






0.简介
本推文介绍了一篇由西湖大学、北京大学、南京大学、哈尔滨工业大学以及松鼠AI联合发布的论文《AutoSurvey: Large Language Models Can Automatically Write Surveys》,已被NeurIPS 2024录用。论文提出了一种基于大型语言模型(LLM)的自动化撰写综述方法。通过初始检索、主题生成、分段撰写、内容整合和多轮评估迭代,能够快速生成高质量的学术综述。AutoSurvey通过系统化的流程,在确保引用准确性和内容质量的同时,显著提升了综述生成的效率。实验结果显示,AutoSurvey生成的综述质量接近人工水平,为科研人员在信息量急剧增长、发展迅速的领域中提供了高效且可靠的综述生成方案。
推文作者为许东舟,审校为黄星宇和邱雪。
论文链接:https://arxiv.org/abs/2406.10252
代码链接:https://github.com/AutoSurveys/AutoSurvey?tab=readme-ov-file
1.会议介绍

第38届神经信息处理系统大会(NeurIPS)将于12月9日至15日在加拿大温哥华隆重举行。NeurIPS始于1987年,是机器学习和人工智能领域的顶级学术会议之一,每年举办一次。大会涵盖了深度学习、强化学习、优化算法、神经网络、认知科学等多个热门研究方向,并吸引了来自世界各地的研究人员和从业者。NeurIPS为中国人工智能学会(CAAI)和中国计算机学会(CCF)A类会议,与国际机器学习会议(ICML)、国际学习表示会议(ICLR)并称为人工智能领域难度最大、水平最高、影响力最强的“三大会议”。
2.研究背景及主要贡献
综述论文在学术界中具有重要作用,它能系统地概述最新的研究进展,帮助研究人员掌握领域发展趋势。然而,如图1所示,随着信息量急剧增长,特别是在人工智能领域,人工撰写综述变得越来越困难、耗时,这导致许多领域缺乏全面系统的综述。
LLM凭借强大的文本理解和生成能力,为自动化综述生成带来了新的可能。然而,LLM在应用中仍面临诸如上下文窗口限制、参数化知识限制以及缺乏可靠的评估标准等关键挑战。为应对这些问题,论文提出了AutoSurvey,并使用来自arXiv数据库的53万篇计算机科学领域的论文进行训练,以生成全面的文献综述。
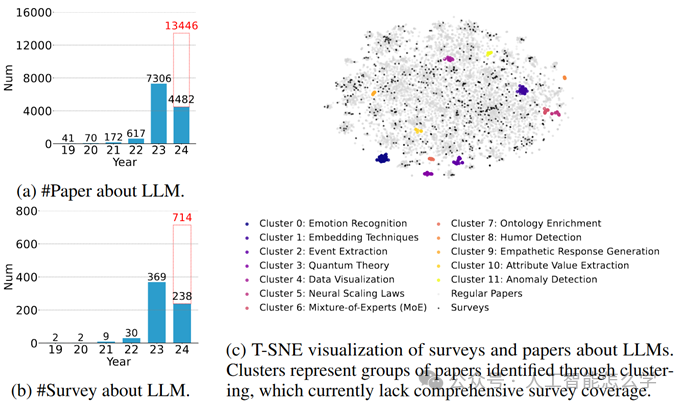
图1 2019年至2024年间LLM相关论文(a)和综述(b)在arXiv上的增长趋势,并附有T-SNE可视化。
2024年的数据截至4月,红色柱状表示全年的预测数量。尽管综述数量总体增长,可视化揭示了在一些领域中仍缺乏全面的综述。T-SNE图中的聚类表示通过聚类分析识别的论文组,这些领域目前缺乏综述覆盖。
本文主要贡献如下:
1.逻辑并行生成:
