由于个人安装的Python版本是2.7的,因此此后的相关代码也是该版本。
- 爬取网页所有信息
利用urllib2包来抓取网页的信息,先介绍下urllib2包的urlopen函数。
urlopen:将网页所有信息存到一个object里,我们可通过读取这个object来获得网页信息。例如,我们使用它来获取百度首页信息如下。
import urllib2
f = urllib2.urlopen('http://www.baidu.com')
f.read(100)
通过上面的代码我们读取了百度首页的前100个字符:
'<!DOCTYPE html><html><head><meta http-equiv="content-type" content="text/html;charse'
有时可能会出现编码问题导致打开的是乱码,只需修改下编码格式即可:
f.read(100).decode('utf-8')
通过这种方法我们可以获得链家一个二手房首页的信息:
import urllib2
url = 'http://sz.lianjia.com/ershoufang/pg'
res = urllib2.urlopen(url)
content = res.read().decode('utf-8')
于是网页信息便存在了content之中。
data-el="region">万科第五园一期</a> | 3室2厅 | 104.58平米 | 南 | 精装</div><
import urllib2
import re
url = 'http://sz.lianjia.com/ershoufang/pg/'
res = urllib2.urlopen(url)
content=res.read().decode('utf-8')
result = re.findall(r'>.{1,100}?</div></div><div class="flood">',content)
for i in result:
print(i[0:-31].decode('utf-8'))
运行结果如下图:
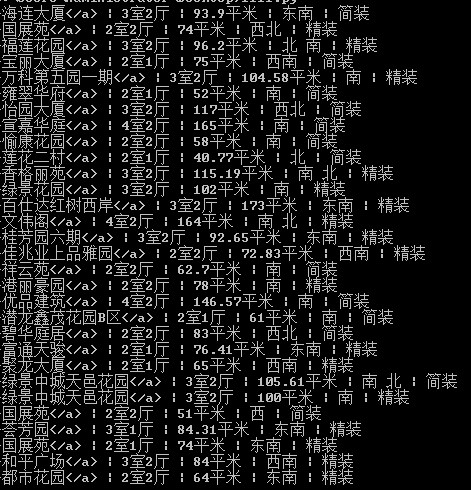
这样就算是获取了我想要的信息了,不过这个信息中间有个我们不想要的符号,接下来还需要去掉这个符号(可见这种方法比较繁琐,效率也偏低)。
在这里我通过字符替换操作,用空字符来替换这个多余字符。
代码为:
import urllib2
import re
url = 'http://sz.lianjia.com/ershoufang/pg/'
res = urllib2.urlopen(url)
content=res.read().decode('utf-8')
result = re.findall(r'>.{1,100}?</div></div><div class="flood">',content)
for i in result:
print(i[0:-31].replace('</a>','').decode('utf-8'))
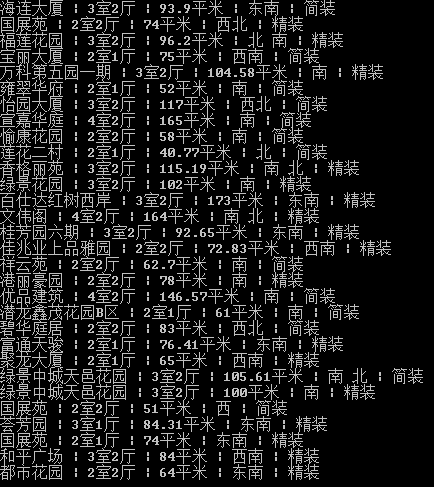
上面的方法虽然帮我们获得了房源信息,但是方法还是有些繁琐,而且效率也并不高
我们利用上面的方法来爬取链家二手房100个页面房源信息,代码修改如下:
import urllib2
import time
import re
print(time.clock())
url = 'http://sz.lianjia.com/ershoufang/pg'
for x in range(101):
finalUrl = url + str(x) + '/'
res = urllib2.urlopen(finalUrl)
content=res.read().decode('utf-8')
result = re.findall(r'>.{1,100}?</div></div><div class="flood">',content)
for i in result:
print(i[0:-31].replace('</a>','').decode('utf-8'))
print(time.clock())
主要是测试一下运行时间,测试结果大概是350s左右(当然,主要还受网速的影响,而对代码本身来说消耗的大多数时间都在urlopen上),接下来,在下一篇中,将利用BeautifulSoup库来实现房源的获取。























 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









