







DeepSeek-R1是一款功能强大且成本很低的AI模型,在处理复杂推理任务方面表现出色,与Amazon OpenSearch Service结合使用时,它可以支持强大的检索增强生成(RAG)应用。本文将介绍如何在Amazon SageMaker上使用DeepSeek-R1配置RAG系统,并将Amazon OpenSearch Service向量数据库作为知识库,这一示例为希望提升AI能力的企业提供了可行的解决方案。
Amazon OpenSearch Service为RAG用例和基于向量嵌入的语义搜索提供丰富的功能。通过Amazon OpenSearch Service中灵活的连接器框架和搜索流程管道,您可以轻松地连接到由DeepSeek、Cohere、OpenAI等提供的模型,以及部署在Amazon Bedrock和Amazon SageMaker上的模型。本文将介绍如何连接DeepSeek文本生成模型,通过RAG工作流来实现对用户提问的自动文本回答。
解决方案概述
下图说明了解决方案的架构。
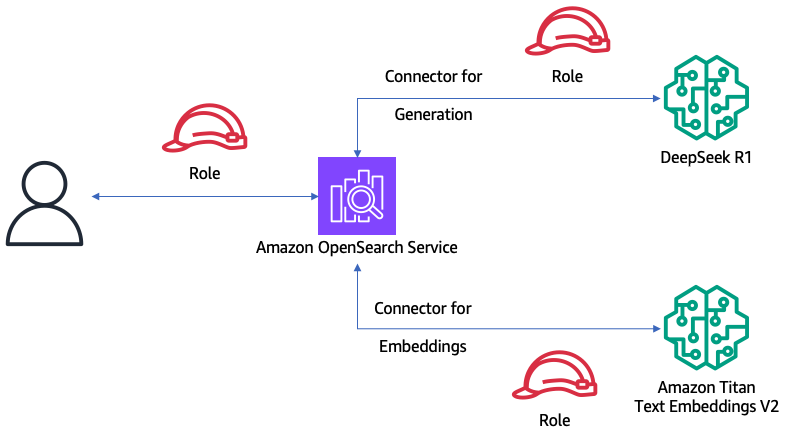
在本操作指南中,您将使用一系列脚本来创建上述架构和数据流。
首先,您需要创建一个Amazon OpenSearch Service域,并将DeepSeek-R1部署到Amazon SageMaker。然后,执行脚本将创建一个用于调用Amazon SageMaker的Amazon IAM角色,以及一个允许用户创建Amazon SageMaker连接器的角色。随后创建Amazon OpenSearch Service连接器和模型,使Amazon OpenSearch Service中的RAG处理器能够执行用户查询、搜索等操作,并使用DeepSeek生成文本响应。您还需要创建一个连接到Amazon SageMaker的连接器,通过Amazon Titan Text Embeddings V2模型生成一组包含人口统计数据的文档的向量嵌入表示。最后执行查询,比较迈阿密和纽约市的人口增长情况。
准备条件
本演示已经创建并开源了包含操作所需全部代码的GitHub代码库,方便您自行部署。开始操作之前,您需要满足以下条件。
Git操作:复制以下链接进行代码库克隆。
Python:代码已在Python 3.13版本上测试通过。
亚马逊云科技账户:您需要能够创建一个Amazon OpenSearch Service域和两个Amazon SageMaker端点。
集成开发环境(IDE):虽然并非绝对必要,但使用诸如Visual Studio Code之类的IDE会很有帮助。
Amazon CLI:确保使用计划使用的账户配置Amazon CLI,或者参考Boto 3文档确保使用正确的凭证。
克隆代码库:
https://github.com/Jon-AtAWS/opensearch-examples.git
Amazon CLI:
http://aws.amazon.com/cli
Boto 3文档:
https://boto3.amazonaws.com/v1/documentation/api/latest/guide/credentials.html
在Amazon SageMaker上
部署DeepSeek
您需要使用Amazon SageMaker端点来部署DeepSeek。要了解关于在Amazon SageMaker上部署DeepSeek-R1的更多信息,请参阅这篇文章:
使用Amazon SageMaker AI在亚马逊云科技上部署DeepSeek-R1蒸馏模型:
https://community.aws/content/2sG84dNUCFzA9z4HdfqTI0tcvKP/deploying-deepseek-r1-on-amazon-sagemaker
创建Amazon OpenSearch Service域
