bellman-Ford一样,并且用如下的方法改进: 1、第二步,不是枚举所有节点,而是通过队列来进行优化 设立一个先进先出的队列用来保存待优化的结点,优化时每次取出队首结点u,并且用u点当前的最短路径估计值对离开u点所指向的结点v进行松弛操作,如果v点的最短路径估计值有所调整,且v点不在当前的队列中,就将v点放入队尾。这样不断从队列中取出结点来进行松弛操作,直至队列空为止。 2、同时除了通过判断队列是否为空来结束循环,还可以通过下面的方法: 判断有无负环:如果某个点进入队列的次数超过V次则存在负环(SPFA无法处理带负环的图)。
SPFA算法有两个优化算法 SLF 和 LLL: SLF:Small Label First 策略,设要加入的节点是j,队首元素为i,若dist(j)<dist(i),则将j插入队首,否则插入队尾。 LLL:Large Label Last 策略,设队首元素为i,队列中所有dist值的平均值为x,若dist(i)>x则将i插入到队尾,查找下一元素,直到找到某一i使得dist(i)<=x,则将i出对进行松弛操作。 SLF 可使速度提高 15 ~ 20%;SLF + LLL 可提高约 50%。 在实际的应用中SPFA的算法时间效率不是很稳定,为了避免最坏情况的出现,通常使用效率更加稳定的Dijkstra算法。
伪代码
Procedure SPFA; Begin initialize-single-source(G,s); initialize-queue(Q); enqueue(Q,s); while not empty(Q) do begin u:=dequeue(Q); for each v∈adj[u] do begin tmp:=d[v]; relax(u,v); if (tmp<>d[v]) and (not v in Q) then enqueue(Q,v); end; end; End;
代码
最基本的SPFA
bool Relax(long &w,long m){return m<w?(w=m,1):0;}//"松弛"操作 const long maxV=1000,maxE=999000;//最大顶点数,最大边数 long m,H[maxV],D[maxV];//m为边数,初始化为0;H为链表头,初始化为-1;D为距离 struct Edge{long z,y,w;}E[maxE];//静态邻接表,w为权,y为边终点,z为静态指针 void addE(long x,long y,long w){E[m].y=y,E[m].w=w,E[m].z=H[x],H[x]=m++;}//加一条从x指向y,权为w的边 #include<cstring> #include<queue> void SPFA(long x=0){//默认计算从0点出发到达其他点的最短路 bool F[maxV]={};//初始为0的bool数组表示在不在队内 std::queue<long>Q;//初始空队列 for(memset(D,0x3f,sizeof(D)),D[x]=0,F[x]=1,Q.push(x);!Q.empty();F[x]=0,Q.pop())//迭代到队列再次变空 for(long i=H[x=Q.front()],y;~i;i=E[i].z)//对于所有与x相邻的边 if(Relax(D[y=E[i].y],E[i].w+D[x])&&!F[y]) F[y]=1,Q.push(y);//如果松弛成功,则要确保y已入队 }
SPFA(slf优化)
void Spfa() { d[S]=0; v[S]=true; deque <int> q; for(q.push_back(S);!q.empty();) { int x=q.front(); q.pop_front(); for(int k=head[x];k!=-1;k=el[k].next) { int y=el[k].y; if(d[y]>d[x]+el[k].c) { d[y]=d[x]+el[k].c; if(!v[y]) { v[y]=true; if(!q.empty()) { if(d[y]>d[q.front()]) q.push_back(y); else q.push_front(y); } else q.push_back(y); } } } v[x]=false; } return ; }
procedure spfa; begin fillchar(q,sizeof(q),0); h:=0; t:=0;//队列 fillchar(v,sizeof(v),false);//v[i]判断i是否在队列中 for i:=1 to n do dist[i]:=maxint;//初始化最小值 inc(t); q[t]:=1; v[1]:=true; dist[1]:=0;//这里把1作为源点 while h<>t do begin h:=(h mod n)+1; x:=q[h]; v[x]:=false; for i:=1 to n do if (cost[x,i]>0) and (dist[x]+cost[x,i]<dist[i]) then begin dist[i]:=dist[x]+cost[x,i]; if not(v[i]) then begin t:=(t mod n)+1; q[t]:=i; v[i]:=true; end; end; end; end;
void SPFA(void) { int i; queue list; list.insert(s); for(i=1;i<=n;i++) { if(s==i) continue; dist[i]=map[s][i]; way[i]=s; if(dist[i]) list.insert(i); } int p; while(!list.empty()) { p=list.fire(); for(i=1;i<=n;i++) if(map[p][i]&&(dist[i]>dist[p]+map[p][i]||!dist[i])&&i!=s) { dist[i]=dist[p]+map[p][i]; way[i]=p; if(!list.in(i)) list.insert(i); } } }
