









Regionlets for Generic Object Detection
本文是对这篇文章的翻译和自我理解,文章下载地址:http://download.csdn.net/detail/autocyz/8569687
摘要:
对于一般物体检测,现在面对的问题是如何用比较简单的计算方法来解决物体的角度的变化所带来的识别问题。要想解决这种问题,那就必须要求有一种灵活的物体描述方法,并且这种方法对于处在不同位置的物体均能进行很好的评判。
基于这种情况,作者采用级联的boosting分类器,建立了一种物体分类模型。这种模型包含了不同的特征类型。而这些特征类型是通过计算局部区域特征得到的。这些特征被称作regionlet。
regionlet是基本特征区域,它是根据任意分辨率的检测窗口成比例定义的。将那些具有相对位置关系的regionlet放在一组中,用来描绘物体中的纹理分布。
为了适应物体的形变,作者将那些regionlets特征合并到一个一维的特征中。然后作者计算物体的边框,通过这些边框来获取分割的起点,并将起点的个数限制在数千个。

Introduction:
虽然对于刚性物体(形状不会变化或者变化较小)的检测取得了不小的成功,但是一般物体的检测任然有很多问题需要解决。目前主要的问题仍旧是物体的形变带来的识别问题。而造成这种问题的原因又有两种,一种是物体是本身的形变,比如猫的,其不同的动作都会造成其模样的变化;另一种原因是因为视觉的角度和距离变化导致的,比如车辆,虽然其模样不会改变,但是站在不同的角度和距离,看到的模样也是不一样的。
上面所说的这些问题,也说明了对于物体种类表达的一个比较重要的问题。一方面,一个能够很好的描述刚性物体特征的模板可能几乎不能够适用于会形变的物体。另一方面呢,一个有很好的形变容忍性的模板可能会导致在检测刚性物体时定位不准或者相对的错误率。
在文章中,作者提出了一种新的一般物体表达策略,这种新的策略将自适应的形变解决方法融合进分类器的学习和特征提取中。在这中方法中,采用级联的boosting分类器来对物体框进行分类。在boosting中,每一个弱分类器都以方框内的区域特征响应作为输入,并且这些区域依次用一组子区域进行表达,这些子区域就称之为regionlets。当然,这些regionlets并不是随机选取的,而是用boosting从一个巨大的候选池中挑选出来的。
一方面,regionlets在区域中的相对位置以及区域在物体框中的位置都是比较稳定的,因此这种regionlet表达方法能够建立比较细致的空间表达模型。另一方面,每一组regionlets的特征响应都被合并成一维的特征,这个一维的特征对于局部形变有比较好的鲁棒性。
另外,为了提高regionlet模型的灵活性,作者采用了不同的大小和长宽比的regionlet,同时,采取利用选择性搜索策略,这样获取的候选框的数量在数千数量级,远远比采用滑动窗口方法的数量少。
这篇文章主要的贡献有两点:1、提出了regionlet的方法,这种方法能够从任意的框中灵活的提取特征。2、对于一类物体来说,基于regionlet的表达方式,不仅在物体内建立了相对空间分布模型,而且通过结合boosting选取的regionlets以及将一组regionlets聚合在一起的特征响应这两种方法,使其能够很好的适应物体变化的情况,尤其是形变。
regionlet的定义:
对于物体检测,物体的分类本质上来说是由分类器来定义的。而这个分类器包含了物体的外貌特征和空间分布。
物体的外貌特征一般是从包含物体的矩形区域中提取的。在物体内部,用小的矩形框提取特征,这种特征有很好的局部性,但是对于形变的处理较差。用大的矩形框提取,虽然对形变有很好的处理能力,但是又不能很好的精确定位。然而,当物体发生较大的变化,尤其是形变时,大的矩形框也可能也无法提取物体特征了。因为,在矩形框的内部,可能有些部分的信息是无用的,甚至是有干扰性的。
鉴于上面的情况,作者就想,能不能找到一些子区域——regionlets,将这些子区域作为特征提取的基本模板,然后将这些模板放在一组中,这样的一组特征能够更加灵活的描述不同的物体,并且对于形变也有很好的容忍性。

