




stm32
1、stm32(cortex M3)属于冯诺依曼结构
冯诺依曼结构:①程序存储器和数据存储器是同一个存储器 ②指令和数据宽度相同
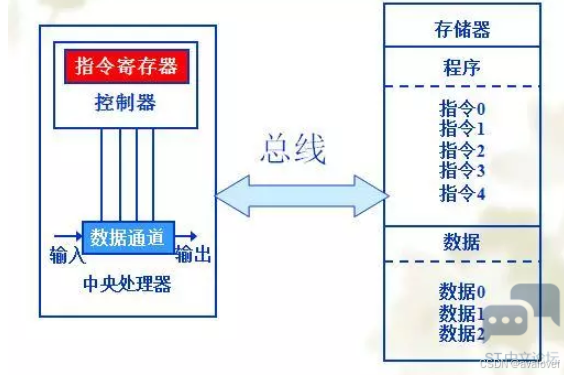
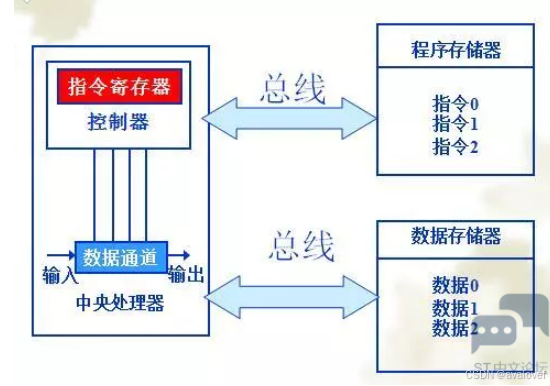
哈佛结构:①程序存储器和数据存储器不是同一个存储器 ②指令和数据宽度不相同 ③执行效率高
2、CPU性能提升:Cache机制

为了解决cpu和ram之间两者速度不匹配的问题,通过cache缓存一部分指令,cpu读的时候先去缓存读,如果缓存里面有就称为缓存命中,没有的话就重新开辟空间缓存。为了节约成本,可加上速度较低的二级cache来提升存储空间。
3、ARM常用的汇编
计算机的指令可分为4种:CISC(复杂指令集)、RISC(精简指令集)、EPIC(显示并行指令集)、超长指令字指令集(VLIW)。其中arm嵌入式都用的RISC。
cpu不能直接处理内存中的数据,需要将内存中的数据Load到寄存器才能操作,然后将处理结果store到内存中去。
常见的汇编语言包括:
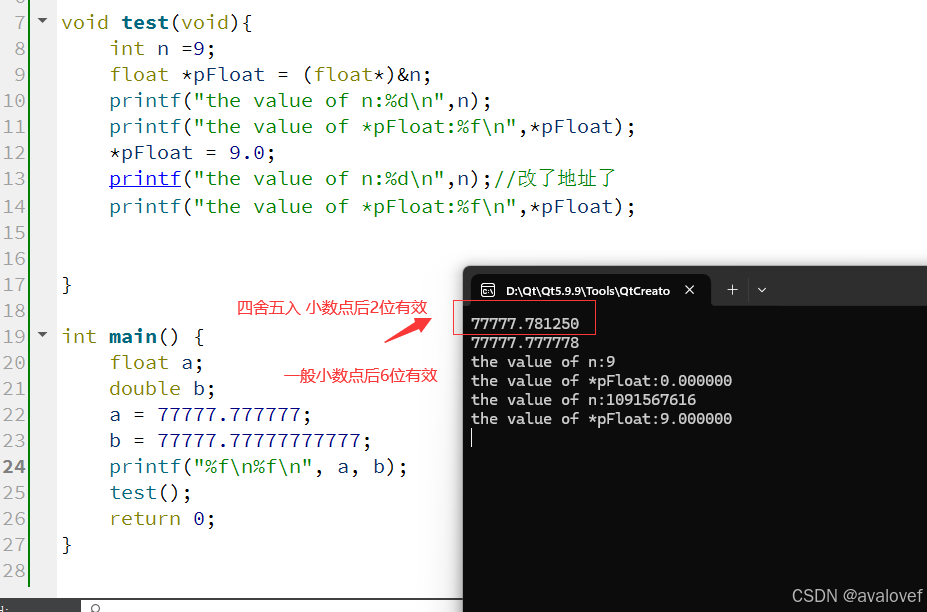
4、浮点数在内存当中如何存储的?浮点数如何判断相等?
** 所占内存空间:**
float:4个字节(byte),32个比特位(bit) 数值范围:3.4E-38~3.4E+38
double:8个字节(byte),64个比特位(bit)数值范围:1.7E-308~1.7E+308
有效位数不同,float:有效位数6~7字节,double:有效字节15 ~ 16位。
观察因为有效位数不同,所以表现的数字也不同。
5、位操作
1、对寄存器进行位操作,给定一个整形变量a,写两段代码,第一个设置a的bit 3,第二个清除a 的bit 3。在以上两个操作中,要保持其它位不变。
#define BIT3 (0X1<<3) //说明常数
static int a;
void set_bit3(void){
a |= BIT3 ;
}
void clear_bit3(void){
a &= ~BIT3 ; //清零
}
2、连着多个位一起清零
已知某外设的基地址为0x800_ 0000, 内部控制寄存器偏移地址0x8000, 请用一 条指令设置控制寄存器的BIT[6:7]位域清零, 其它位保持不变。
基地值加上偏移地址 0x8008000,连着的都设置为0 ,0x3
清零用与 * (volatile uint32_t * )0x8008000 &= ~(0x3<<6);
特别的这里要注意我们是对0x8008000这个地址操作,所以一定要用指针,把地址强转成一个指向volatile uint32_t 类型的指针,然后通过解引用操作符*来访问这个地址处的值。
6、访问固定的内存位置
嵌入式系统要求设置绝对地址为0X67A9的整形变量的值位0xaa66。编译器是一个纯粹的ANSI编译器。
是否知道为了访问一绝对地址把一个整型数强制转换(typecast)为一指针是合法的。
int *ptr;
ptr = int*(0x67a9);
*ptr = 0xaa66;
7、中断
1、ISR中断服务函数
下面的代码就使用了__interrupt关键字去定义了一个中断服务子程序(ISR),找出他的问题:
__interrupt double compute_area (double radius)
{
double area = PI * radius * radius;
printf("\nArea = %f", area);
return area;
}
(1)ISR没有返回值
(2)ISR没有传入参数
(3)最好不要在ISR里面做浮点运算,有的处理器和编译器是不支持浮点的
(4)printf经常有重定向和性能上的问题。最好不要在中断里面使用。
2、中断服务函数
中断分为内核异常(harddefault,系统调用,页故障,保护性异常,程序异常),外部中断(按键按下触发中断,时钟中断)。
总的执行流程:CPU收到IRQ(interrupt request)后,通过上下文切换保存到当前的工作状态,查询中断向量表,跳转到中断处理函数,完成后再出栈执行原有的程序。

9、unsigned int 和 int相加
整数自动转换原则:
void foo(void)
{
unsigned int a = 6;
int b = -20;
(a+b > 6) ? puts("> 6") : puts("<= 6");
}
由于a是无符号整数(unsigned int),当a和b相加时,如果结果为负数,会发生模运算(在这种情况下是模UINT_MAX + 1,因为unsigned int的最大值是UINT_MAX)。模运算的结果是将负数转换为其正数等效物。
对于32位的unsigned int,UINT_MAX通常是4294967295。因此,-14模4294967295 + 1的结果是4294967297(因为-14加上4294967295等于4294967281,然后加1得到4294967297)。
10、UART/SPI/I2C/USB之间的对比:
(I2C接口是“器件间”接口,是在一块板子之内传输数据),(UART更倾向于 “设备间”接口,更多的是用于两台设备之间传输数据):
| 协议 | UART(RS232) | SPI | I2C | USB |
|---|---|---|---|---|
| 总线 | (3)RX、TX、GND | (4)MOSI、MISO、SCK、CS | (4)VCC、GND、SCL、SDA | D+,D- |
| 同步/异步 | 异步(没有时钟线) | 同步 | 同步 | 同步 |
| 全/半双工 | 全双工 | 全双工 | 半双工(数据线只有一根) | 全双工 |
| 传输速度 | 低(通常115.2 kbps至115.2 Mbps ) | 高(一般50MHz以下) | 中(100kHz、400kHz、3.4MHz) | 超高(高速480 Mbps,全速12 Mbps等) |
| 拓扑结构 | 点对点(1v1) | 一主多从 | 1对多/多主从 | 点对点或集线器结构 |
| 串行、并行 | 串行(先发低位再发高位LSB) | 串行(LSB/MSB) | 串行(MSB) | 串行(取决于设备和协议) |
| 一主多从实现方式 | X | 各CS | SDA上设备地址片选 | 无,通过端口地址 |
Nandflash
并行:8位,一个字节发完。
10.1 UART
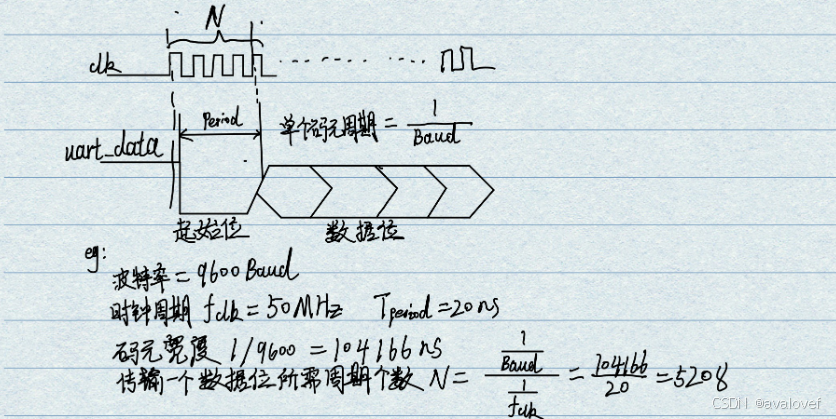
空闲时间总线高电平,起始位1bit拉低,数据位8bit,停止位1bit拉高
1、数据协议
低位在前:拉低以后,起始位+8位数据(LSB)+奇偶校验位+停止位+空闲位
uart串口信号线上空闲时常驻高电平,当检测到低电平下降沿时认为数据传输开始,到停止位时数据传输结束。假设发送1000 1101,按照低位在前,应该是发送的1011 0001过去。
波特率,波特率表示一秒内传输了多少个码元数量,一般波特率为300,1200,2400,9600,19200,38400,115200等。例如9600 Baud表示一秒内传输了9600个码元信息,当一个码元只含1 bit信息时,波特率=比特率.