各种加上了注释
/* * 单源最短路算法SPFA,时间复杂度O(kE),k在一般情况下不大于2,对于每个顶点使用可以在O(VE)的时间内算出每对节点之间的最短路 * 使用了队列,对于任意在队列中的点连着的点进行松弛,同时将不在队列中的连着的点入队,直到队空则算法结束,最短路求出 * SPFA是Bellman-Ford的优化版,可以处理有负权边的情况 * 对于负环,我们可以证明每个点入队次数不会超过V,所以我们可以记录每个点的入队次数,如果超过V则表示其出现负环,算法结束 * 由于要对点的每一条边进行枚举,故采用邻接表时时间复杂度为O(kE),采用矩阵时时间复杂度为O(kV^2) */ #include<cstdio> #include<vector> #include<queue> #define MAXV 10000 #define INF 1000000000 //此处建议不要过大或过小,过大易导致运算时溢出,过小可能会被判定为真正的距离 using std::vector; using std::queue; struct Edge{ int v; //边权 int to; //连接的点 }; vector<Edge> e[MAXV]; //由于一般情况下E<<V*V,故在此选用了vector动态数组存储,也可以使用链表存储 int dist[MAXV]; //存储到原点0的距离,可以开二维数组存储每对节点之间的距离 int cnt[MAXV]; //记录入队次数,超过V则退出 queue<int> buff; //队列,用于存储在SPFA算法中的需要松弛的节点 bool done[MAXV]; //用于判断该节点是否已经在队列中 int V; //节点数 int E; //边数 bool spfa(const int st){ //返回值:TRUE为找到最短路返回,FALSE表示出现负环退出 for(int i=0;i<V;i++){ //初始化:将除了原点st的距离外的所有点到st的距离均赋上一个极大值 if(i==st){ dist[st]=0; //原点距离为0; continue; } dist[i]=INF; //非原点距离无穷大 } buff.push(st); //原点入队 done[st]=1; //标记原点已经入队 cnt[st]=1; //修改入队次数为1 while(!buff.empty()){ //队列非空,需要继续松弛 int tmp=buff.front(); //取出队首元素 for(int i=0;i<(int)e[tmp].size();i++){ //枚举该边连接的每一条边 Edge *t=&e[tmp][i]; //由于vector的寻址速度较慢,故在此进行一次优化 if(dist[tmp]+(*t).v<dist[(*t).to]){ //更改后距离更短,进行松弛操作 dist[(*t).to]=dist[tmp]+(*t).v; //更改边权值 if(!done[(*t).to]){ //没有入队,则将其入队 buff.push((*t).to); //将节点压入队列 done[(*t).to]=1; //标记节点已经入队 cnt[(*t).to]=1; //节点入队次数自增 if(cnt[(*t).to]>V){ //已经超过V次,出现负环 while(!buff.empty())buff.pop(); //清空队列,释放内存 return false; //返回FALSE } } } } buff.pop();//弹出队首节点 done[tmp]=0;//将队首节点标记为未入队 } return true; //返回TRUE } //算法结束 int main(){ //主函数 scanf("%d%d",&V,&E); //读入点数和边数 for(int i=0,x,y,l;i<E;i++){ scanf("%d%d%d",&x,&y,&l); //读入x,y,l表示从x->y有一条有向边长度为l Edge tmp; //设置一个临时变量,以便存入vector tmp.v=l; //设置边权 tmp.to=y; //设置连接节点 e[x].push_back(tmp); //将这条边压入x的表中 } if(!spfa(0)){ //出现负环 printf("出现负环,最短路不存在\n"); }else{ //存在最短路 printf("节点0到节点%d的最短距离为%d",V-1,dist[V-1]); } return 0; }
Floyd-Warshall算法(Floyd-Warshall algorithm)是解决任意两点间的最短路径的一种算法,可以正确处理有向图或负权的最短路径问题,同时也被用于计算有向图的传递闭包。
Floyd-Warshall算法的时间复杂度为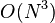 ,空间复杂度为
,空间复杂度为 。
。
[编辑]原理
Floyd-Warshall算法的原理是动态规划。
设 为从
为从 到
到 的只以
的只以 集合中的节点为中间节点的最短路径的长度。
集合中的节点为中间节点的最短路径的长度。
- 若最短路径经过点k,则
 ;
; - 若最短路径不经过点k,则
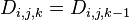 。
。
因此, 。
。
在实际算法中,为了节约空间,可以直接在原来空间上进行迭代,这样空间可降至二维。(见下面的算法描述)
[编辑]算法描述
Floyd-Warshall算法的描述如下:
for k ← 1 to n do
for i ← 1 to n do
for j ← 1 to n do
if (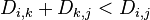 ) then
) then
 ←
← 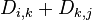 ;
;
其中表示由点到点的代价,当为 ∞ 表示两点之间没有任何连接。















 1048
1048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