复制下方链接参阅创建Amazon OpenSearch Service域,了解如何创建域。记下域的ARN和域端点,这两者均可在Amazon OpenSearch Service控制台中每个域的“常规信息”部分找到。
创建Amazon OpenSearch Service域:
https://docs.aws.amazon.com/opensearch-service/latest/developerguide/gsgcreate-domain.html
下载并准备代码
在安装了Python和git的本地计算机或工作区中执行以下步骤。
1.如果还未安装,请使用以下命令将存储库克隆到本地文件夹中。
git clone https://github.com/Jon-AtAWS/opensearch-examples.git左右滑动查看完整示意
2.创建一个Python虚拟环境。
cd opensearch-examples/opensearch-deepseek-rag
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt左右滑动查看完整示意
示例脚本使用环境变量来设置一些常用参数,请使用以下命令进行变量设置。请根据您所在的亚马逊云科技区域、Amazon SageMaker端点ARN和URL、Amazon OpenSearch Service域的端点和ARN,以及域的主要用户和密码进行更新。
export DEEPSEEK_AWS_REGION='<your current region>'
export SAGEMAKER_MODEL_INFERENCE_ARN='<your SageMaker endpoint’s ARN>'
export SAGEMAKER_MODEL_INFERENCE_ENDPOINT='<your SageMaker endpoint’s URL>'
export OPENSEARCH_SERVICE_DOMAIN_ARN='<your domain’s ARN>’
export OPENSEARCH_SERVICE_DOMAIN_ENDPOINT='<your domain’s API endpoint>'
export OPENSEARCH_SERVICE_ADMIN_USER='<your domain’s master user name>'
export OPENSEARCH_SERVICE_ADMIN_PASSWORD='<your domain’s master user password>'左右滑动查看完整示意
现在,您已经有了代码库并且完成了虚拟环境的设置,您可以查看opensearch-deepseek-rag目录的内容。为便于阅读,本文将七个步骤分别封装在独立的Python脚本中。本文将指导您运行这些脚本,并且还选择使用环境变量在脚本之间传递参数。在实际解决方案中,您应该将代码封装在类中,并在需要的地方传递这些值。虽然这种编码方式更易理解,但效率较低,也不符合最佳编程实践,请将这些脚本作为参考示例。
首先,您需要为Amazon OpenSearch Service域设置权限,以便连接Amazon SageMaker端点。
设置权限
您将创建两个Amazon IAM角色,第一个角色支持Amazon OpenSearch Service调用Amazon SageMaker端点,第二个角色支持向Amazon OpenSearch Service发出创建连接器的API调用。
检查create_invoke_role.py中的代码。
create_invoke_role.py:
https://github.com/Jon-AtAWS/opensearch-examples/blob/main/opensearch-deepseek-rag/create_invoke_role.py
2.返回命令行并执行该脚本。