比如12位的数据,波特率9600,每秒种串口可以传输__多少个字节数据
9600/12 =800个字节。
2.串口TTL,RS232,RS485
TTL: 供电范围在0~5V;>2.7V是高电平;<0.5V是低电平。
RS232:负电平表示逻辑"1",正电平表示逻辑"0",通过提高电压差的方式抗干扰
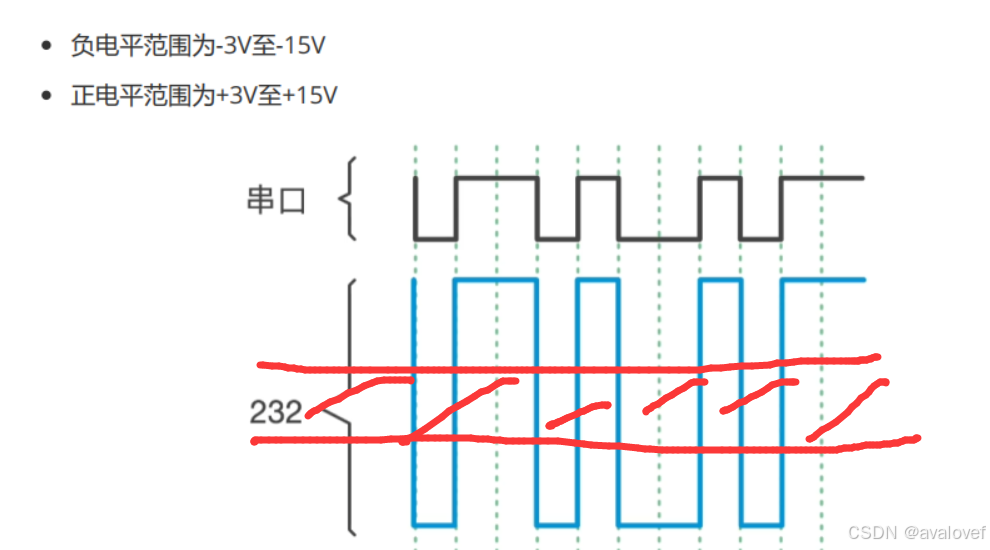
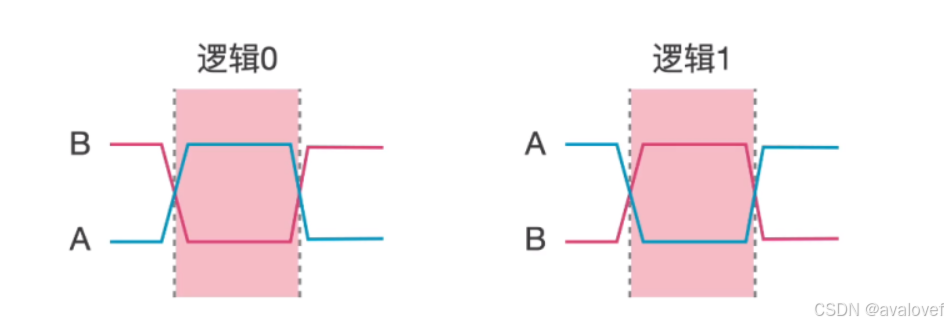
RS485:通过差分信号抗干扰,当A线高于B线时,表示逻辑"1";当B线高于A线时,表示逻辑"0"
10.2 I2C
I2C的SCL始终是master产生。
有效的数据位:SCL为高:
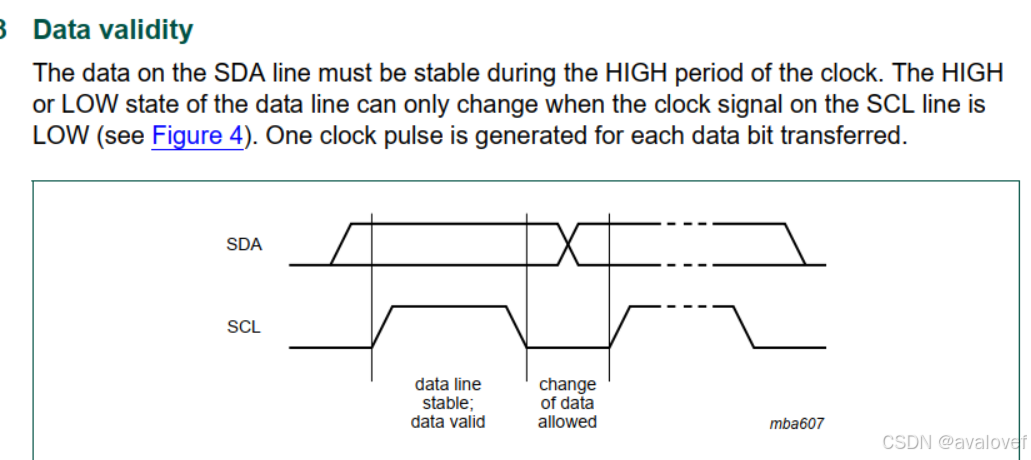
①总线上的数据格式
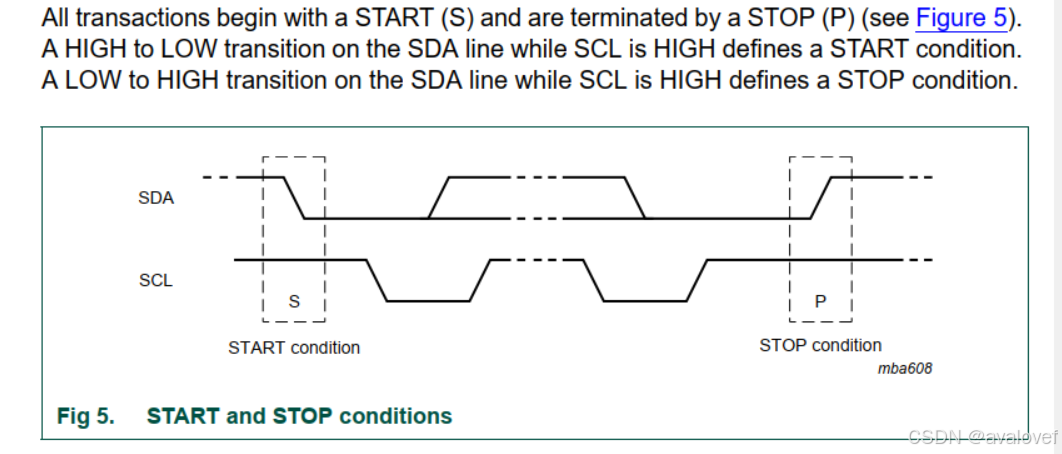
1)无数据(空闲) :SDA = 1,SCL =1;
2) 开始位(start): SCL =1时,SDA由1变为0
3)停止位(stop): SCL =1时,SDA由0变为1
4)数据位:当SCL由0向1跳变时,由发送方控制SDA,此时SDA为有效数据,不可随意改变SDA;当SCL保持为0时,SDA上的数据可随意改变;
5)地址位:定义同数据位,但只由Master发给Slave;
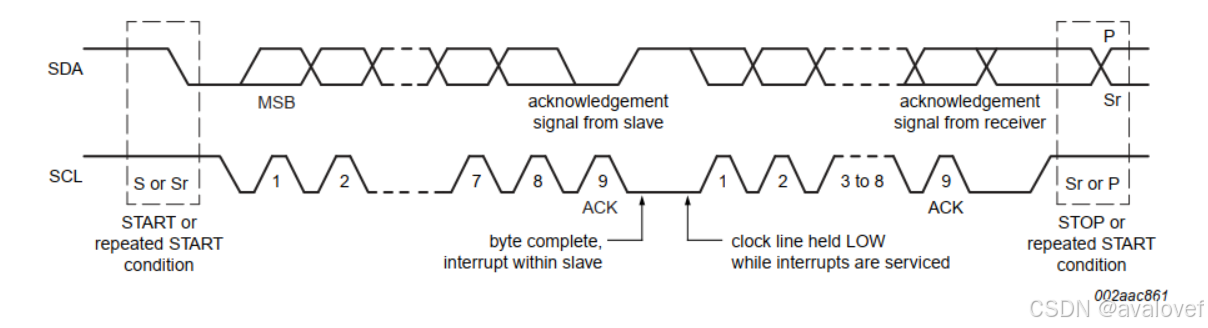
6)应答位(ACK):当发送方传送完8位时,发送方释放SDA,由接收方控制SDA,且SDA=0;
7)否应答位(NACK):当发送方传送完8位时,发送方释放SDA,由接收方控制SDA,且SDA=1。
8)当数据为单字节传送时,格式为:开始位 + 8位地址位(含1位读写位) + 应答 + 8位数据 + 应答 + 停止位。
当数据为一串字节传送时,格式为:开始位 + 8位地址位(含1位读写位) + 应答 + 8位数据 + 应答 + 8位数据 + 应答 + …… + 8位数据 + 应答 + 停止位。
(重复 8位数据+应答)
②写时序
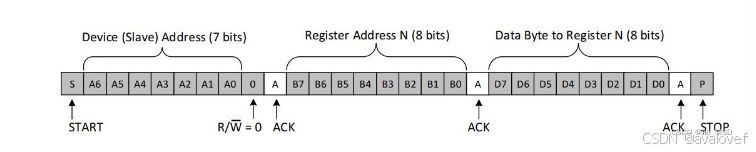
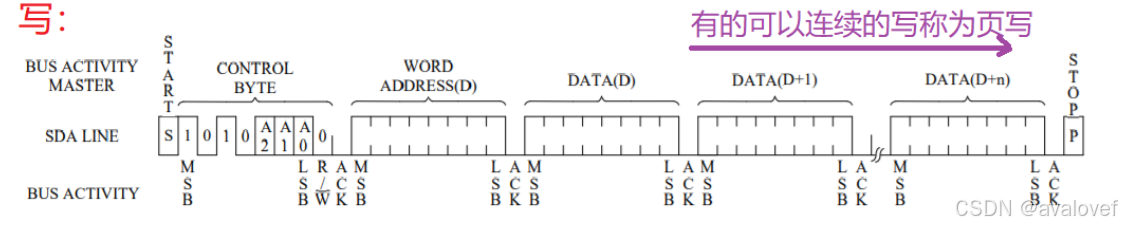
写时序:
a)主机开始信号
b)主机发送i2c7位设备地址和1位写标志0-检测1位从机ACK
c主机发送写入8位寄存器地址(有的是16位)-检测1位从机ACK
d)传输data,传8位以后从机ACK一次
e)主机stop信号
③读时序
先写入设备地址,每发8位,都要ack一下,
等把设备地址和寄存器地址写入以后,重新start,再写入设备地址,高位读1,最后连续读,然后发送ack,直到不想收了就发送nack。
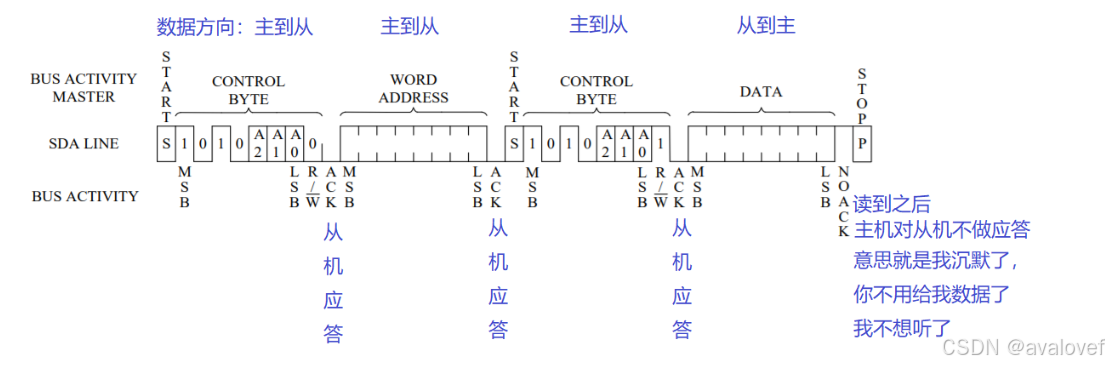
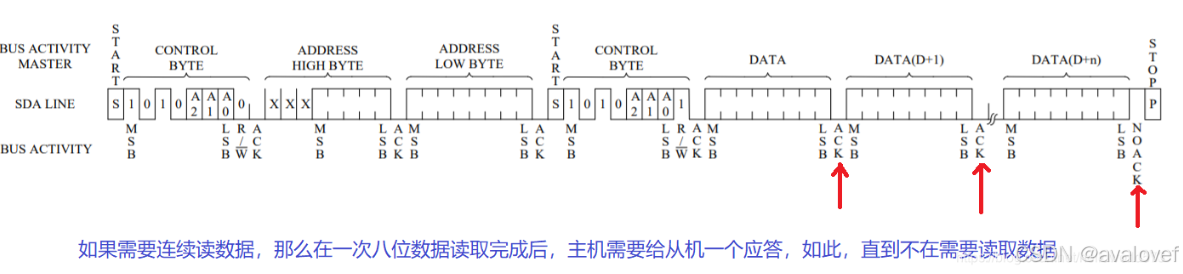
读时序:
a)主机开始信号
b)主机发送i2c7位设备地址和1位写标志0-检测1位从机ACK
c主机发送写入8位寄存器地址(有的是16位)-检测1位从机ACK
d)主机发送i2c7位设备地址和1位读标志1-检测1位从机ACK
e)从机发送8位数据,主机如果ACK表示继续发,主机如果NACK表示不用发了
e)主机stop信号
④典型的应用
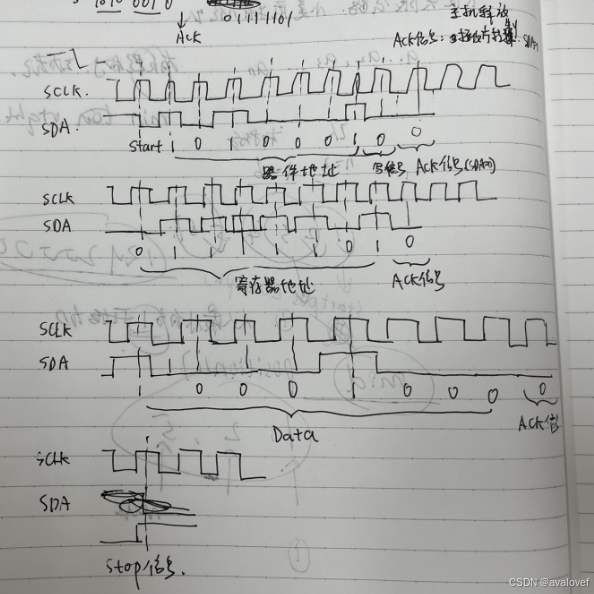
假设器件地址为A0,器件内储存地址为01111101,向其中写入10001000。那么该I2C写时序为:
分析:由于器件地址是A0,那么有 001,再组合写位和前面的1010就是 1010 0010。寄存器地址是01111101
最后写入的数据内容是10001000。
由于是MSB发送,所以高位在前,整个的发送数据相对位置保持不变:
总的发送顺序是
主机控制SDA:
START信号- 1010 0010-ACK-01111101-ACK-10001000-ACK-STOP信号
⑤一些驱动函数
但是首先要写i2c_Delay,i2c_Start,i2c_Stop,i2c_SendByte,i2c_ReadByte,i2c_Ack,i2c_NAck这些函数,然后再去封装读写函数。
开始信号start
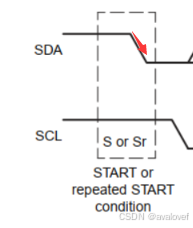
void i2c_Start(void){
I2C_SDA_1();
I2C_SCL_1();
i2c_Delay();
I2C_SDA_0();
i2c_Delay();
I2C_SCL_0();
i2c_Delay();
}
停止信号Stop
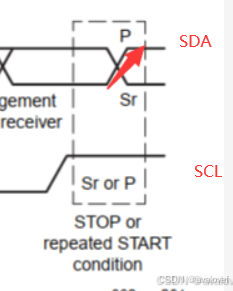
void i2c_Stop(void)
{
/* 当SCL高电平时,SDA出现一个上跳沿表示I2C总线停止信号 */
i2c_Delay();
I2C_SCL_1();
i2c_Delay();
I2C_SDA_1();
i2c_Delay();
}
应答信号ACK
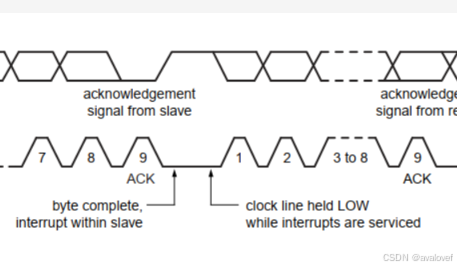
接收端接收到信号以后,发送低电平表示收到信号(SDA),这个时候SCL产生一个信号ACK(高电平-delay-低电平)表示收到。SDA再被释放。
void i2c_Ack(void)
{
I2C_SDA_0(); /* CPU驱动SDA = 0 */
i2c_Delay();
I2C_SCL_1(); /* CPU产生1个时钟 */
i2c_Delay();
I2C_SCL_0();
i2c_Delay();
