







spark的异常处理
http://slamke.github.io/2017/05/12/Spark%E5%A6%82%E4%BD%95%E5%A4%84%E7%90%86%E5%BC%82%E5%B8%B8/
Spark中的错误处理
https://blog.csdn.net/zrc199021/article/details/52711593
http://blog.rcard.in/big-data/apache-spark/scala/programming/2016/09/25/try-again-apache-spark.html
job
这个job的作用是把HBase中的16进制数据,转成对应格式的十进制数据后存入hive表中,只不过由于数据量非常大,导致job运行时间长,可能出现的问题不好预测。
在本机上执行小批量数据的转换都顺利运行
但是在服务器上执行全量数据时就出现很多问题(全量数据大约3个T多)
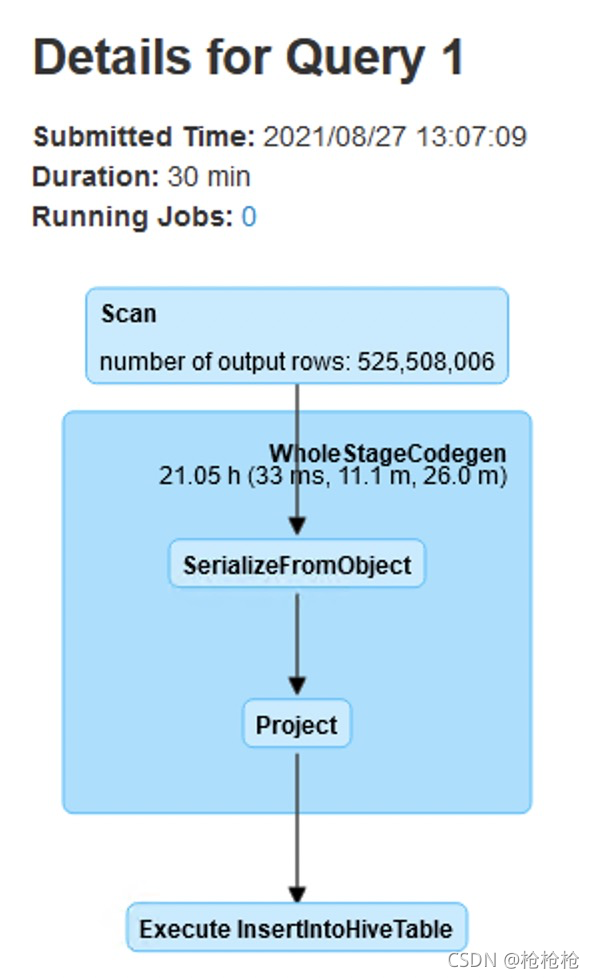 一开始处理1000000数据时,不重新分区的情况下将最终结果写入csv大约需要一小时50分钟,进行重分区,分区数设为500的情况下,时间缩短到1小时。
一开始处理1000000数据时,不重新分区的情况下将最终结果写入csv大约需要一小时50分钟,进行重分区,分区数设为500的情况下,时间缩短到1小时。
但是全量数据下不建议使用重分区操作,对内存资源的使用会加大,可能导致任务失败。

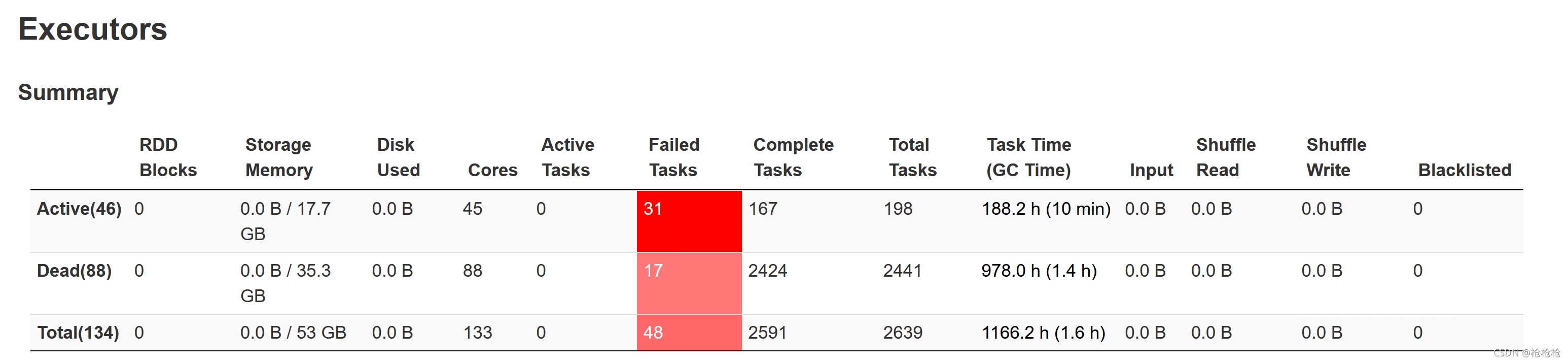
ERROR2
昨晚的一个spark on yarn job在18:40开始运行,第二天早上9:50查看job发现,持续运行时间1个多小时,再一看job状态,提交时间为8:50,job失败后又被重新提交。。。。。。
从集群资源图表上也可以看出,在8点00分时集群资源被释放,原因估计就是job挂了
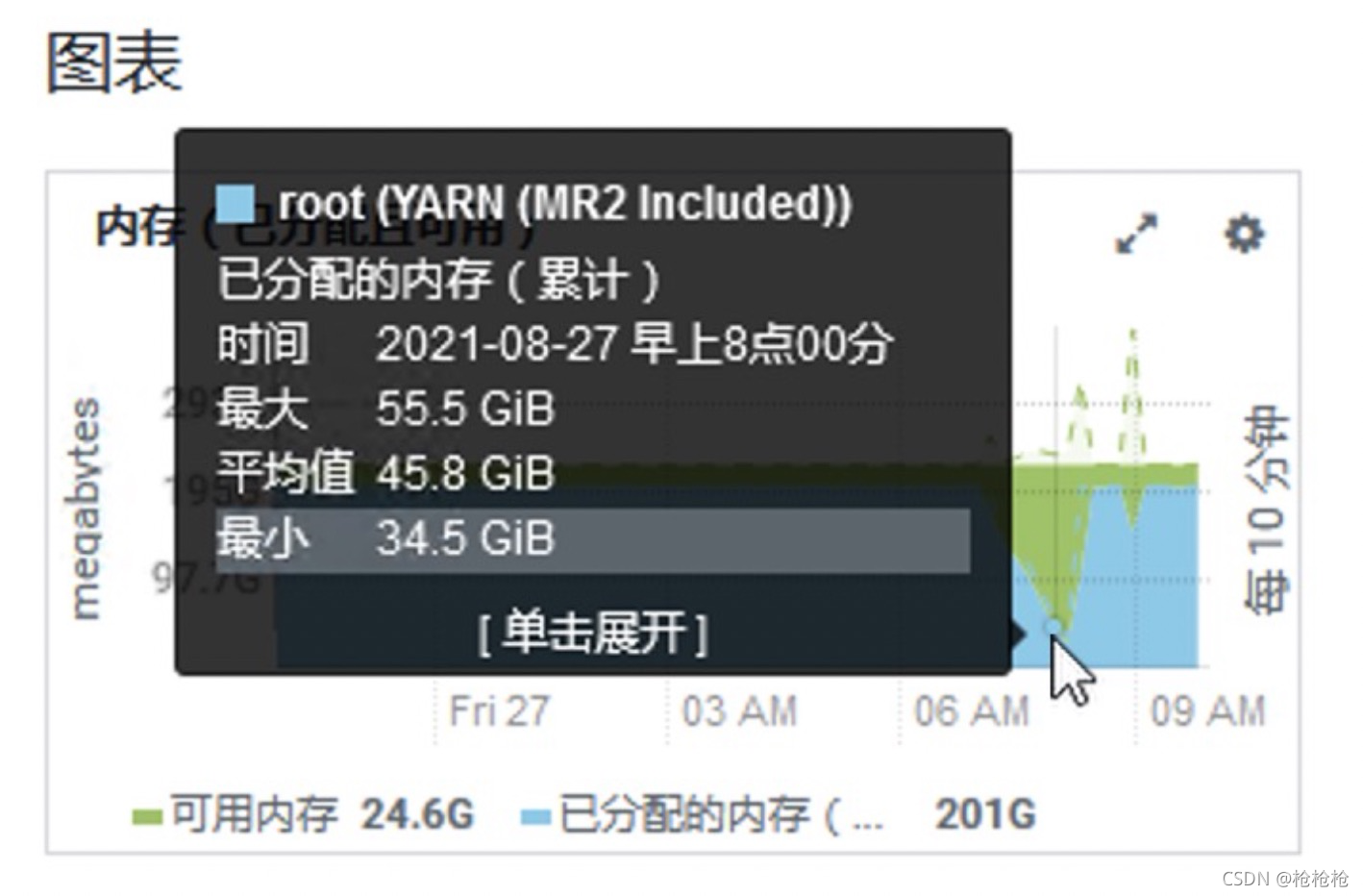
通过命令yanr logs -application application_1629973222908_0001 > /var/tmp/log收集日志后发现一个令人郁闷的情况,收集到的日志只有第二次提交的运行记录,第一次提交运行的记录被刷掉了…(两次提交job的applicationId没有变化)
这就导致无法找到第一次提交运行失败的原因是什么
为了避免这个问题,在第二次提交job时通过--conf "spark.yarn.maxAppAttempts=1"将job的尝试次数设为1,即只被运行一次,失败后不再次运行
在查看资料过程中发现,job的执行次数受两个配置项影响
一是:--conf "yarn.resourcemanager.am.max-attempts=2",这个配置项会影响到全部在yarn上执行的job(默认值一般是2)
二是:--conf "spark.yarn.maxAppAttempts=1"这个配置项只会影响到当前job
当一、二都被设置时会取最小值生效
https://blog.csdn.net/zpf336/article/details/86681030