python create_invoke_role.py3.根据脚本输出的命令行,执行该命令以设置INVOKE_DEEPSEEK_ROLE环境变量。
现在已经创建了一个名为invoke_deepseek_role的角色,该角色与Amazon OpenSearch Service之间存在信任关系,允许Amazon OpenSearch Service调用Amazon SageMaker端点。脚本会输出角色和策略的ARN,同时还会提供一个命令行指令,用于将该角色添加到您的环境中。请在运行下一个脚本之前执行该命令,记下角色的ARN,以备将来可能需要使用。
您还需要为用户创建一个角色,以便能够在Amazon OpenSearch Service中创建一个连接器。
4.检查create_connector_role.py中的代码。
create_connector_role.py:
https://github.com/Jon-AtAWS/opensearch-examples/blob/main/opensearch-deepseek-rag/create_connector_role.py
5.返回命令行并执行脚本。
python create_connector_role.py左右滑动查看完整示意
6.执行脚本输出中的命令行,设置CREATE_DEEPSEEK_CONNECTOR_ROLE环境变量。
现已创建了一个名为create_deepseek_connector_role的角色,该角色与当前用户建立了信任关系,并获得了对于Amazon OpenSearch Service写入的权限。您需要这些权限来调用Amazon OpenSearch Service的create_connector API,该API用于打包与远程模型主机(本例为DeepSeek)的连接。脚本会输出策略和角色的ARN,并另外提供一条将角色添加到环境中的命令行指令,在运行下一脚本之前,请先执行这个命令。再次提醒,请记下角色的ARN。
角色创建完成后,需将这些角色告知Amazon OpenSearch Service。细粒度访问控制功能包括一个Amazon OpenSearch Service角色ml_full_access,该角色将允许通过身份验证的实体在Amazon OpenSearch Service中执行API调用。
7.检查setup_opensearch_security.py中的代码。
setup_opensearch_security.py:
https://github.com/Jon-AtAWS/opensearch-examples/blob/main/opensearch-deepseek-rag/setup_opensearch_security.py
8.返回命令行并执行脚本。
python setup_opensearch_security.py左右滑动查看完整示意
您已设置Amazon OpenSearch Service的安全插件来识别两个亚马逊云科技角色:invoke_create_connector_role和LambdaInvokeOpenSearchMLCommonsRole。第二个角色将在连接嵌入模型并将数据加载到Amazon OpenSearch Service以用作RAG知识库时使用。现在您已经拥有相应权限,可以开始创建连接器。
创建连接器
创建连接器需要进行配置,该配置会告知Amazon OpenSearch Service如何连接、为目标模型主机提供凭证,以及设置提示词的详细内容。如需了解更多信息,请参阅:
为第三方机器学习平台创建连接器:
https://opensearch.org/docs/latest/ml-commons-plugin/remote-models/connectors/
1.检查create_connector.py中的代码。