I2C_SDA_1(); /* CPU释放SDA总线 */
i2c_Delay();
}
10.3 spi qspi
1、SPI数据线:SCK、MOSI、MISO、CS
2、SPI的工作模式

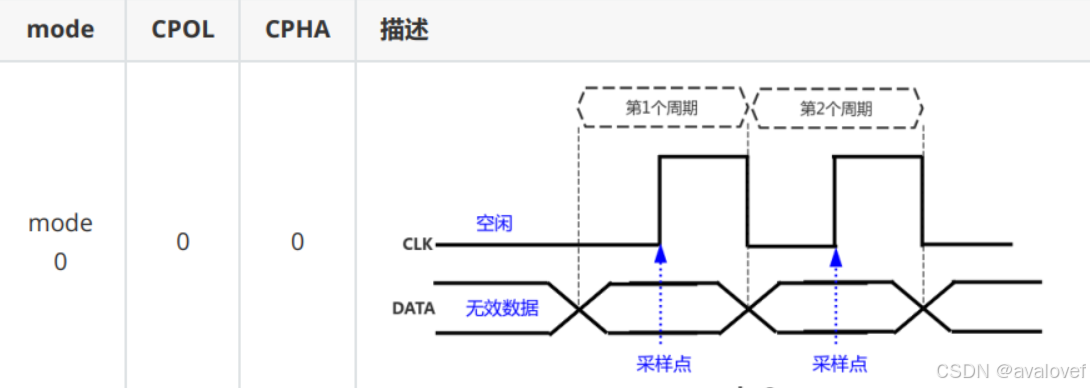
3、在SPI的基础上,将数据线MOSI和MISO扩展为两条数据线(IO0\IO1),每个时钟可以传2bit的数据,qspi进一步扩展为4线…
4、QSPI
三种功能模式:间接模式、状态轮询模式和内存映射模式
间接模式:使用 QUADSPI 寄存器执行全部操作
状态轮询模式:周期性读取外部 FLASH 状态寄存器,而且标志位置 1 时会产生中断(如擦除或烧写完成,会产生中断)
内存映射模式:外部 FLASH 映射到微控制器地址空间,从而系统将其视作内部存储器
11、STM32的启动流程
通过boot引脚设置启动方式:寻找初始地址
boot0 boot1 启动方式
0 x 从内存flash启动 0x08000000
1 1 从内部sram启动 0x20000 0000
1 0 从从系统存储器启动,这种模式启动的程序功能是由厂家设置的 0x1FFF0000
xxx的起始地址被重映射到了0x00000000地址,从而代码从xxx开始启动”
设置堆栈指针 SP = _initial_sp 0x0000 0000
设置PC指针 = Reset_Handler 0x0000 0004
设置异常中断 HardFault_Handler
设置系统时钟 SystemInit
调用C库函数 _main
12、ADC采样
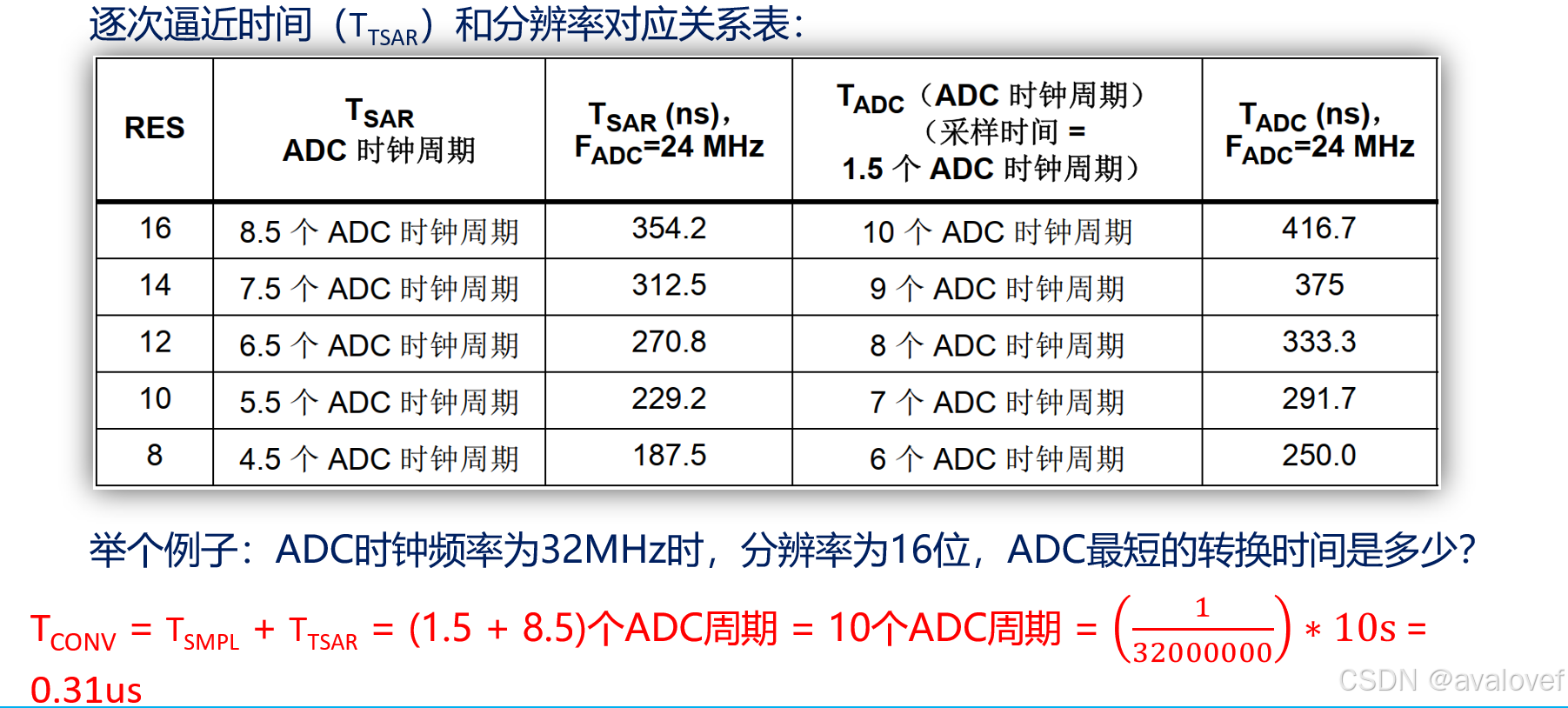
1、ADC总转换时间如下计算:
ADC转换时间:TCONV = 采样时间(TSMPL) + 逐次逼近时间(TTSAR)。
2、ADC采样通道中值滤波
请使用C语言实现如下功能:对两个通道ADC采样得到的N (N>0) 组数据,结合排序算法,进行中值滤波,并返回中位值。
#include <stdio.h>
#include <stdlib.h>
#define N (21) //假设转换21个
int ADC_ch1[N] = {0}; //存放adc转换结果
int ADC_ch2[N] = {0};
// 简单的冒泡排序函数
void bubbleSort(int arr[], int n) {
int i, j, temp;
for (i = 0; i < n-1; i++) {
for (j = 0; j < n-i-1; j++) {
if (arr[j] > arr[j+1]) {
temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
}
// 中值滤波函数
int medianFilter(int channel1[], int channel2[], int n) {
int merged[2*n];
int i;
// 合并两个通道的数据
for (i = 0; i < n; i++) {
merged[i] = channel1[i];
merged[i + n] = channel2[i];
}
// 对合并后的数组进行排序
bubbleSort(merged, 2*n);
// 找出中位值
if (2*n % 2 == 0) {
// 数组长度为偶数,取中间两个数的平均值
return (merged[n-1] + merged[n]) / 2;
} else {
// 数组长度为奇数,直接取中间数
return merged[n];
}
}
int main() {
int median;
median = medianFilter(ADC_ch1, ADC_ch2, N);
printf("Median Value: %d\n", median);
return 0;
}
13、PWM
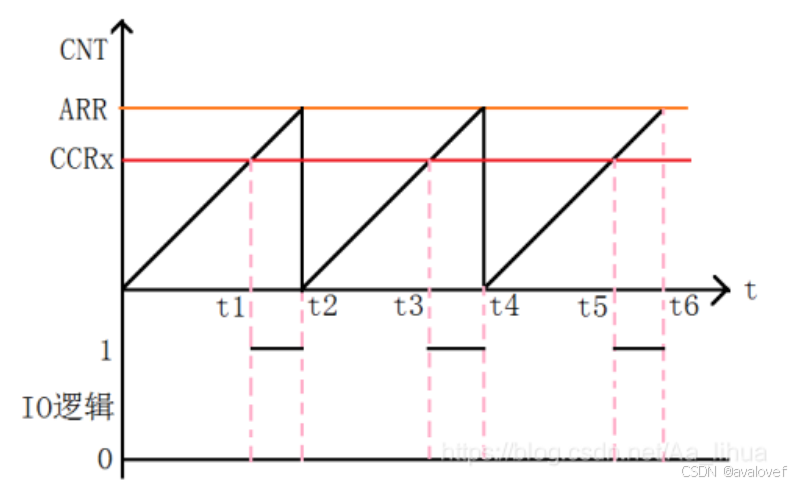
CNT是计数值 ARR是重装载值 CCRx是比较值:
PWM 模式1 计数值大于比较值 输出有效电平 否则输出无效电平
PWM 模式2 计数值大于比较值 输出无效电平 否则输出有效电平(有效电平我们自己设定,电平输出作用在定时器PWM的输出通道)
ARR=1000 CCRx=500 有效电平为:高电平
当CNT<CCRx 时(即CNT在(0,500)的范围时)输出无效电平(即低电平)
当CNT>CCRx 时(即CNT在(501,1000)的范围时) 输出有效电平(高电平)
高低电平时间各占一半,即PWM的占空比为50%,重装载值为PWM的周期(即定时器的更新时间为PWM的周期)
14、Nor Flash Nand Flash
1.NoR Flash和Nand Flash的区别
NoR Flash:
(1)中不仅可以存储数据,且可以取指运行(XIP),也就是MCU给出地址,Nor可以直接返回指令交给MCU去执行,这样不用把指令拷贝到RAM里去执行;(内部flash,rom )
(2)读取速度快,但是写入和擦除的速度相对Nand flash较慢。
(3)写入方式:选擦除,将指定的扇区设置为1,然后在特定位写0,存储数据。(是没办法直接写1的)
Nand flash:
(1)仅可用于存储,取值时需要搬运到RAM中(外部的存储器件 eeprom)。
(2)NAND Flash的写入和擦除速度比NOR Flash快,但随机读取速度较慢。
(3)写入方式:选擦除指定的页,扇区的状态都设置为1,然后在特定位写0,存储数据。(是没办法直接写1的)
xip运行代码的逻辑:在系统启动时,不将代码复制到RAM,而是直接在非易失性存储位置执行,RAM中只存放需要不断变化的数据部分:
