







Visual Studio 2013使用Libsvm训练数据
最近在做周志华《机器学习》上面的习题时,需要使用linsvm库对西瓜数据集使用线性核和高斯核进行训练,比较其支持向量的差别,下面就简单的介绍一下,训练的过程。
在使用libsvm之前我们需要去官网下载最新的版本libsvm-3.22 libSVM的下载地址:http://www.csie.ntu.edu.tw/~cjlin/libsvm/
下载解压后文件如下:
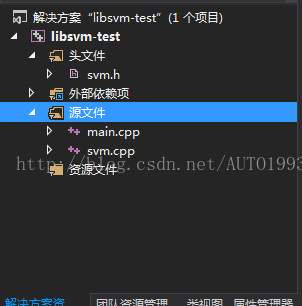
新建VS2013工程,将上面下载文件中的 svm.cpp和svm.h添加到新建的工程中:
环境准备就这么简单,现在就可以开始编写代码文件main.cpp,读取数据文件,然后训练svm,下面是西瓜数据集3.0α
0.697 0.460 1
0.774 0.376 1
0.634 0.264 1
0.608 0.318 1
0.556 0.215 1
0.403 0.237 1
0.481 0.149 1
0.437 0.211 1
0.666 0.091 0
0.243 0.267 0
0.245 0.057 0
0.343 0.099 0
0.639 0.161 0
0.657 0.198 0
0.360 0.370 0
0.593 0.042 0
0.719 0.103 0#include<iostream>
#include<fstream>
#include<vector>
#include"svm.h"
#define PropertyNum 2 //数据集单个样本的属性个数,即特征值得个数
#define ModelSavePath "svm.xml"//模型文件保存路径名称
class ML_SVM
{
public:
ML_SVM(const std::string &train_data_path)
{
TrainDataFilename = train_data_path;
};
void Train();
void Predict();
public:
svm_model *svmModel;
private:
void setParam();
void readTrainData();
private:
std::string TrainDataFilename;
std::vector<svm_node*>data;
std::vector<float>label;
svm_parameter param;
svm_problem prob;
int SampleNum;
};
void ML_SVM::readTrainData()
{
std::fstream Data;
Data.open(TrainDataFilename);
std::cout << "train data read begin..." << std::endl;
SampleNum = 0;
while (!Data.eof())
{
/*PropertyNum表示属性个数,即特征的维度*/
svm_node* features = new svm_node[PropertyNum + 1];//因为需要结束标记,因此申请空间时特征维度+1
/*libSVM的数据格式:Label ,1:value 2:value ….*/
for (int k = 0; k < PropertyNum; k++)
{
double value = 0;
Data >> value;
features[k].index = k + 1;//标号,从1开始
features[k].value = value;//特征值,属性值
}
features[PropertyNum].index = -1;//结束标记
data.push_back(features);
/*读标签*/
double labelTemp; Data >> labelTemp;
label.push_back(labelTemp);
SampleNum++;
}
std::cout << "the number of train data is " << SampleNum << std::endl;
std::cout << "train data read end" << std::endl;
Data.close();
}
void ML_SVM::setParam()
{
param.svm_type = C_SVC;
param.kernel_type = LINEAR;
param.degree = 3;
param.gamma = 0.5;
param.coef0 = 0;
param.nu = 0.5;
param.cache_size = 40;
param.C = 1;
param.eps = 1e-3;
param.p = 0.1;
param.shrinking = 1;
param.nr_weight = 0;
param.weight = NULL;
param.weight_label = NULL;
}
void ML_SVM::Train()
{
/*加载训练数据*/
readTrainData();
prob.l = SampleNum;//训练样本个数
prob.x = new svm_node *[prob.l];//训练数据train data(features of all the training samples);
prob.y = new double[prob.l];//训练数据标签data label(label of all the training samples);
for (int i = 0; i < SampleNum; i++)
{
prob.x[i] = data[i];
prob.y[i] = label[i];
}
/*设置训练参数*/
setParam();
/*开始训练SVM*/
std::cout << "start training..." << std::endl;
svmModel = svm_train(&prob, ¶m);
svm_save_model(ModelSavePath, svmModel);
std::cout << "model save done!" << std::endl;
}
void ML_SVM::Predict()
{
}
int main()
{
ML_SVM svm("trainData.txt");
svm.Train();
int total_SV= svm.svmModel->l;;//支持向量的个数;
std::cout << "the total sv is " << total_SV<< std::endl;
svm_node** sv; sv = svm.svmModel->SV;
printf("每个类的支持向量机的个数: %d %d\n", svm.svmModel->nSV[0], svm.svmModel->nSV[1]);
return 0;
}下面是训练结束后生成的svm.xml文件的内容:
线性核训练文件内容如下:
svm_type c_svc
kernel_type linear
nr_class 2
total_sv 16
rho 1.1789
label 1 0
probA 2.03635
probB -0.172627
nr_sv 8 8
SV
1 1:0.697 2:0.46
1 1:0.774 2:0.376
1 1:0.634 2:0.264
1 1:0.608 2:0.318
1 1:0.556 2:0.215
1 1:0.403 2:0.237
1 1:0.481 2:0.149
1 1:0.437 2:0.211
-1 1:0.666 2:0.091
-1 1:0.243 2:0.267
-1 1:0.343 2:0.099
-1 1:0.639 2:0.161
-1 1:0.657 2:0.198
-1 1:0.36 2:0.37
-1 1:0.593 2:0.042
-1 1:0.719 2:0.103 svm_type c_svc
kernel_type rbf
gamma 0.5
nr_class 2
total_sv 16
rho 0.856587
label 1 0
probA 2.02543
probB -0.183112
nr_sv 8 8
SV
1 1:0.697 2:0.46
1 1:0.774 2:0.376
1 1:0.634 2:0.264
1 1:0.608 2:0.318
1 1:0.556 2:0.215
1 1:0.403 2:0.237
1 1:0.481 2:0.149
1 1:0.437 2:0.211
-1 1:0.666 2:0.091
-1 1:0.243 2:0.267
-1 1:0.343 2:0.099
-1 1:0.639 2:0.161
-1 1:0.657 2:0.198
-1 1:0.36 2:0.37
-1 1:0.593 2:0.042
-1 1:0.719 2:0.103 /**********svm 训练文件参数说明*****************
svm_type c_svc//所选择的svm类型,默认为c_svc
kernel_type rbf//训练采用的核函数类型,此处为RBF核
gamma 0.0769231//RBF核的参数γ
nr_class 2//类别数,此处为两分类问题
total_sv 132//支持向量总个数
rho 0.424462//判决函数的偏置项b
label 1 -1//原始文件中的类别标识
nr_sv 64 68//每个类的支持向量机的个数
SV//以下为各个类的权系数及相应的支持向量
***********************************/从上面可以看出两种核函数训练得到的支持向量是一样的。和某博客给出的习题答案是一致的。
参考资料:
http://blog.csdn.net/zy_zhengyang/article/details/45009431
http://blog.csdn.net/u014691453/article/details/40393137
http://blog.csdn.net/lhanchao/article/details/53367532















 912
912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