create_connector.py:
https://github.com/Jon-AtAWS/opensearch-examples/blob/main/opensearch-deepseek-rag/create_connector.py
2.返回命令行并执行脚本。
python create_connector.py左右滑动查看完整示意
3.执行脚本输出中的命令行,设置DEEPSEEK_CONNECTOR_ID环境变量。
该脚本将创建一个用于调用Amazon SageMaker端点的连接器,并返回连接器ID。这个连接器是Amazon OpenSearch Service的一个构造,用于告知Amazon OpenSearch Service如何连接到外部模型主机。您不会直接使用这个连接器,而是需要创建一个Amazon OpenSearch Service模型来使用它。
创建
Amazon OpenSearch Service模型
在Amazon OpenSearch Service中使用机器学习模型时,您需要借助Amazon OpenSearch Service的ml-commons插件来创建模型。机器学习模型是Amazon OpenSearch Service的一个抽象概念,支持您执行各种机器学习任务,比如在索引过程中发送文本进行嵌入,或者在搜索流程中调用大语言模型(LLM)来生成文本。模型接口会提供一个模型组中的模型ID,可在数据摄取流程和搜索流程中使用。
1.检查create_deepseek_model.py中的代码。
create_deepseek_model.py:
https://github.com/Jon-AtAWS/opensearch-examples/blob/main/opensearch-deepseek-rag/create_deepseek_model.py
2.返回命令行并执行脚本。
python create_deepseek_model.py左右滑动查看完整示意
3.执行脚本输出中的命令行,设置DEEPSEEK_MODEL_ID环境变量。
您已经创建了一个Amazon OpenSearch Service机器学习模型组和模型,可用于创建数据摄取和搜索流程。_register API会将模型放置在模型组中,并通过您创建的连接器(connector_id)引用Amazon SageMaker端点。
验证设置
您可以运行查询来验证设置,并确保可以连接到Amazon SageMaker上的DeepSeek,并接收生成的文本,请您完成以下步骤。
1.在Amazon OpenSearch Service控制台中,在导航窗格中的“托管集群”下选择“仪表板”。
2.选择您的域的仪表板。
3.点击Amazon OpenSearch Service Dashboards URL(双栈)链接,打开Amazon OpenSearch Service Dashboards。
4.使用主用户名和密码登录到Amazon OpenSearch Service Dashboards。
5.点击“自行探索”,关闭欢迎对话框。
6.关闭新界面对话框。
7.在“选择租户”对话框中确认全局租户。
8.导航到“开发工具”选项卡。
9.关闭欢迎对话框。
您也可以通过展开导航菜单以显示导航窗格,然后向下滚动到“开发工具”进行访问。
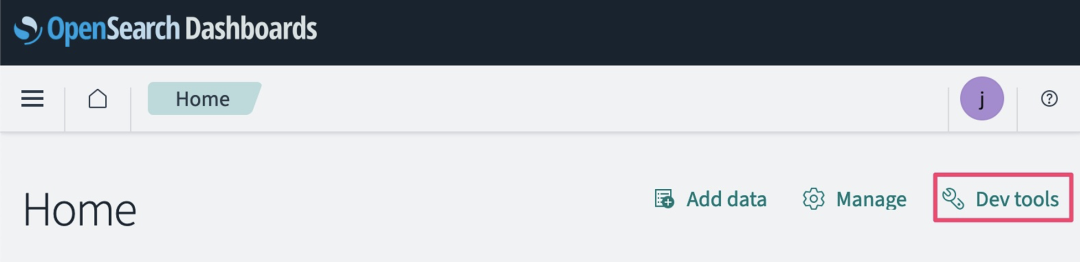
“开发工具”页面的左侧窗格可用于输入REST API调用,执行命令后,右侧窗格会显示命令输出结果。在左侧窗格中输入以下命令,将your_model_id替换为您创建的模型ID,然后将光标放在命令中的任意位置并选择运行图标来执行命令。
POST _plugins/_ml/models/<your model ID>/_predict{ "parameters": { "inputs": "Hello" }}左右滑动查看完整示意