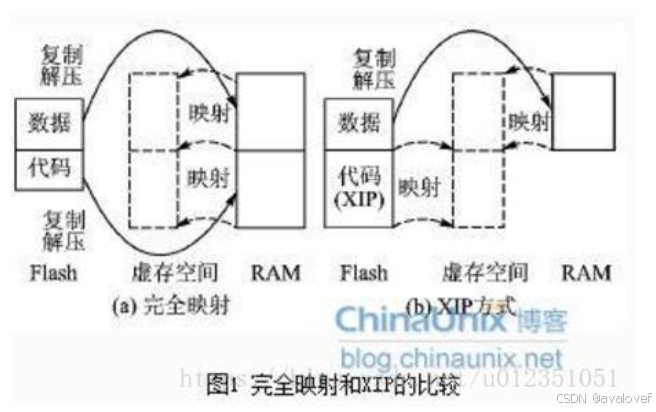
2、存储单元
页(Page)< 扇区(Sector) < 块(Block)< 芯片(Chip)
文件系统中的扇区、块。文件系统的种类很多,比如FAT、FAT32、exFAT、NFS,不同的文件系统,底层对存储地址的划分可能不同。在MCU这类嵌入式系统中,页、扇区是最小的物理存储单元,但在Windows、Linux这类系统中,这么小的存储单元已经不能满足要求了(不能对众多扇区寻址),于是就会以块作为最小的寻址单元。如果最小的存储单元太小,会造成寻址空间不够,如果太大,也会造成存储空间的浪费。
15.ARM架构
arm只负责内核的设计
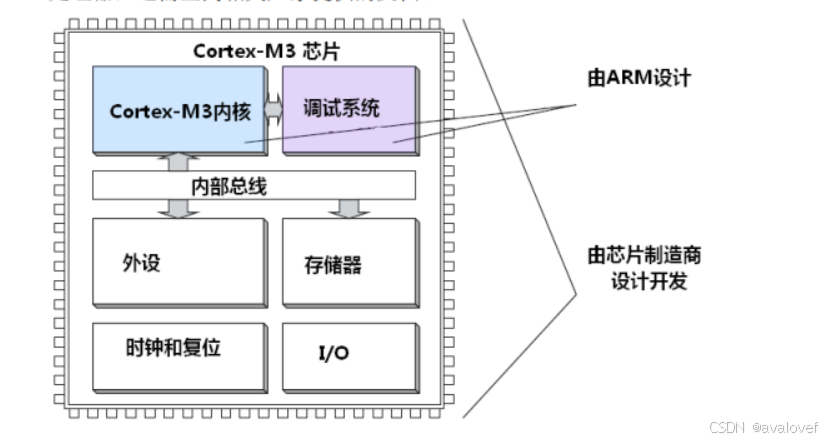
thumb-2指令集(32bit和16bit指令可以并存,不需要状态切换)
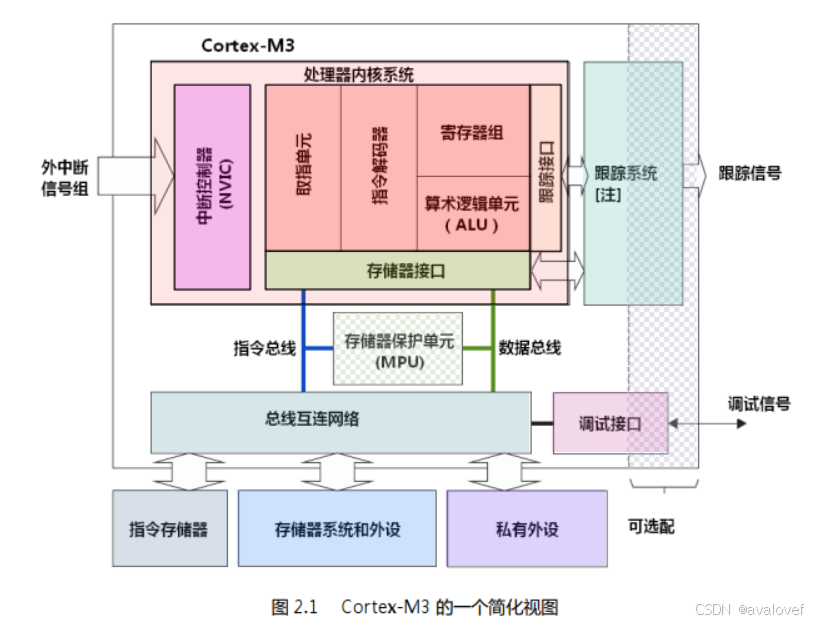
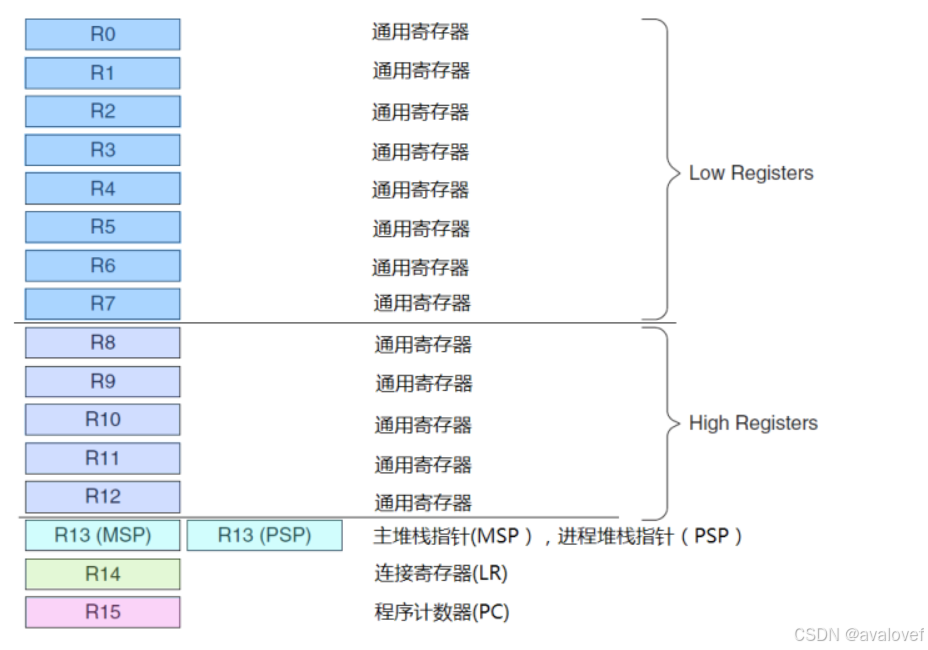
15.1 寄存器组
Cortex-M3 处理器拥有 R0-R15 的寄存器组。其中 R13 作为堆栈指针 SP。 SP 有两个,但在同一时刻只能有一个可以看到,这也就是所谓的“banked”寄存器。
1、基础功能寄存器
R0-R7:低位寄存器
R8-R12:高位寄存器(thumb-2可以访问所有的寄存器)
R13(MSP\PSP):主堆栈指针(用于操作系统内核以及异常处理历程)、进程堆栈指针(用于用户的应用程序代码使用)
R14: 连接寄存器(LR)(当调用一个子程序的时候,由R14存储返回的的地址,多余一级则需要压栈)
R15:程序计数器 (PC) (指向当前的程序的地址,如果改变他的值,就能改变程序的执行流)
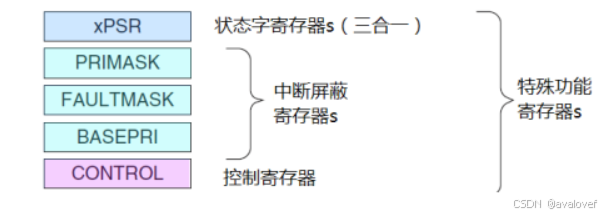
2.特殊功能寄存器
Cortex-M3 还在内核水平上搭载了若干特殊功能寄存器,包括程序状态字寄存器组(PSRs)、中断屏蔽寄存器组(PRIMASK, FAULTMASK, BASEPRI)、控制寄存器(CONTROL)。
15.2 操作模式和特权级别
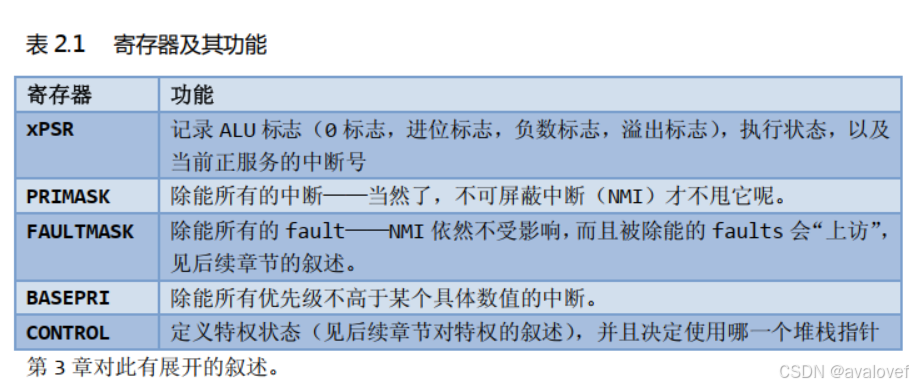
总共3种组合:
1、操作模式包括:是用于区别普通应用程序的代码和异常服务例程的代码——包括中断服务例程的代码
handler mode \ thread mode
2、特权级别:提供存储器访问的保护机制。
特权级、用户级。
相当于(内核态和用户态的区别),线程模式下,可以是特权级或者用户级,但是在handdler模式下必须是特权级。
在特权级下,程序可以访问所有范围的存储器(如果有 MPU,还要在 MPU 规定的禁地之外),并且可以执行所有指令。
线程模式(Thread Mode):这是处理器的一般运行模式,用于执行普通的应用程序代码。在复位后,处理器默认处于线程模式且为特权级(Privileged Level)。在线程模式下,可以通过修改CONTROL寄存器中的特权级别位(PR维位)来切换到用户级别。
处理者模式(Handler Mode):当处理器响应异常或中断时,它切换到处理者模式。在处理者模式下,处理器总是运行在特权级,以便能够访问所有必要的系统资源来处理异常或中断。处理完异常或中断后,处理器会返回到之前的模式和特权级别。
特权级(Privileged Level):在这个级别下,处理器可以访问所有的内存和系统资源,执行所有的指令。特权级主要用于操作系统内核、设备驱动程序和中断处理等需要访问控制寄存器和内存管理单元的操作。
用户级(User Level):用户级别的权限受到限制,某些寄存器和内存区域不允许访问,以防止应用程序干扰系统的稳定运行。如果用户级代码尝试访问受限资源,处理器会触发一个故障(Fault)。

特权级线程模式可以修改CONTROL寄存器回到用户级线程模式,但是用户级线程模式想要回到特权级线程模式就必须先出发SVC异常进入特权级handker模式再回特权几线程模式(异常服务例程需要改CONTROL寄存器)
特权级线程模式:系统启动或主任务运行时。运行一个嵌入式应用程序,例如控制LED闪烁的主循环代码。
用户级线程模式:应用程序主动切换到用户级以限制对系统资源的访问。运行一个用户应用程序,例如一个图形用户界面(GUI)应用,限制其对系统资源的访问,以增强安全性和稳定性。
特权级处理者模式:发生中断或异常时,处理器自动切换到该模式以处理相关事件。处理一个外部中断,例如一个按钮被按下,触发中断服务例程(ISR)来响应用户输入。在ISR中,处理器需要访问硬件寄存器和执行特权操作。
15.3 中断分组
Cortex-M3 在内核水平上搭载了一颗中断控制器——嵌套向量中断控制器 NVIC,可嵌套中断支持,向量中断支持…
15.4 存储器映射
(预先规定了存储器映射)
15.5总线接口
Cortex-M3 内部有若干个总线接口,以使 CM3 能同时取址和访内(访问内存),它们是指令存储区总线(两条),系统总线,私有外设总线。
有两条代码存储区总线负责对代码存储区的访问,分别是 I-Code 总线和 D-Code 总线。前者用于取指,后者用于查表等操作,它们按最佳执行速度进行优化。
系统总线用于访问内存和外设,覆盖的区域包括 SRAM,片上外设,片外 RAM,片外扩展设备,以及系统级存储区的部分空间。
私有外设总线负责一部分私有外设的访问,主要就是访问调试组件。它们也在系统级存储区。
15.6 MPU