采用两阶段生成方法,多个LLM并行生成详尽的大纲和内容,然后通过系统修订确保一致性,形成结构清晰的最终文档。
2.实时知识更新:
加入了基于检索增强生成(RAG)的实时知识更新机制,确保综述内容反映最新的研究成果。当用户输入综述主题时,可以通过RAG系统检索最新的相关论文,为生成大纲提供基础。
3.多模型评估:
使用了多个LLM作为“评审员”对生成内容进行初步评估。这种方法生成的评估指标经人类专家细化,确保高覆盖度、结构合理性和与主题的契合度,符合学术标准。
3.方法
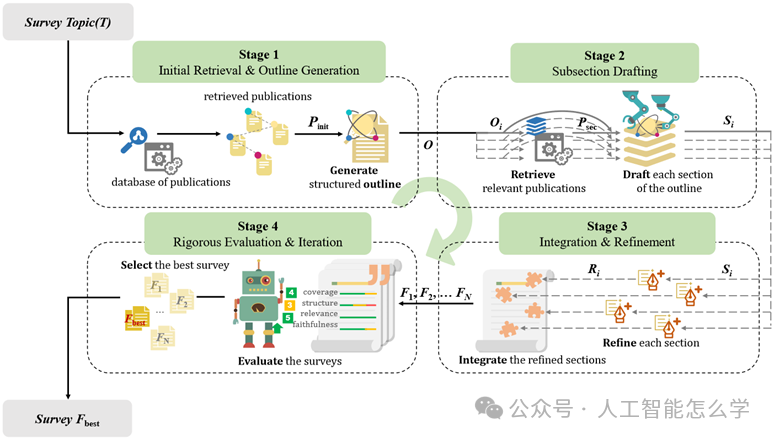
图2 AutoSurvey生成全面综述的流程
图2展示了AutoSurvey用于自动生成文献综述的方法。该方法系统地分为四个不同的阶段:初始检索与大纲生成、子章节草拟、集成与精炼、严格评估与迭代。每个阶段都经过精心设计,针对综述生成中的具体挑战,从而提升综述文档的生成效率和质量。各阶段的介绍如下:
阶段1:初始检索与大纲生成
AutoSurvey利用基于嵌入的检索技术,扫描论文数据库,识别与指定的综述主题T最相关的论文。将检索得到的论文集合Pinit生成一个结构化的大纲,确保对主题的全面覆盖和综述的逻辑结构。模型基于每个片段生成一个大纲,并将这些大纲合并为最终的大纲。最终,整个综述的大纲表示为:
阶段2:子章节起草
在这个阶段,特定的LLM并行起草每个章节的内容。在加快了写作过程同时确保每个章节内容的详细性和主题的聚焦性,还能够遵循大纲中设定的主题边界。在撰写每个子章节时,针对该章节的子大纲Oi将用于检索相关参考论文Psec,从而提供与章节主题更贴合的信息。在撰写过程中,模型需引用提供的参考文献来支持生成的内容。然后生成子章节Si。
阶段3:集成与精炼
对每个子章节Si进行单独精炼,提高可读性、消除冗余,并确保整体内容的流畅性。然后,将各部分合并成连贯的文档F,以保持综述的逻辑流畅性和一致性。模型还需核查文中引用的准确性,修正引用错误。
阶段4:评估和迭代
通过多个LLM作为“评审员”,对综述文档进行多方面评估。根据评估结果进行进一步的精炼,确保综述达到较高的学术标准。在多个候选文档F1, F2, …, FN中选择最佳综述作为最终输出结果。
4.实验
1.实施细节
文中对AutoSurvey生成的综述进行了全面评估,并将它和传统的综述撰写方法进行了比较。采用了这些评估指标如下:
(1)综述生成速度
文中使用了一个数学模型来估算人工撰写文档所需的时间,包括研究和数据收集的准备时间Tr、实际写作时间Tw(Tw= L / (E×M))、编辑和修订时间Te(Te = 1/2 * Tw)、文档长度L、专家数量E、专家写作速度M。
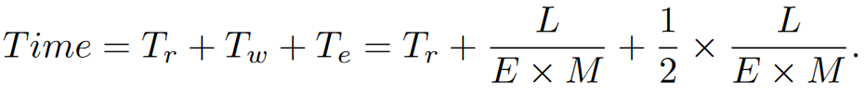
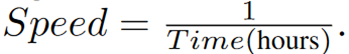
