







 本文介绍了如何在小样本情况下利用CNN进行特定任务,特别是将CNN应用于视觉跟踪。通过序贯集成学习方法,作者解决了CNN在跟踪中易过拟合的问题,提出STCT模型,结合预训练和在线更新的CNN,提升了跟踪性能。通过选择训练误差最低的基分类器组成集成分类器,不断更新优化,增强模型的多样性和泛化能力。
本文介绍了如何在小样本情况下利用CNN进行特定任务,特别是将CNN应用于视觉跟踪。通过序贯集成学习方法,作者解决了CNN在跟踪中易过拟合的问题,提出STCT模型,结合预训练和在线更新的CNN,提升了跟踪性能。通过选择训练误差最低的基分类器组成集成分类器,不断更新优化,增强模型的多样性和泛化能力。
1、怎么将CNN用在特定的任务中
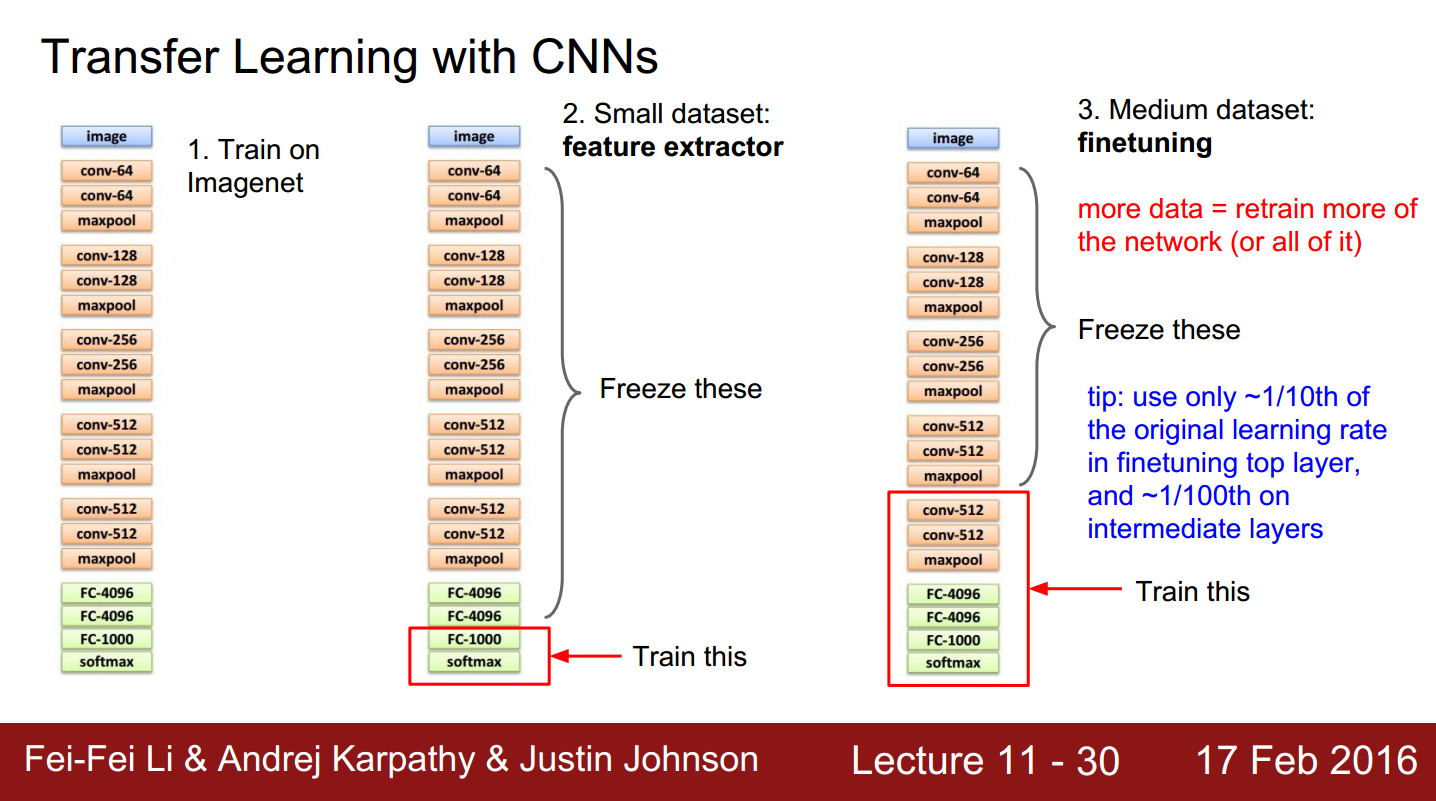
图1. 将CNN用在特定的任务中
众所周知CNN的使用往往需要大量的训练样本,但是我们在很多特定任务中是没法获得像imageNet那样庞大的样本库,因此如何在小样本中使用CNN是一个难题。后来很多学者经过研究发现CNN的模型有很好的泛化性能,即在大样本库中训练好的CNN模型对于特定的任务也有不错的性能。一些学者根据这个特性提出了fine-tune的方法,
如图1所示。我们首先在big dataset上训练好CNN模型,然后用我们特定任务中获得的样本对CNN模型进行微调(fine-tune),上图中最左侧是经典的CNN模型VGGnet,我们用imagenet数据库对其训练(其实是别人训练好,我们直接把训练结果拿来用);
如果我们的训练样本数量不少,如上图右侧部分所示,那么我们可以用自己的样本更新更多的层,比如上图右侧中,不仅更新了全连接层,还更新了pooling层以及卷积层。
2、将CNN用在visual tracking中
目前用CNN做跟踪的方法主要有两种,一种是利用已经训练好的CNN模型提取目标特征,再采用传统的目标跟踪方法进行跟踪;一种是利用已知的跟踪目标样本来对CNN模型进行fine-tune,将最终训练的结果用于跟踪。
第一种方法本身具有局限性,CNN提取到的特征具有很强的语义信息,但是空间信息却很缺乏。第二种方法由于跟踪中样本数量太少,确定的样本往往只有第一帧的目标,因此fine-tune出的新模型很容易出现过拟合。
为缓解上述问题,作者提出了sequential training method,将CNN中每个卷积核对应的特征map输出看成是一个基学习器,将CNN的训练过程看成是一个集成学习的过程,然后用集成学习的方法得到最终的跟踪分类器。
3、集成学习(ensemble learning)
说到集成学习,可能有些人听起来会觉得陌生,但是提到adaboost,相信很多人都听过,而adaboost就是集成学习中的一个经典算法。中心思想是将最终的高级分类器看成是一些低级(基)分类器的加权组合。即:
其中 F(x) 代表最终的集成分类器, f(x⃗ ;γ) 代表每个基分类器。 αm 和 γm 则代表基分类器与集成分类器相关性系数和基分类器本身的参数。
类似于一般的分类算法中的损失函数,集成学习中用 Q(γ) 来表示基分类器的损失,同时也可以理解成基分类器与当前问题的无关性。
集成学习的一大好处就是能够增加分类器的表达能力(泛化能力),但是我们该如何选择基分类器呢?如果基分类器之间非常相似,那最终的集成分类器则不具有较好的多样性,因此在集成学习中用 σ 来表示基分类器之间的相关性:
各个基分类器与最优基分类器的相关性。当
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 729
729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