Cortex-M3 有一个可选的存储器保护单元。配上它之后,就可以对特权级访问和用户级访问分别施加不同的访问限制。当检测到犯规(violated)时, MPU 就会产生一个 fault 异常,可以由fault 异常的服务例程来分析该错误,并且在可能时改正它。它可以把某些内存 region 设置成只读,从而避免了那里的内容意外被更改;还可以在多任务系统中把不同任务之间的数据区隔离。
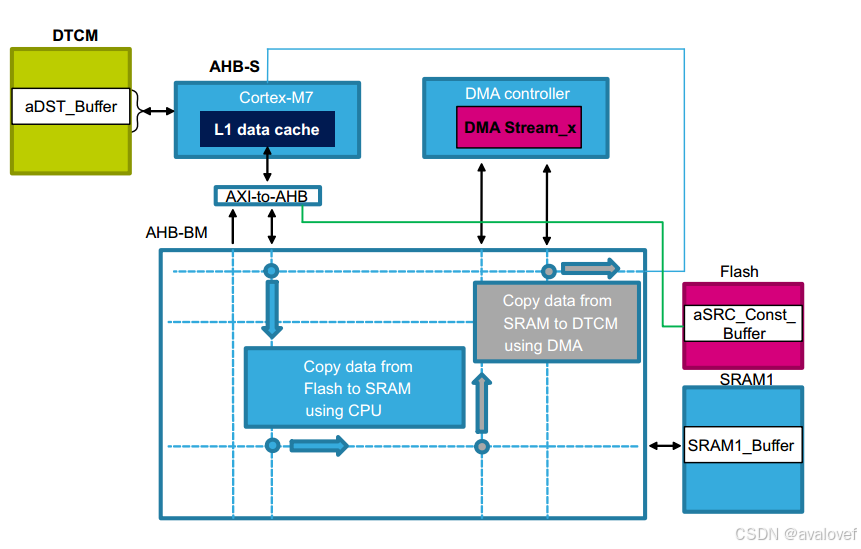
cache导致数据不一致的问题:
第一种情况,core去写物理内存,core会先更新相应的chahe-line(write-back),在没有clean的情况在,回导致其物理内存中的数据没有被更新,如果这个时候有其他的host访问这段地址的话(比如DMA),就会出现问题(实际的物理内存中没有更新)。
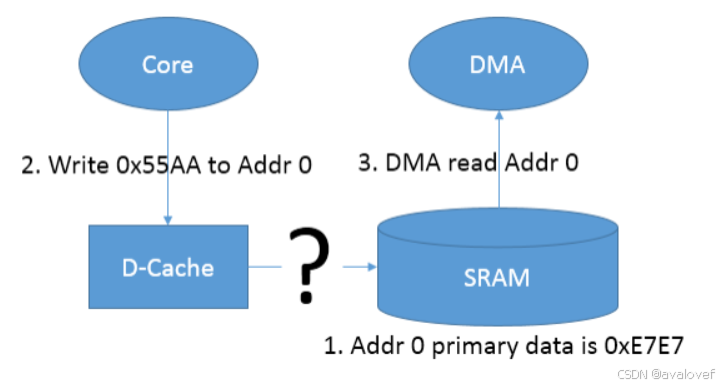
在启动 DMA 访问之前,程序员需要在合适的地方将 D-Cache 数据回写到主内存中,也就是 Clean 的操作。
在本示例中,可以在 DMA_Config(); 前调用:SCB_CleanDCache();
第二种情况是 DMA 更新了某段物理内存(DMA 和 cache 直接没有直接通道),而这个时候 Core 再读取这段内存的时候,由于相对应地址的 cache-line 没有被 invalidate,导致 Core 读到的是 cache-line 中的数据,而非被 DMA 更新过的实际物理内存的数据。
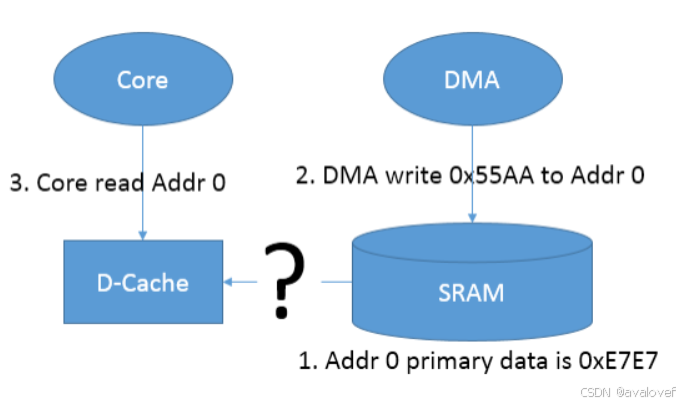
对于第二种情况(图3.2),就不是 clean 操作了,而是 invalidate。需要先调用 SCB_InvalidateDCache() 或 SCB_InvalidateDCache_by_Addr() 去 invalidate 相应的 cache-line, 这样当 CPU 在读取时,会忽略 D-cache 中的内容,去真实的物理地址读取对应的数据。
解决办法,通过软件进行cache维护:
使用透写属性(通过 MPU 设置)。
使用 SIWT@CACR(Shared = Write Through)。
通过指令清 D-cache,然后所有更新位置禁止 D-Cache操作。
FreeRTos
1 、移植rtos内核
思路:新建FreeRTOS工程->device选择Cortex-M7->内核->移植
1.FreeRTOS内核移植的过程
以移植FreeRTOS到stm32F4上为例,
step1:移植源码
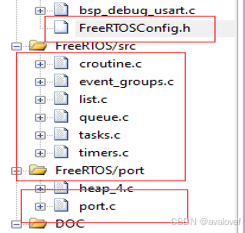
a. 添加FreeRtos的源码到工程,建立文件夹FreeRTOS/port,存放heep_4.c(创建内核对象使用的动态分配函数)和port.c(为ARM CM4F内核处理器写的接口文件)和对应的头文件。
b. 建立文件夹FreeRTOS/src,添加常用的库如list.c,queue.c,tasks.c,timers.c等等。
c. 添加FreeRTOSConfig.h(是工程配置文件,FreeRTOS是可以剪裁的实时操作系统,用户可以修改配置头文件来剪裁FreeRTOS的功能),include f4的头文件,并且根据需要关闭打开宏定义,节省资源。
FreeRTOSConfig.h里面的部分宏定义
//断言
#define vAssertCalled(char,int) printf("Error:%s,%d\r\n",char,int)
#define configASSERT(x) if((x)==0) vAssertCalled(__FILE__,__LINE__)
//置1:RTOS使用抢占式调度器(高优先级先运行);置0:RTOS使用协作式调度器(时间片)
//优先级不同:调度器运行最高优先级的就绪任务(抢占式调度器) 优先级相同:多个任务进行可以进行切换(时间片协作)
#define configUSE_PREEMPTION 1
//1使能时间片调度(默认式使能的)
#define configUSE_TIME_SLICING 1
//是软件方法扫描就绪链表
#define configUSE_PORT_OPTIMISED_TASK_SELECTION 1
/*
* 写入实际的CPU内核时钟频率,也就是CPU指令执行频率,通常称为Fclk
* Fclk为供给CPU内核的时钟信号,我们所说的cpu主频为 XX MHz,
* 就是指的这个时钟信号,相应的,1/Fclk即为cpu时钟周期;
*/
#define configCPU_CLOCK_HZ (SystemCoreClock)
//RTOS系统节拍中断的频率。即一秒中断的次数,每次中断RTOS都会进行任务调度
#define configTICK_RATE_HZ (( TickType_t )1000)
//可使用的最大优先级
#define configMAX_PRIORITIES (32)
//空闲任务使用的堆栈大小
#define configMINIMAL_STACK_SIZE ((unsigned short)128)
//任务名字字符串长度
#define configMAX_TASK_NAME_LEN (16)
/**********/
//支持动态内存申请
#define configSUPPORT_DYNAMIC_ALLOCATION 1
//支持静态内存
#define configSUPPORT_STATIC_ALLOCATION 0
//系统所有总的堆大小
#define configTOTAL_HEAP_SIZE ((size_t)(36*1024))
/**********/
/****************************************************************
