






一、会议介绍
CVPR(IEEE Conference on Computer Vision and Pattern Recognition)是计算机视觉和模式识别领域的顶级学术会议之一,每年举办一次,与ICCV和ECCV并称为计算机视觉领域的三大顶级会议。CVPR 2025的会议时间为2025年6月11日至6月15日,地点在美国田纳西州纳什维尔音乐城中心。
会议官网:https://cvpr.thecvf.com/
二、CVPR 2025录用情况
根据2月27日CVPR官方发布的结果,会议今年收到了13008篇有效论文提交,有2878篇被接收,整体录用率约为 22.1%。表1和图1呈现了近五年CVPR的录用情况及变化趋势。从图表中不难看出,与往年相比, CVPR 2025的论文提交数量显著增加,并创造历史新高。然而,与之形成对比的是,近几年的录用率有所降低。这体现出计算机视觉领域的研究热度不断攀升的同时,会议对论文质量的把控愈发严格,评审标准也不断提高。
表1 近五年CVPR录用情况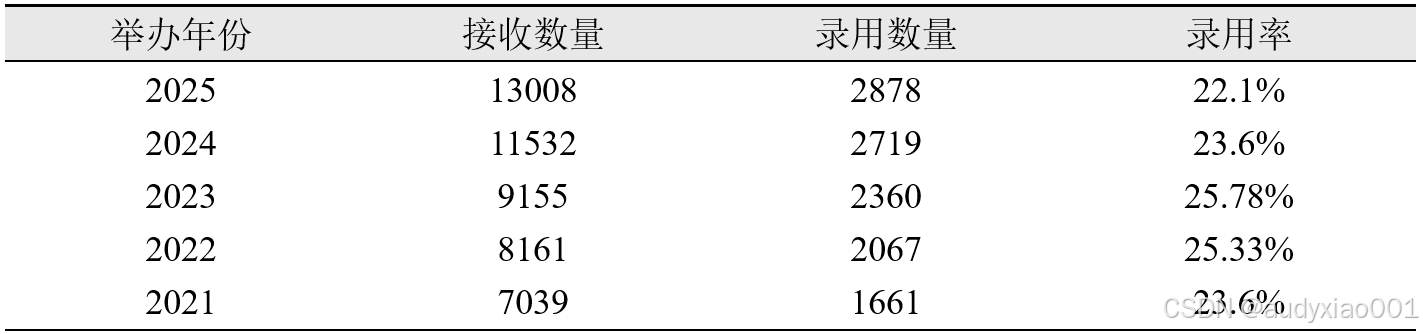
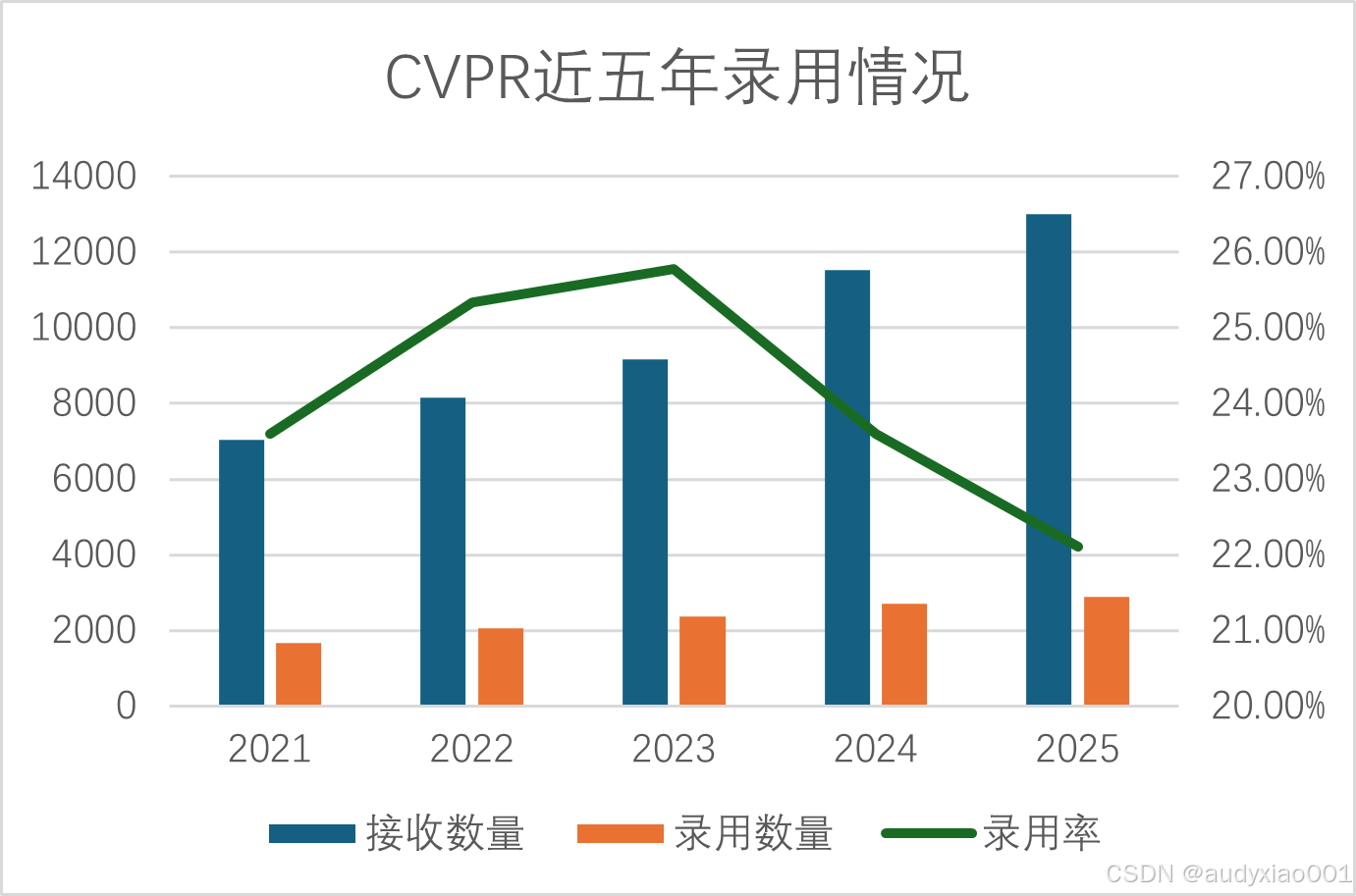
图1 CVPR近五年录用情况趋势图
三、热点分析