输出结果如下图所示。
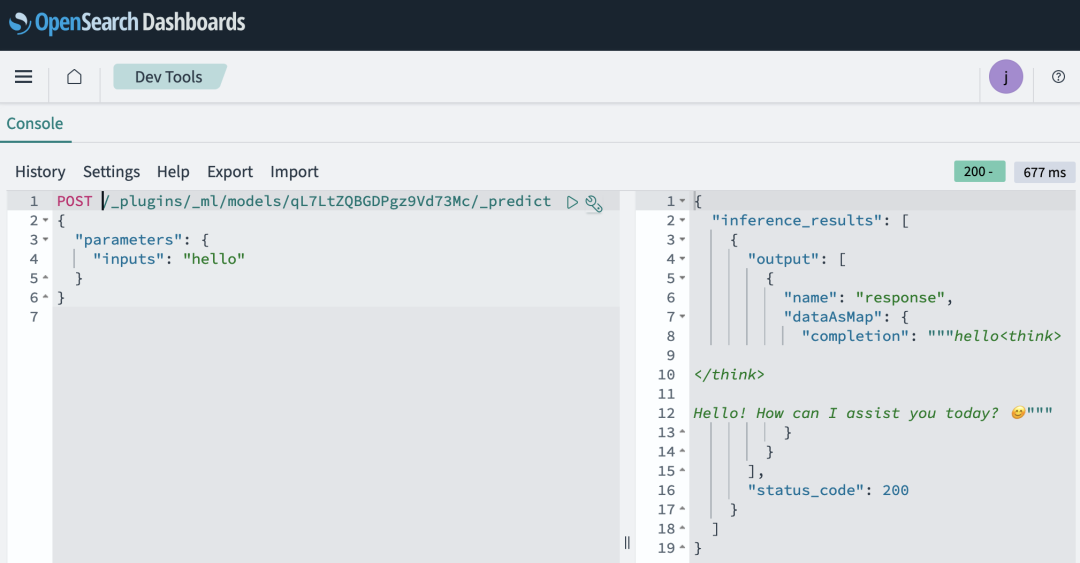
到此您已经创建并部署了一个机器学习模型,该模型可以使用您创建的连接器来调用Amazon SageMaker端点,并使用DeepSeek来生成文本。接下来将介绍在Amazon OpenSearch Service搜索流程中使用模型,自动执行检索增强生成(RAG)工作流。
设置RAG工作流
RAG是一种向提示词添加额外信息的方法,目的是使大语言模型生成的响应更加准确。像聊天机器人这种生成式应用程序会协调调用外部知识库,并利用这些来源的知识来增强提示词,本演示创建了一个包含人口信息的小型知识库。
Amazon OpenSearch Service提供了一组由Amazon OpenSearch Service搜索处理器组成的搜索管道,它们按顺序应用于搜索请求,生成最终结果。Amazon OpenSearch Service拥有混合搜索、重排和RAG等多种处理器。定义好处理器后,您可将查询发送到管道,Amazon OpenSearch Service响应生成最终结果。
Amazon OpenSearch Service搜索处理器:
https://opensearch.org/docs/latest/search-plugins/search-pipelines/search-processors/
混合搜索处理器:
https://opensearch.org/docs/latest/search-plugins/hybrid-search/
重排处理器:
https://opensearch.org/docs/latest/search-plugins/search-relevance/reranking-search-results/
RAG处理器:
https://opensearch.org/docs/latest/search-plugins/search-pipelines/rag-processor/
构建RAG应用时,您需要选择一个知识库和检索机制。大多数情况下,您会使用Amazon OpenSearch Service向量数据库作为知识库,通过执行k近邻(k-NN)搜索,来利用向量嵌入进行语义信息检索。Amazon OpenSearch Service提供了与托管在Amazon Bedrock和Amazon SageMaker以及其他选项中的向量嵌入模型的集成。
确保您的域正在运行Amazon OpenSearch Service 2.9或以上版本,并且已启用细粒度访问控制,然后按照以下步骤操作。
1.在Amazon OpenSearch Service控制台的导航窗格中,选择“集成”。
2.在“通过 Amazon SageMaker与文本嵌入模型集成”下,选择“配置域”。
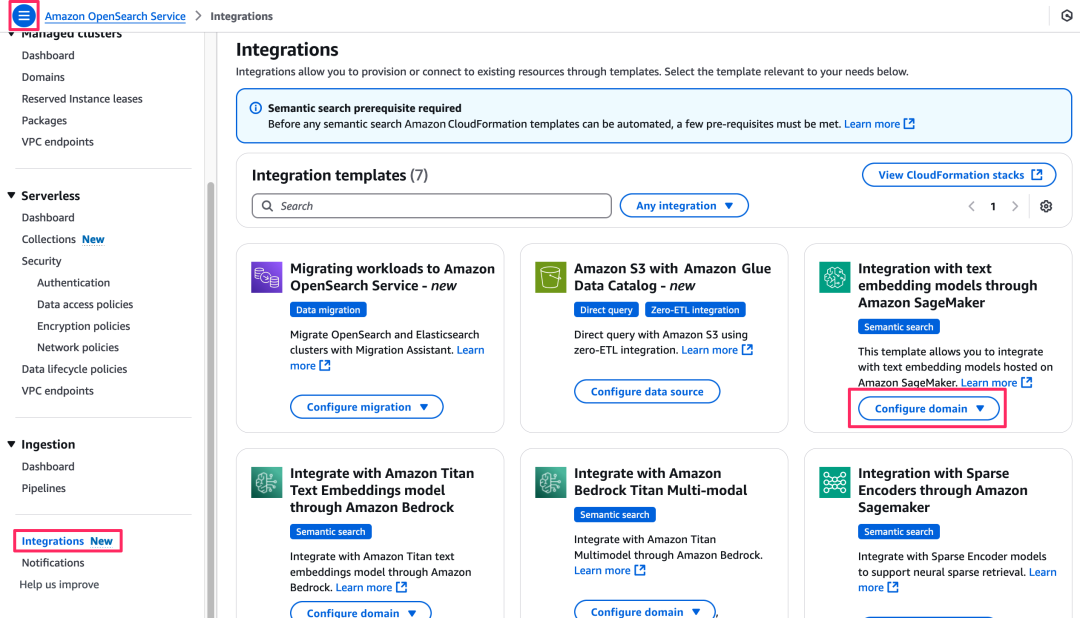
3.选择“配置公共域”。
4.如果您创建的是虚拟私有云(VPC)域,请选择“配置VPC域”,您将被重定向到Amazon CloudFormation控制台。
5.在Amazon OpenSearch Service Endpoint中,输入您的端点。
6.将其他内容保留为默认值。
Amazon CloudFormation堆栈需要一个名为LambdaInvokeOpenSearchMLCommonsRole的角色,用以创建连接到托管在Amazon SageMaker上的all-MiniLM-L6-v2模型的连接器,您在运行setup_opensearch_security.py时已经为此角色启用了访问权限。如果您在该脚本中更改了名称,请确保在“Lambda Invoke OpenSearch ML Commons”字段中同步进行更改。
7.选择“确认Amazon CloudFormation可能创建具有自定义名称的Amazon IAM资源”,然后选择“创建堆栈”。