FreeRTOS与中断服务函数有关的配置选项
****************************************************************/
#define xPortPendSVHandler PendSV_Handler
#define vPortSVCHandler SVC_Handler
step2:修改"stm32f4xx_it.h"
将xPortSysTickHandler移植到SysTick_Handler()中,保证FreeRtos的节拍正常
extern void xPortSysTickHandler(void);
//systick中断服务函数
void SysTick_Handler(void)
{
#if (INCLUDE_xTaskGetSchedulerState == 1 )
if (xTaskGetSchedulerState() != taskSCHEDULER_NOT_STARTED)
{
#endif /* INCLUDE_xTaskGetSchedulerState */
xPortSysTickHandler();
#if (INCLUDE_xTaskGetSchedulerState == 1 )
}
#endif /* INCLUDE_xTaskGetSchedulerState */
}
step3:硬件初始化
step4:创建SRAM动态任务
a.动态任务的内存分配:
在FreeRTOSConfig.h里面有对应的configTOTAL_HEAP_SIZE堆栈大小,我们自己是可以设置的。在heap4中用大数组(堆内存),供FreeRtos的内存分配函数使用。((size_t)(36*1024)) 36KB
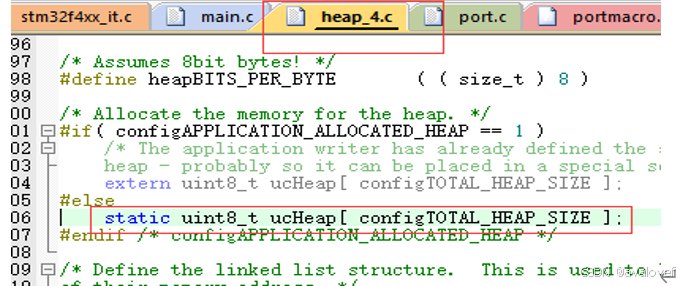
如果第一次调用会调用定义的堆内存进行初始化。
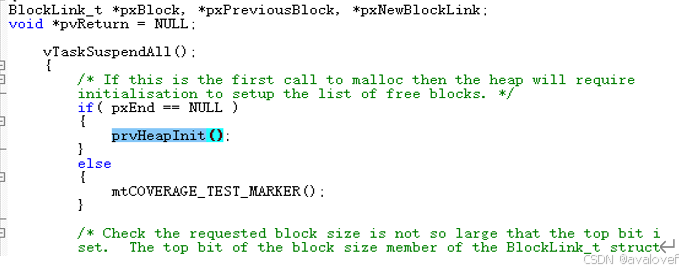
b.自定义任务函数 定义任务栈 创建任务句柄 xTaskCreate创建任务
c.启动任务调度器(vTaskStartScheduler()),只会启动一次,并且启动以后不会返回,任务管理都由FreeRTos管理。
static TaskHandle_t AppTaskCreate_Handle = NULL;/* 创建任务句柄(动态分配内存) */
BaseType_t xReturn = pdPASS;/* 定义一个创建信息返回值,默认为pdPASS */
xReturn = xTaskCreate((TaskFunction_t )AppTaskCreate, /* 任务入口函数 */
(const char* )"AppTaskCreate",/* 任务名字 */
(uint16_t )512, /* 任务栈大小 */
(void* )NULL,/* 任务入口函数参数 */
(UBaseType_t )1, /* 任务的优先级 */
(TaskHandle_t* )&AppTaskCreate_Handle);/* 任务控制块指针 */
/* 启动任务调度 */
if(pdPASS == xReturn)
vTaskStartScheduler(); /* 启动任务,开启调度 */
else
return -1;
while(1); /* 正常不会执行到这里 */
其中 vTaskStartScheduler会帮我们创建空闲任务,定时器任务(configUSE_TIMERS 1 )和启动系统节拍定时器。
创建空闲任务是为了保证系统随时有任务处于运行态,并且不可以被挂起和删除,空闲任务的优先级最低,以便方便其他任务能随时抢占空闲任务的CPU使用权。
2、FreeRTOS启动流程
方法一:硬件初始化–>RTos系统初始化–>创建多个任务–>开启调度器(常用)
方法二:硬件初始化–>RTos系统初始化–>创建一个总任务–>开启调度器–>当所有任务都创建成功后,启动任务把自己删除
系统上电的–>启动文件 复位函数Reset_Handler—>__main(初始化系统的堆和栈 )—>main()
3、FreeRTOS的三个异常
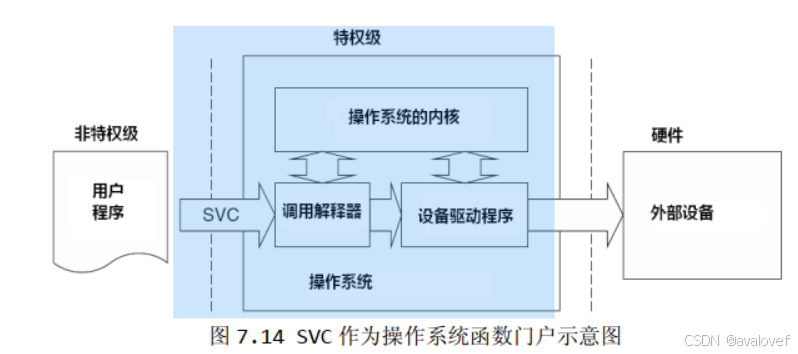
vTaskStartScheduler还调用了xPortStartScheduler,介绍一下异常:SVC\PENDSV\SYSTICK
SVC (系统调用):用于任务启动 ,用户程序使用 SVC 发出对系统服务函数的呼叫请求,以这种方法调用它们来间接访问硬件, 它就会产生一个SVC 异常,再到SVC异常服务例程中执行。
PendSV():于完成任务切换, 它是可以像普通的中断一样被挂起的,它的最大特性是如果当前有优先级比它高的中断在运行, PendSV 会延迟执行,直到高优先级中断执行完毕,这样子产生的 PendSV 中断就不会打断其他中断的运行。
SysTick(): 用于产生系统节拍时钟,提供一个时间片,如果多个任务共享同一个优先级,则每次 SysTick 中断,下一个任务将获得一个时间片。
把PendSV 和 SysTick 异常优先级设置为最低,这样任务切换不会打断某个中断服务程序,中断服务程序也不会被延迟 。SysTick 是硬件定时器,它一直在计时,这一次的溢出产生中断与下一次的溢出产生中断的时间间隔是一样的 ,不会因为被打断影响计时。
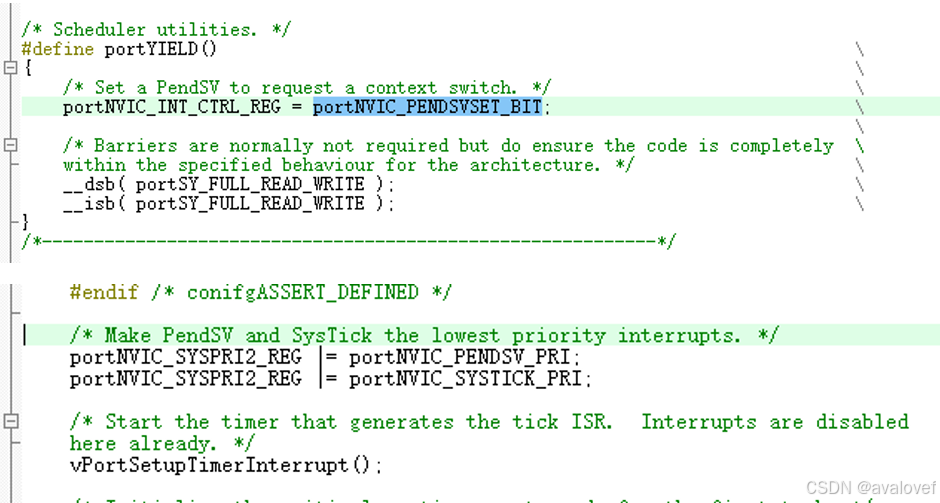
PendSV解决的问题:
上下文切换被触发的场景,可能包括:执行一个系统调用(SVC)、系统滴答定时器SYSTICK中断(时间片轮转调度).