以上面的图为例,图中的第一列是待检测的物体——人,图中第二列中黑色方框代表的是原图的大小,起内部的蓝色方框是提取特征的区域——R,这里提取人的特征主要是提取人的上半身的特征。蓝色框内的橙色矩形框是提取特征的子区域——regionlet,这里的regionlet是取手所在的位置,因为人虽然有形变,但是人的手形变的程度较小。将第二列中的三个regionlet组合在一起,就变成了最后一幅图中r1,r2,r3,即regionlets。
下面来仔细的分析一下这幅图:首先是regionlet的选取,这里是选取了人比较有代表性的手,这三幅图人的身体都是有形变的,而形变的最大因素便是手位置的变化。但是注意到手的位置虽然发生了变化,但是手本身的形变在图中看来是比较小的。这一组regionlet的选取比较巧妙,每一个单独的regionlet有很好的代表性,能够比较的突出的表现人的特征,而组合在一组的regionlets,对于在不同位置的手的情况均能够准确的提取手的特征,能够很好的处理形变的情况,一举两得,当然这只是一幅简单的示意图,在实际的算法中,一个R区域,不会只有一个regionlet的,并且也不是这样通过人为的分析特征来判定regionlet的位置的,至于如何确定这些regionlets的,后面会讲。
Region中特征的提取:
从region——R中提取特征的过程主要有两步:
第一步:分别提取每个regionlet的HOG和LBP特征。
第二步:将这些从regionlets中提取的特征组合在一起。
第一步 比较简单,不做赘述,这里详细的讲一下第二步的实现过程。
作者将regionlet提取的特征组合在一起的过程其实是一个特征筛选的过程,他是在regionlets中选出最能代表region特征的项。
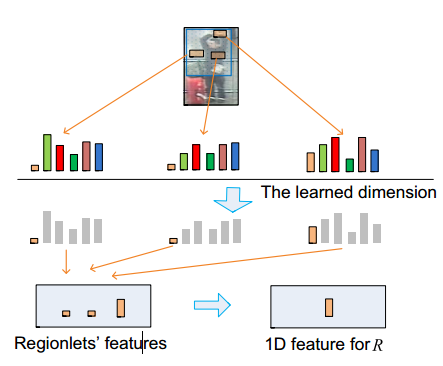
如上图,作者先提取这些regionlets的串联低维特征特征,得到了the learned dimension那一项,然后通过一个boosting学习机,选出最与众不同的一项。便发现第一项是最与众不同不同的,因为在含有手的那个regionlet区域,其第一项的特征明显高于另外两个regionlet的第一项。最后作者就选用这三个regionlet的第一项中有最强的特征响应的那一项作为整个区域R的特征表达。
尺度归一化的检测窗口:
作者的regionlet方法是在物体候选框中实现的。候选框的获取是参考这篇论文K. E. A. Van de Sande, J. R. R. Uijlings, T. Gevers, and A. W. M. Smeulders. Segmentation as selective search for object recognition. In ICCV, 2011.这里不做赘述。
采用了上诉的候选框获取方法,获取了候选框之后,便要用检测窗口对候选区域进行检测了。在检测之前,作者对检测窗口进行了尺度归一化处理,处理方法如下:
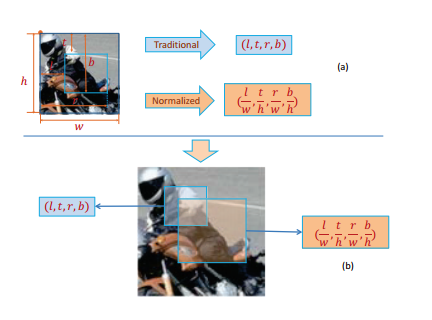
如上图所示,对于图(a),其图为一个小的候选窗口,其大小为(h,w),现在用大小为(l,t,r,b)的检测框对此候选窗口进行检测。当来了一个比较大的候选窗口时,假设其大小为(h’,w’)对应上图的(b),此时若仍旧采用大小为(l,t,r,b)显然检测相对位置变了,这不符合regionlet的相对位置不变的特性,因此作者首先在图(a)中对检测窗口进行归一化,求得归一化的比例尺度(l/w,t/h,r/w,b/h),当检测窗口变成了大的(h’,w’)时,其检测窗口就变成了(lw’/w,th’/h,rw’/w,bh’/h)。这种归一化窗口的方法能够在不同尺寸的图像上直接进行检测。
建立region和regionlets pool:
作者建立了一个过完备的region和regionlet pool,里面包含了不同大小、不同位置、不同长宽比的region和regionlet。产生方法如下:

方法中的R’= (l’, t’, r’, b’, k) ,k代表region的低维特征向量的第K个元素。















 894
894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