接下来,作者将对CVPR 2025被录用的2878篇论文标题中出现的高频词进行分析。CVPR 2025的20个高频词汇如表2所示。
表2 CVPR 2025高频主题词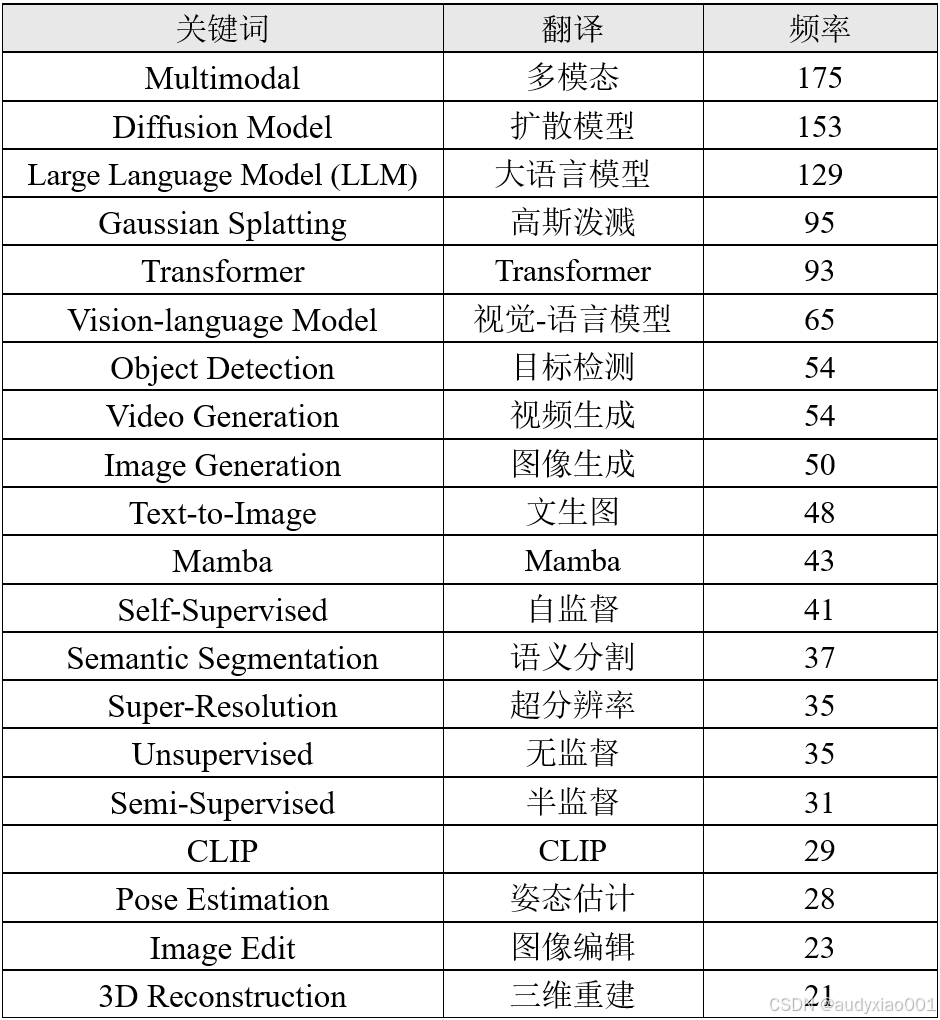

图2 由CVPR 2025录用论文标题中高频词汇生成的词云图
四、热门研究领域分析
(1)多模态(Multimodal)
多模态指的是融合多种不同类型的数据(如文本、图像、音频、视频、传感器数据)进行信息处理和学习的技术。多模态模型能够理解和生成跨模态内容,例如文本生成图像(如DALL·E)、语音转文本(ASR)、视频字幕生成等。当前,Transformer架构在多模态学习中得到了广泛应用,典型的多模态模型包括CLIP、GPT-4V等。多模态技术能够帮助计算机理解复杂的场景交互,因此广泛应用于智能搜索、内容推荐、医疗诊断、自动驾驶等领域。
示例论文:Caffagni D, Sarto S, Cornia M, et al. Recurrence-Enhanced Vision-and-Language Transformers for Robust Multimodal Document Retrieval[J]. arXiv preprint arXiv:2503.01980, 2025.