假设没有PendSV,那么假设系统有两个就绪任务,通过Systick异常(SYSTICK中断)来启动上下文的切换。(上下文切换指的是在多任务操作系统中,一个线程切换到另一个线程的过程,这个过程涉及到保存当前进程的状态,并且加载到新进程的过程,以便他可以从上次停止的地方继续执行)
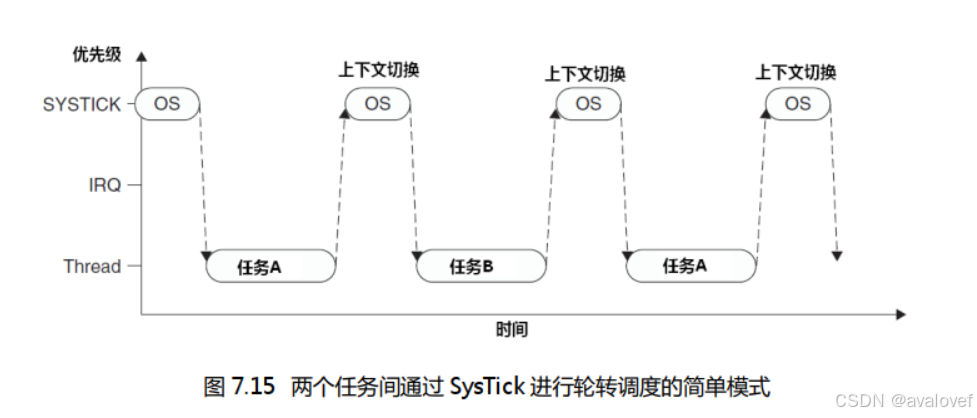
但是如果在SYSTIC中断的时候还有其他中断ISR,那么该ISR很可能被打断,不能及时执行:
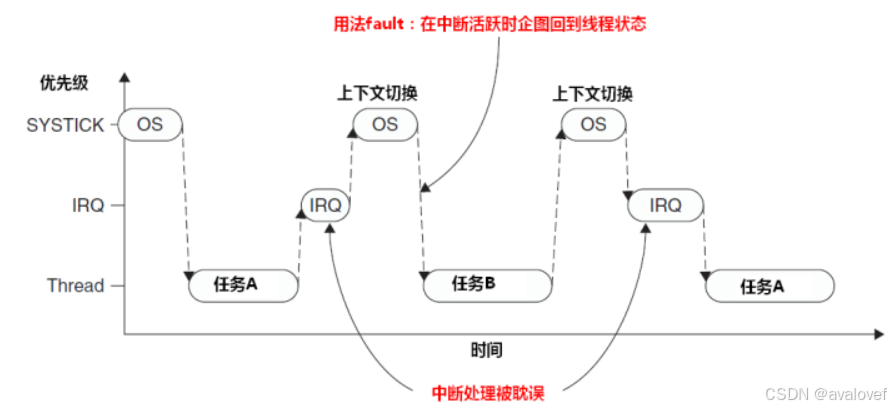
所以添加PendSV解决这个问题,PendSV异常会自动延迟上下文切换的请求。直到其他的ISR都完成了以后才放行,所以一般把PendSV编程为最低优先级。如果OS检测到某个IRQ正在活动,并且被SysTick抢占,他将悬起一个PendSV异常,以便缓期执行上下文切换。
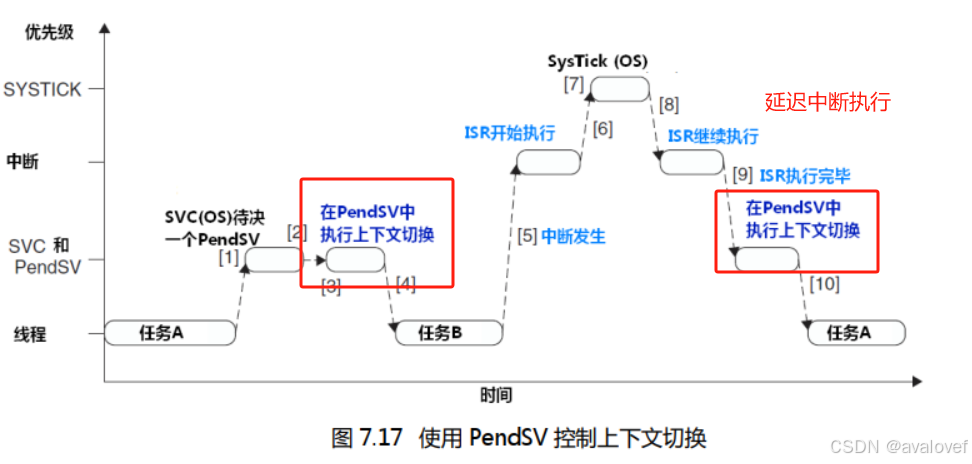
PendSV还有什么
4、临界段
临界段用一句话概括就是一段在执行的时候不能被中断的代码段 我们在临界段创建任务,任务只有在退出临界区的时候才会执行最高优先级任务。否则可能会抢占现在正在执行的任务。
在 FreeRTOS 里面,这个临界段最常出现的就是对全局变量的操作 ,临界段被打断的情况: 系统调度,还有一个就是外部中断。 在FreeRTOS,系统调度,最终也是产生 PendSV 中断,在 PendSV Handler 里面实现任务的切换,所以还是可以归结为中断。 既然这样, FreeRTOS 对临界段的保护最终还是回到对中断的开和关的控制 。
5、FreeRTOS任务管理机制
从系统的角度看,任务是竞争系统资源的最小运行单元。 在FreeRTOS 中,各个任务内存空间不共享,独立运行。FreeRTOS 调度器决定运行哪个任务 ,在任务切入切出时保存上下文环境(寄存器值、堆栈内容)是调度器主要的职责。 为了实现这点,每个 FreeRTOS 任务都需要有自己的栈空间。
包括优先级调度、时间片轮转、抢占式调度和事件驱动调度。
1、优先级调度,在FreeRTOS中,每个任务都可以设置一个优先级,优先级高的优先执行。优先级的范围由宏定义 configMAX_PRIORITIES 确定,默认情况下优先级越高的任务被认为越重要。
xTaskCreate(TaskA, "Task A", 100, NULL, 3, NULL); // 任务A的优先级为3
xTaskCreate(TaskB, "Task B", 100, NULL, 1, NULL); // 任务B的优先级为1
在上述代码中,任务A的优先级比任务B高,因此调度器会先执行任务A。即使任务B已经准备就绪,调度器会选择优先级更高的任务A。
2、时间片轮转,当多个任务具有相同优先级的时候,FreeRTOS 采用时间片轮转调度(Round Robin Scheduling)。这意味着每个任务可以在CPU运行固定时间片,时间片结束后切换到下一个任务。调度器使用系统时钟滴答(tick)来确定时间片的长度。时间片轮转确保了相同优先级的任务能够公平分享CPU资源。
void vTaskDelay( TickType_t xTicksToDelay );
3、抢占式调度
FreeRTOS默认使用抢占式调度(preemptive scheduling),这意味着当一个优先级更高的任务变为就绪状态时,它将立刻抢占当前运行的任务。
vTaskPrioritySet( TaskBHandle, 4 ); // 提升任务B的优先级到4
4、事件驱动调度
任务的调度不仅依赖优先级和时间片,还可以基于事件驱动。例如,当任务等待一个队列中的数据时,系统会将任务置于Blocked状态,直到数据可用时任务才会进入就绪状态。
xQueueReceive(queueHandle, &data, portMAX_DELAY); // 阻塞等待队列数据
6、任务状态转移
FreeRTOS 内核中采用两种方法寻找最高优先级的任务,第一种是通用的方法,在就绪链表中查找从高优先级往低查找 uxTopPriority,因为在创建任务的时候已经将优先级进行排序,查找到的第一个 uxTopPriority 就是我们需要的任务,然后通过 uxTopPriority 获取对应的任务控制块。第二种方法则是特殊方法,利用计算前导零指令 CLZ,直接在uxTopReadyPriority 这个 32 位的变量中直接得出 uxTopPriority,这样子就知道哪一个优先级任务能够运行,这种调度算法比普通方法更快捷,但受限于平台(在 STM32 中我们就使用这种方法) 。
FreeRTOS 内核中也允许创建相同优先级的任务。相同优先级的任务采用时间片轮转方式进行调度(也就是通常说的分时调度器),时间片轮转调度仅在当前系统中无更高优先级就绪任务存在的情况下才有效。
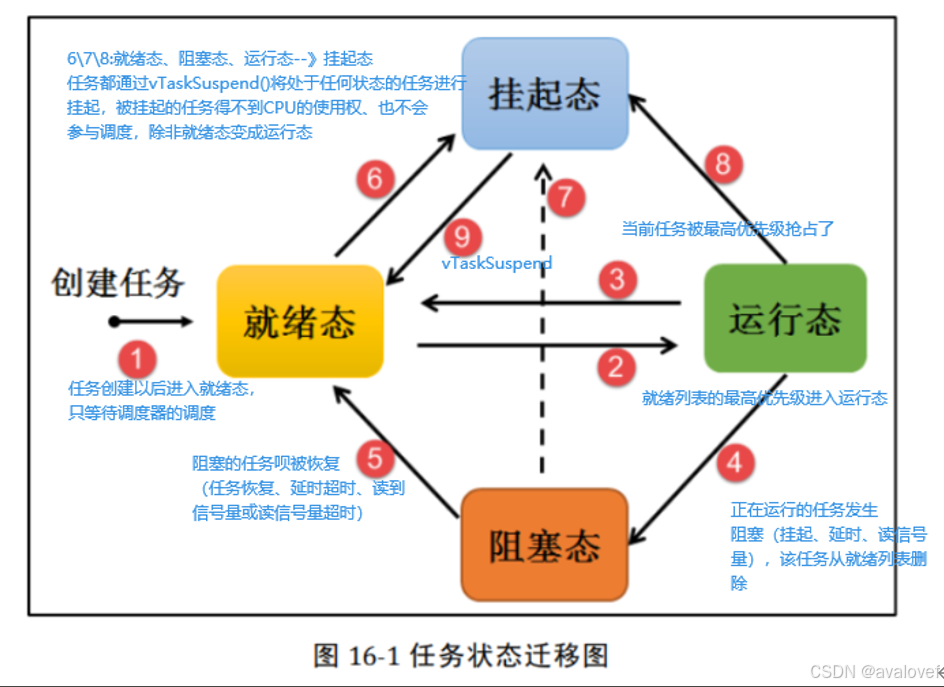
3:运行→就绪态:更高优先级任务创建或者恢复后,会发生任务调度,此刻就绪列表中最高优先级任务变为运行态,那么原先运行的任务由运行态变为就绪态,依然在就绪列表中,等待最高优先级的任务运行完毕继续运行原来的任务(此处可以看做是 CPU 使用权被更高优先级的任务抢占了)。
9:起态→就绪态: 把 一 个 挂 起 状态 的 任 务 恢复的 唯 一 途 径 就 是调 用 vTaskResume() 或 vTaskResumeFromISR() API 函数
与阻塞态的区别:当任务有较长的时间不允许运行的时候,我们可以挂起任务,这样子调度器就不会管这个任务的任何信息,直到我们调用恢复任务的 API 函数;而任务处于阻塞态的时候,系统还需要判断阻塞态的任务是否超时,是否可以解除阻塞 。
7、任务间的传递方式
1.消息队列:
操作系统里面,直接使用全局变量传输数据十分危险,看似正常运行,但不知道啥时候就会因为寄存器或者内存等等原因引起崩溃,所以引入消息,队列的概念,任务发送数据到队列,需要接受消息的任务挂起在队列的挂起列表,等待消息的到来。消息队列是异步通信方式,当队列中有新消息时,被阻塞的任务会被唤醒并处理新消息;当等待的时间超过了指定的阻塞时间,即使队列中尚无有效数据,任务也会自动从阻塞态转为就绪态。
消息队列可以应用于发送不定长消息的场合,包括任务与任务间的消息交,可以在任务与任务间、中断和任务间传送信息,发送到队列的消息是通过拷贝方式实现的, 这意味着队列存储的数据是原数据,而不是原数据的引用。
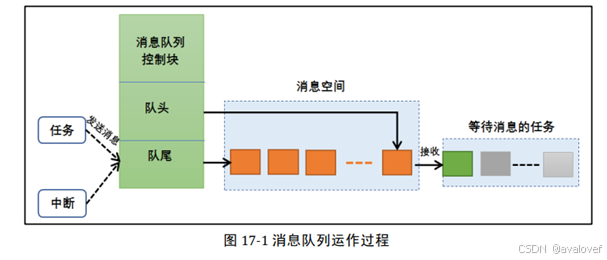
消息支持先进先出方式排队,支持异步读写工作方式。 读写队列均支持超时机制 。消息支持后进先出方式排队, 往队首发送消息(LIFO) 。以允许不同长度(不超过队列节点最大值)的任意类型消息 。一个任务能够从任意一个消息队列接收和发送消息。多个任务能够从同一个消息队列接收和发送消息。 当队列使用结束后,可以通过删除队列函数进行删除。
static void Receive_Task(void* parameter)
{
BaseType_t xReturn = pdTRUE;/* 定义一个创建信息返回值,默认为pdTRUE */