(2)引用质量
·引用召回率:衡量生成文本中的所有语句是否能得到引用段落的支持
·引用精确率:评估是否存在不相关的引用,确保引文具有针对性。
(3)内容质量
·覆盖率:评估综述对主题各个方面的涵盖程度。
·结构:评估每个章节的逻辑组织与连贯性。
·相关性:确保内容与研究主题的吻合程度。
2.实验结果
表1 基于简单RAG的LLM生成、人类撰写和AutoSurvey的结果对比。用于评估的人类撰写的综述在检索过程中被排除。
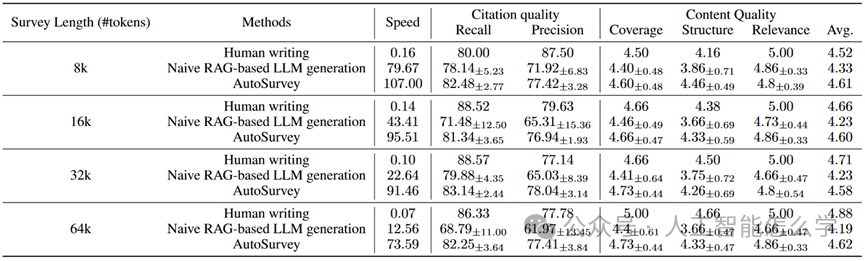
表1展示了在不同长度综述(8k、16k、32k和64k tokens)的情况下,人类撰写、基于简单RAG的LLM生成和AutoSurvey在速度、引用质量和内容质量等指标上的对比结果。首先在生成速度上,AutoSurvey表现出了显著的优势,尤其在处理较长内容时。例如在64k-token的综述生成中,AutoSurvey的速度高达每小时73.59篇,而人类撰写仅为0.07篇,基于简单RAG的LLM生成为12.56篇。引用质量方面,AutoSurvey在所有内容长度上都优于基于简单RAG的LLM生成,且接近人工撰写的水平。在内容质量上,AutoSurvey在覆盖度、结构和相关性评分方面几乎与人工撰写持平,且在大多数情况下均优于基于简单RAG的LLM生成。
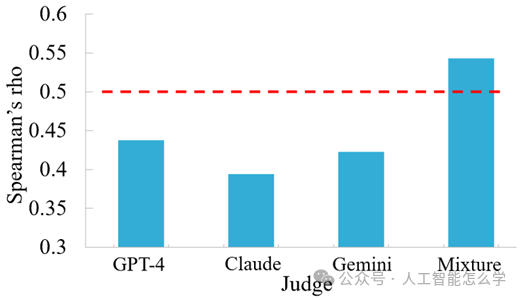
图 3 Spearman相关系数(rho)值,表示LLM评分与人类专家评分之间的相关性。超过0.3的值表示正相关,而超过0.5的值表示强正相关。
为了验证评估方法与人工评估的一致性,研究团队邀请人类专家与自动评估系统进行对比。将人工专家的评分标准提供给评估系统,确保评分的一致性。专家们对生成的20篇综述进行评分,并使用Spearman等级相关系数来衡量LLM与人类专家评分之间的一致性。
如图3所示,LLM与人类专家之间在分数上呈正相关性,多个模型的组合获得了超过0.5的最高相关性。由此可以证明,文中的评估方法在一定程度上符合人类偏好,能够可靠地模拟人类判断。
5.总结与展望
文中提出了一种基于大模型的自动化文献综述生成方法——AutoSurvey。该方法通过一套系统的流程,有效解决了上下文窗口限制和参数化知识等关键问题。实验结果表明,AutoSurvey在引用质量和内容质量方面明显优于基于简单RAG的LLM生成,并接近于人工撰写的水平,同时具备出色的生成效率。尽管AutoSurvey在生成过程中仍存在一定的局限性,并且需要关注潜在的社会影响和伦理问题,但该方法为快速发展的领域提供了一个可扩展且有效的文献综述解决方案。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