为简化操作,使用托管在Amazon SageMaker上的开源all-MiniLM-L6-v2模型进行向量嵌入生成。为了在生产工作负载中实现高质量搜索,需要对all-MiniLM-L6-v2等轻量级模型进行微调,或者使用Amazon OpenSearch Service与Amazon Bedrock上的Cohere Embed V3或Amazon Titan Text Embedding V2等模型进行集成,可以提供开箱即用的高质量效果。
等待Amazon CloudFormation部署堆栈,并将状态变更为“创建完成”。
8.在Amazon CloudFormation控制台,选择堆栈的“输出”选项卡并复制ModelID的值。
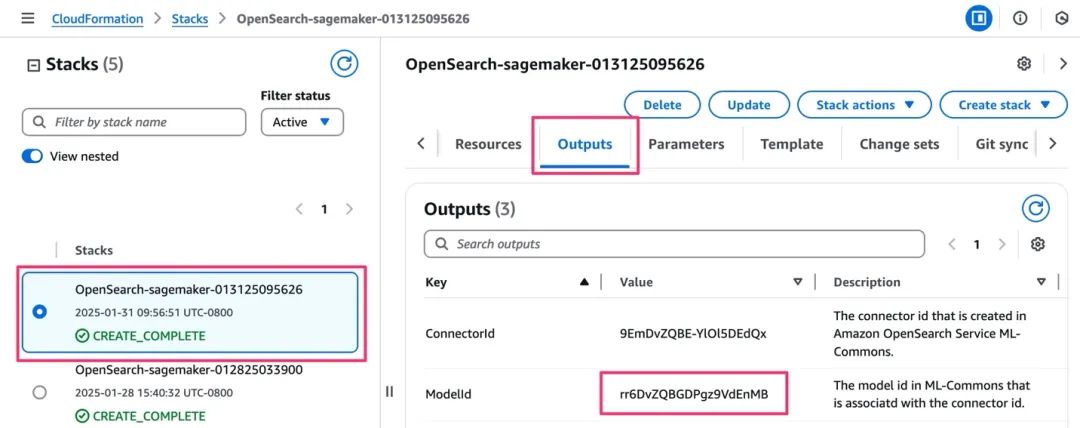
您将使用此模型ID连接嵌入模型连接。
9.检查load_data.py中的代码。
load_data.py:
https://github.com/Jon-AtAWS/opensearch-examples/blob/main/opensearch-deepseek-rag/load_data.py
10.返回命令行,使用嵌入模型的模型ID设置环境变量。
export EMBEDDING_MODEL_ID='<the model ID from CloudFormation’s output>'左右滑动查看完整示意
11.执行脚本,将数据加载到域中。
python load_data.py该脚本会创建population_data索引和一个Amazon OpenSearch Service摄取管道,该管道会使用嵌入模型ID引用的连接器调用Amazon SageMaker,摄取管道的字段映射会提示Amazon OpenSearch Service每个文档嵌入的源字段和目标字段。
知识库现已准备就绪,可以运行RAG查询。
12.检查run_rag.py中的代码。
run_rag.py:
https://github.com/Jon-AtAWS/opensearch-examples/blob/main/opensearch-deepseek-rag/run_rag.py
13.返回命令行并执行脚本。
python run_rag.py该脚本创建了一个带有Amazon OpenSearch Service retrieval_augmented_generation处理器的搜索管道,该处理器可自动运行Amazon OpenSearch k-NN查询以检索相关信息,并将信息添加到提示中。它使用generation_model_id和Amazon SageMaker上DeepSeek模型的连接器,为用户问题生成文本响应。Amazon OpenSearch Service神经查询(run_rag.py第55行)负责使用embedding_model_id为k-NN查询生成嵌入。在查询的ext部分,您需要提供用户问题供大语言模型处理。因为参数化和操作与DeepSeek相同,所以即便llm_model设置为bedrock/claude,您也仍在使用DeepSeek生成文本。
接下来检查Amazon OpenSearch Service的输出。用户问题为:2021年至2023年,纽约市的人口增加了多少?与迈阿密相比趋势如何?结果的第一部分显示了Amazon OpenSearch Service从语义查询中检索到的匹配项,即纽约市和迈阿密的人口统计数据,下一部分则包括提示以及DeepSeek的回答。
Okay, so I need to figure out the population increase of New York City from 2021 to 2023 and compare it with Miami's growth.
