







最近在整理大语言模型的系列内容,Stable Diffusion 是我下一篇博客的主题。关注 Stable Diffusion,是因为它是目前最受欢迎和影响力最大的多模态生成模型之一。Stable Diffusion 于 2022 年 8 月发布,主要用于根据文本的描述产生详细图像,当然它也可以应用于其他任务,比如内补绘制、外补绘制,以及在提示词指导下,对现有图形进行风格化或转变。Stable Diffusion 模型版本正在快速迭代,开源生态也在逐步扩展,对行业生产力带来了巨大的变革。如今出现了很多的开源软件,通过调用 Stable Diffusion 来支持各种功能,并提供简洁的用户界面以方便设计师和爱好者使用。然而 Stable Diffusion 的大规模部署不是一件简单的事情,需要考虑多种因素:
亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库!
- 个性化和可扩展性:Stable Diffusion 生态广泛,仅广泛使用的基础模型就有 1.5 ,XL 和 2 三个版本。同时大量的插件和附加模型(如 LoRA ,ControlNet 等)可被附加到基础模型上。还可针对特定工作场景(如人像生成)进行精细化调优。这些模型和插件也都在不断迭代。在大规模部署时,针对不同的工作场景可以使用不同的模型进行模型推理,这对整个系统可扩展性要求很高。
-
推理速度:Stable Diffusion 的基础模型是在亚马逊云计算服务上使用 256 个 NVIDIA A100 GPU 训练,共花费 15 万个 GPU 小时,成本为 60 万美元。而这只是基础模型,对于调用基础模型并加载个性化数据进行推理的应用场景来说,需要使用加速计算芯片(如 NVIDIA GPU 或亚马逊云科技的 Inferentia 芯片)来提升单任务推理速度,降低用户等待时间,提升用户体验。
-
弹性伸缩:在多种业务场景中,使用者的请求有较大的不确定性。从平衡成本的角度出发,需要考虑在请求较多时快速增加推理实例数量以应对请求,而在请求较少时降低实例数量以降低成本。
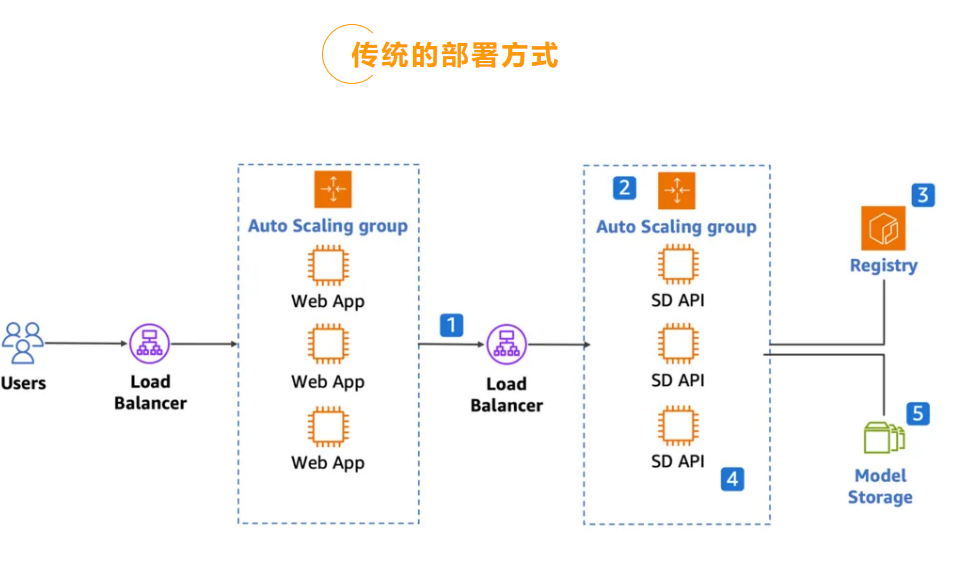
上图是一个常见的大语言模型在容器集群上的部署方式,这种部署方式存在以下问题:
-
所有请求都是同步的。由于模型推理相对比较耗时,每个请求耗时可达几十秒,甚至几分钟。这不仅要求客户与后端之间的网络绝对稳定,在流量突增且没有限流手段时,甚至会导致系统雪崩。
-
常见的自动扩容策略是基于 CPU 或 GPU 利用率的指标跟踪,无法直观反应系统负载,且触发时间长,无法应对突增请求。但如果为了避免冷启动而保留大量的空闲容量,则资源在低谷期大量闲置,空置成本高昂。
-
在弹性伸缩拉起新实例后,还需要加载 Stable Diffusion 运行时和模型才能对外提供服务。Stable Diffusion 运行时的容器镜像普遍在 10 GB 以上,新实例下载镜像和解压耗费的时间过长,导致冷启动时间过长,大大影响使用者的体验。
-
Stable Diffusion 模型通常使用存放在块存储或文件存储中,每次加载模型时候拉取性能受限,成本也较高。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 9449
9449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









