









 本文详细介绍了对比损失函数(Contrastive Loss),这是在孪生神经网络(Siamese Network)中常用的损失函数之一。该函数可以有效地处理配对数据间的相似性关系,通过调整样本特征的欧氏距离来优化模型,确保相似样本在特征空间中保持接近,而不相似的样本则保持距离。
本文详细介绍了对比损失函数(Contrastive Loss),这是在孪生神经网络(Siamese Network)中常用的损失函数之一。该函数可以有效地处理配对数据间的相似性关系,通过调整样本特征的欧氏距离来优化模型,确保相似样本在特征空间中保持接近,而不相似的样本则保持距离。
Contrastive Loss (对比损失)
在caffe的孪生神经网络(siamese network)中,其采用的损失函数是contrastive loss,这种损失函数可以有效的处理孪生神经网络中的paired data的关系。contrastive loss的表达式如下:
L=12N∑n=1Nyd2+(1−y)max(margin−d,0)2
其中
d=||an−bn||2
,代表两个样本特征的欧氏距离,y为两个样本是否匹配的标签,y=1代表两个样本相似或者匹配,y=0则代表不匹配,margin为设定的阈值。
这种损失函数最初来源于Yann LeCun的Dimensionality Reduction by Learning an Invariant Mapping,主要是用在降维中,即本来相似的样本,在经过降维(特征提取)后,在特征空间中,两个样本仍旧相似;而原本不相似的样本,在经过降维后,在特征空间中,两个样本仍旧不相似。
观察上述的contrastive loss的表达式可以发现,这种损失函数可以很好的表达成对样本的匹配程度,也能够很好用于训练提取特征的模型。当y=1(即样本相似)时,损失函数只剩下 ∑yd2 ,即原本相似的样本,如果在特征空间的欧式距离较大,则说明当前的模型不好,因此加大损失。而当y=0时(即样本不相似)时,损失函数为 ∑(1−y)max(margin−d,0)2 ,即当样本不相似时,其特征空间的欧式距离反而小的话,损失值会变大,这也正好符号我们的要求。
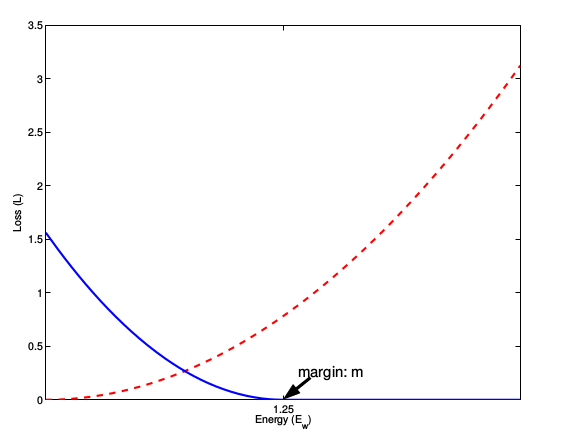
这张图表示的就是损失函数值与样本特征的欧式距离之间的关系,其中红色虚线表示的是相似样本的损失值,蓝色实线表示的不相似样本的损失值。

















 3452
3452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









