







 这篇文章探讨了多模态大模型如何在汽车垂直领域中通过整合文本、图片和视频信息,提升用户体验和信息检索效率。汽车之家的多模态大模型能解决各种问题,从基础参数查询到视觉内容比较,显著增强用户获取专业内容的能力。
这篇文章探讨了多模态大模型如何在汽车垂直领域中通过整合文本、图片和视频信息,提升用户体验和信息检索效率。汽车之家的多模态大模型能解决各种问题,从基础参数查询到视觉内容比较,显著增强用户获取专业内容的能力。
传统的AI模型通常只处理一种类型的数据,如文本或图像。然而,现实世界中的数据通常是多模态的,包括文本、图像、音频、视频等。多模态大模型是一种人工智能模型,它可以根据多种类型的输入(例如文本、图像或视频)进行学习并产生输出。这意味着它可以理解和生成不同种类的数据,而不仅仅是单一模式的信息。
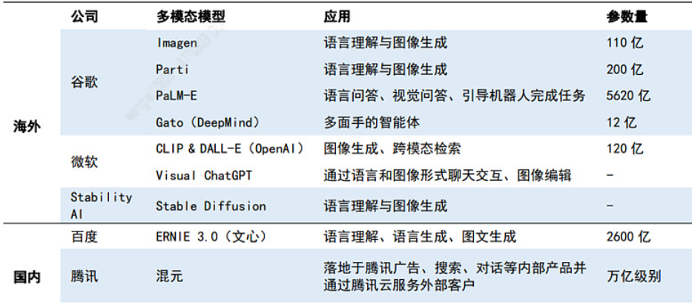
多模态大模型一览
在汽车垂类场景,单一的文本展示/问答无法满足用户,视觉内容的呈现可以更直接、高效的触达用户的需求。基于此,我们研发了多模态大模型,结合了文本、图片、视频等信息,让用户可以轻松可以获取有效信息。
多模态大模型可以基于文本问答模式的基础上,召回汽车之家更多专业、真实的图文和视频素材。纯文本问题可以解决用户在检索汽车价格、油耗、尺寸、参数等问题;当加入图片信息后可以解决用户在检索汽车外观、内饰、仪表盘、座椅等问题;当加入视频信息后可以检索汽车灯光效果、中控操作演示、舒适性等问题。
比如当我们使用大模型检索新款奔驰GLC和宝马X3大灯有什么区别?
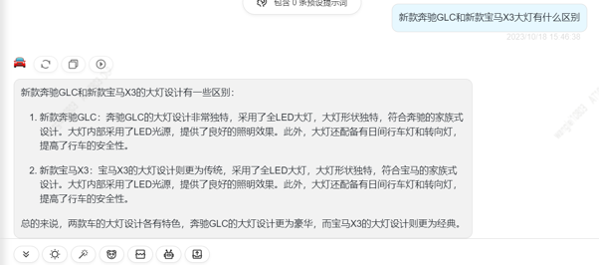
语言大模型回答结果

多模态大模型回答结果
可以看出多模态大模型在文本展示的基础上,会增加视频的素材,可以使用户获取信息更直观
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 9845
9845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