Let me start by looking at the data provided in the search results.
From SEARCH RESULT 2, I see that in 2021, NYC had a population of 18,823,000.
In 2022, it was 18,867,000, and in 2023, it's 18,937,000.
So, the increase from 2021 to 2022 is 18,867,000 - 18,823,000 = 44,000.
Then from 2022 to 2023, it's 18,937,000 - 18,867,000 = 70,000.
Adding those together, the total increase from 2021 to 2023 is 44,000 + 70,000 = 114,000.
Now, looking at Miami's data in SEARCH RESULT 1. In 2021, Miami's population was 6,167,000, in 2022 it was 6,215,000, and in 2023 it's 6,265,000.
The increase from 2021 to 2022 is 6,215,000 - 6,167,000 = 48,000. From 2022 to 2023, it's 6,265,000 - 6,215,000 = 50,000.
So, the total increase is 48,000 + 50,000 = 98,000.Comparing the two, NYC's increase of 114,000 is higher than Miami's 98,000.
So, NYC's population increased more over that period."左右滑动查看完整示意
恭喜!您已经成功连接嵌入模型,创建了知识库,并结合DeepSeek使用该知识库,生成了关于纽约市和迈阿密人口变化问题的文本回答。您可以参考本文的代码,创建自己的知识库并运行自定义查询。
清理
为避免产生额外费用,请清理已部署的资源。
1.删除Amazon SageMaker上部署的DeepSeek。有关说明,请复制下方链接参阅清理指南。
2.如果Jupyter笔记本已丢失上下文,可以删除端点:
在Amazon SageMaker控制台的导航窗格中,选择“推理”下的“端点”。
选择您的端点,然后选择“删除”。
3.删除用于连接到Amazon SageMaker嵌入模型的Amazon CloudFormation模板。
4.删除您创建的Amazon OpenSearch Service域。
总结
Amazon OpenSearch Service连接器框架是一种访问托管在其他平台的模型的灵活方式,在本例中您连接了在Amazon SageMaker上部署的开源DeepSeek模型。将DeepSeek的推理能力与Amazon OpenSearch Service向量引擎中的知识库相结合,从而能够回答有关比较纽约和迈阿密人口增长的问题。
复制下方链接,了解更多关于Amazon OpenSearch Service的人工智能与机器学习功能。
Amazon OpenSearch Service的人工智能与机器学习功能:
https://docs.aws.amazon.com/opensearch-service/latest/developerguide/ml.html
本篇作者

Jon Handler
亚马逊云科技搜索服务解决方案架构部总监。Jon与OpenSearch和Amazon OpenSearch Service紧密合作,为使用OpenSearch搜索和日志分析工作负载的广大客户提供帮助和指导。

Yaliang Wu
亚马逊云科技软件工程经理,专注于OpenSearch项目、机器学习和生成式AI应用。




星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!


















 9437
9437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