https://jifei-yang.blog.csdn.net/article/details/109288539
https://blog.csdn.net/yolohohohoho/article/details/90108196
下面的错误信息是一个和HBase有关的异常
官方文档中的描述:
https://hbase.apache.org/apidocs/org/apache/hadoop/hbase/UnknownScannerException.html
以及肯能的原因
https://blog.csdn.net/wuxintdrh/article/details/96983949
解决方法:
https://blog.csdn.net/wuxintdrh/article/details/96983949
在程序中
val hBaseConf = HBaseConfiguration.create()
hBaseConf.setInt("hbase.client.scanner.timeout.period", 600000)
hBaseConf.setInt("hbase.regionserver.lease.period", 1200000)
hBaseConf.setInt("hbase.rpc.timeout", 600000)
org.apache.hadoop.hbase.UnknownScannerException: org.apache.hadoop.hbase.UnknownScannerException: Unknown scanner ‘3626640470295197098’.
org.apache.hadoop.hbase.UnknownScannerException: org.apache.hadoop.hbase.UnknownScannerException: Unknown scanner '-8132455875588644781'. This can happen due to any of the following reasons: a) Scanner id given is wrong, b) Scanner lease expired because of long wait between consecutive client checkins, c) Server may be closing down, d) RegionServer restart during upgrade.
If the issue is due to reason (b), a possible fix would be increasing the value of'hbase.client.scanner.timeout.period' configuration.
at org.apache.hadoop.hbase.regionserver.RSRpcServices.getRegionScanner(RSRpcServices.java:2928)
at org.apache.hadoop.hbase.regionserver.RSRpcServices.scan(RSRpcServices.java:3297)