uint32_t r_queue; /* 定义一个接收消息的变量 */
while (1)
{
xReturn = xQueueReceive( Test_Queue, /* 消息队列的句柄 */
&r_queue, /* 发送的消息内容 */
portMAX_DELAY); /* 等待时间 一直等 ,阻塞,过了还没收到就返回错误代码继续执行*/
if(pdTRUE == xReturn)
printf("本次接收到的数据是%d\n\n",r_queue);
else
printf("数据接收出错,错误代码0x%lx\n",xReturn);
}
}
static void Send_Task(void* parameter)
{
BaseType_t xReturn = pdPASS;/* 定义一个创建信息返回值,默认为pdPASS */
uint32_t send_data1 = 1;
uint32_t send_data2 = 2;
while (1)
{
if( Key_Scan(KEY1_GPIO_PORT,KEY1_PIN) == KEY_ON )
{/* K1 被按下 */
printf("发送消息send_data1!\n");
xReturn = xQueueSend( Test_Queue, /* 消息队列的句柄 */
&send_data1,/* 发送的消息内容 */
0 ); /* 等待时间 0 */
if(pdPASS == xReturn)
printf("消息send_data1发送成功!\n\n");
}
if( Key_Scan(KEY2_GPIO_PORT,KEY2_PIN) == KEY_ON )
{/* K2 被按下 */
printf("发送消息send_data2!\n");
xReturn = xQueueSend( Test_Queue, /* 消息队列的句柄 */
&send_data2,/* 发送的消息内容 */
0 ); /* 等待时间 0 */
if(pdPASS == xReturn)
printf("消息send_data2发送成功!\n\n");
}
vTaskDelay(20);/* 延时20个tick */
}
}
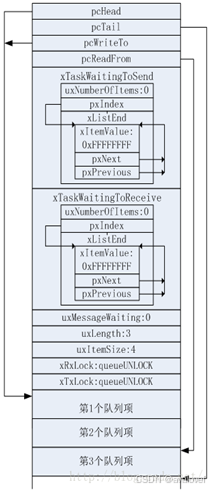
同时要注意消息队列的结构体,假设我们申请了3个队列项,每个队列项占用4字节存储空间(即uxLength=3、uxItemSize=4),则经过初始化后的队列内存如图1-2所示。(这个图形象的描述了队列结构体的大部分成员的作用)。在中断中使用队列要记得上锁。
2.信号量
信号量(Semaphore)是一种实现任务间通信的机制,可以实现任务之间同步或临界资源的互斥访问 。0:阻塞任务,正值:表示有一个或者多个释放信号量操作。
二值信号量:没有优先级继承,这使得二值信号量更偏向应用于同步功能(任务与任务间的同步或任务和中断间同步)。FreeRTOS 中我们用信号量用于同步,任务与任务的同步,中断与任务的同步(类似于进中断给flag,外部再判断flag同步)。
计数信号量:计数信号量肯定是用于计数的,在实际的使用中,我们常将计数信号量用于事件计数与资源管理。
递归信号量:对于已经获取递归互斥量的任务可以重复获取该递归互斥量, 该任务拥有递归信号量的所有权。 任务成功获取几次递归互斥量, 就要返还几次,在此之前递归互斥量都处于无效状态, 其他任务无法获取, 只有持有递归信号量的任务才能获取与释放。
信号量的结构体与消息队列大体一致,只是多了xMessagesWaiting,uxLength, uxItemSize(0).
3.互斥量
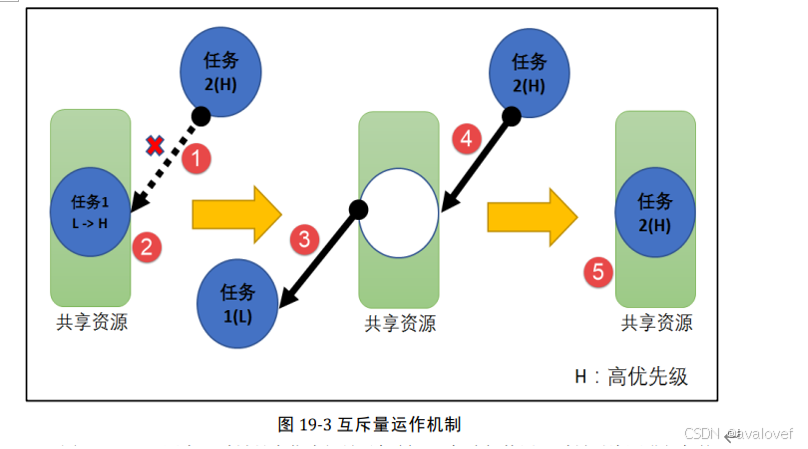
互斥量有优先级继承机制,互斥量更偏向应用于临界资源的访问。 它和信号量不同的是,它支持互斥量所有权、递归访问以及防止优先级翻转的特性.任意时刻互斥量的状态只有两种,开锁或闭锁。
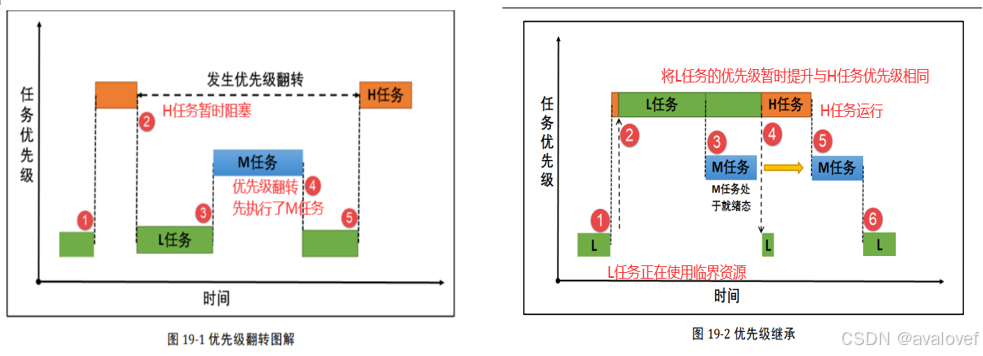
互斥量的优先级继承机制:优先级继承算法是指,暂时提高某个占有某种资源的低优先级任务的优先级,使之与在所有等待该资源的任务中优先级最高那个任务的优先级相等,而当这个低优先级任务执行完毕释放该资源时,优先级重新回到初始设定值。因此,继承优先级的任务避免了系统资源被任何中间优先级的任务抢占 。
在获得互斥量后,请尽快释放互斥量,同时需要注意的是在任务持有互斥量的这段时间,不得更改任务的优先级。 FreeRTOS 的优先级继承机制不能解决优先级反转,只能将这种情况的影响降低到最小, 硬实时系统在一开始设计时就要避免优先级反转发生。
4.事件
a 概述
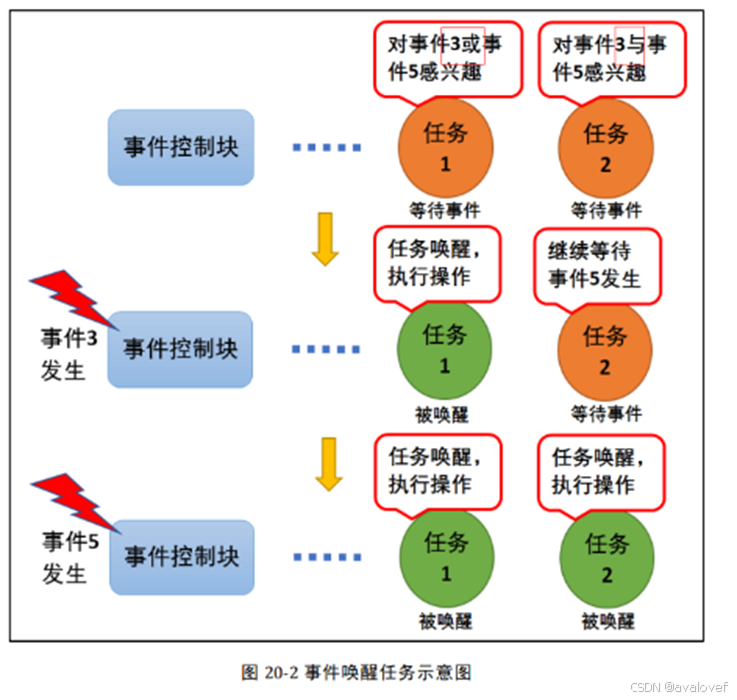
为了节约cpu资源,保证多任务进行访问,推出了事件。事件是一种实现任务间通信的机制,主要用于实现多任务间的同步,但事件通信只能是事件类型的通信,无数据传输。与信号量不同的是,它可以实现一对多,多对多的同步。
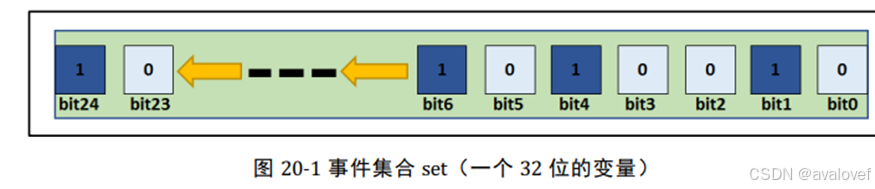
事件只与任务相关联,事件相互独立,一个 32 位的事件集合(EventBits_t 类型的 变量,实际可用与表示事件的只有 24 位),用于标识该任务发生的事件类型,其 中每一位表示一种事件类型(0 表示该事件类型未发生、 1 表示该事件类型已经发生),一共 24 种事件类型。事件仅用于同步,不提供数据传输功能。 事件无排队性,即多次向任务设置同一事件(如果任务还未来得及读走), 等效于只设置一次。允许多个任务对同一事件进行读写操作。 支持事件等待超时机制。
在 FreeRTOS 事件中, 每个事件获取的时候,用户可以选择感兴趣的事件,并且选择读取事件信息标记,它有三个属性,分别是逻辑与,逻辑或以及是否清除标记。
b 与信号量的不同
i)事件的发送操作不可以累积。 ii)事件可以对应多个任务(相互),可以选择逻辑或与进行触发。
c.事件不与任务相关联,事件相互独立,一个 32 位的变量(事件集合,实际用于表示事件的只有 24 位),用于标识该任务发生的事件类型,其中每一位表示一种事件类型(0 表示该事件类型未发生、 1 表示该事件类型已经发生)
8、TCB和PCB
线程控制块(TCB)与进程控制块(PCB):
TCB:线程ID、线程状态寄存器、锁和信号量等同步机制与上下文信息、线程优先级
PCB:线程ID、进程状态寄存器、锁和信号量等同步机制与上下文信息、进程优先级和等待事件以及其他内存、内存空间范围、线程状态、文件描述符。
线程上下文切换保存的内容:TCB块、寄存器状态(R0-R3\SP\LR\PC)、程序状态字(程序处于中断、用户态、内核态等等标志位)、堆栈(线程执行期间所用的变量等信息)、浮点FPU寄存器。
进程上下文切换保存的内容:PCB、CPU寄存器、浮点寄存器、用户栈、内核数据结构(内表、进程表、文件表)。


















 1290
1290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