论文下载:https://arxiv.org/abs/2503.01980
(2)扩散模型(Diffusion Models)
扩散模型是一种基于概率生成的深度学习模型,主要用于图像、音频和文本的生成任务。其核心思想是逐步向数据添加噪声,然后训练一个神经网络用于逆向去噪,从而生成高质量的新数据。扩散模型在图像生成、视频生成和音频合成等领域取得了突破性进展,相比传统的GAN(生成对抗网络),它能生成更真实、更稳定的样本。近年来,扩散模型被用于艺术创作、医学影像重建和药物分子生成等多个领域,展现出强大的应用潜力。
示例论文:Yeganeh Y, Charisiadis I, Hasny M, et al. Latent Drifting in Diffusion Models for Counterfactual Medical Image Synthesis[J]. arXiv preprint arXiv:2412.20651, 2024.
全文下载:https://arxiv.org/abs/2412.20651
(3)大语言模型(Large Language Models)
大语言模型是一类基于深度学习的自然语言处理(NLP)模型,通常采用神经网络架构(如Transformer)并在海量文本数据上进行训练,通过数十亿乃至万亿级别的参数,使其能够理解和生成自然语言。典型的大语言模型包括GPT-4、BERT、LLaMA等,它们可用于文本生成、翻译、代码生成、对话系统、信息检索等任务。大语言模型的广泛应用推动了智能客服、自动摘要、法律分析、学术研究和医疗诊断等多个领域的发展。
示例论文:Huang Z, Zhuang S, Fu C, et al. WeGen: A Unified Model for Interactive Multimodal Generation as We Chat[J]. arXiv preprint arXiv:2503.01115, 2025.
全文下载:https://arxiv.org/abs/2503.01115
(4)高斯泼溅(Gaussian Splatting)
高斯泼溅是一种全新的基于3D高斯分布的点云渲染方法,主要用于高效逼真的三维场景重建。它通过在三维空间中分布大量高斯点,每个点具有颜色、透明度和形状参数,然后利用光照计算来合成逼真的图像。相比传统的NeRF(神经辐射场),高斯泼溅具有计算效率更高、渲染速度更快的特点,在AR/VR、游戏开发、数字孪生等领域有广泛的应用。
示例论文:Feng Y, Feng X, Shang Y, et al. Gaussian splashing: Unified particles for versatile motion synthesis and rendering[J]. arXiv preprint arXiv:2401.15318, 2024.
全文下载:https://arxiv.org/abs/2401.15318
(5)视觉-语言模型(Vision-Language Model)
视觉语言模型是一类融合计算机视觉(CV) 和 自然语言处理(NLP) 的深度学习模型,旨在同时理解图像和文本信息。VLM 通过学习图像和文本之间的关系,使AI具备跨模态理解能力,例如图像描述生成、视觉问答(VQA)、文本生成图像(如 DALL·E) 等任务。
示例论文:Wu S, Zhang J, Zeng P, et al. Skip Tuning: Pre-trained Vision-Language Models are Effective and Efficient Adapters Themselves[J]. arXiv preprint arXiv:2412.11509, 2024.
全文下载:https://arxiv.org/abs/2412.11509
上述内容根据CVPR 2025录用列表分析得出,仅代表作者本人观点,希望能为读者追踪计算机视觉与模式识别领域的研究热点带来一些帮助。

















 527
527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