at org.apache.hadoop.hbase.shaded.protobuf.generated.ClientProtos$ClientService$2.callBlockingMethod(ClientProtos.java:42002)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:413)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:130)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:324)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:304)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.hbase.ipc.RemoteWithExtrasException.instantiateException(RemoteWithExtrasException.java:99)
at org.apache.hadoop.hbase.ipc.RemoteWithExtrasException.unwrapRemoteException(RemoteWithExtrasException.java:89)
at org.apache.hadoop.hbase.shaded.protobuf.ProtobufUtil.makeIOExceptionOfException(ProtobufUtil.java:361)
at org.apache.hadoop.hbase.shaded.protobuf.ProtobufUtil.handleRemoteException(ProtobufUtil.java:349)
at org.apache.hadoop.hbase.client.ScannerCallable.next(ScannerCallable.java:179)
at org.apache.hadoop.hbase.client.ScannerCallable.rpcCall(ScannerCallable.java:244)
at org.apache.hadoop.hbase.client.ScannerCallable.rpcCall(ScannerCallable.java:58)
at org.apache.hadoop.hbase.client.RegionServerCallable.call(RegionServerCallable.java:127)
at org.apache.hadoop.hbase.client.RpcRetryingCallerImpl.callWithoutRetries(RpcRetryingCallerImpl.java:192)
at org.apache.hadoop.hbase.client.ScannerCallableWithReplicas$RetryingRPC.call(ScannerCallableWithReplicas.java:387)
at org.apache.hadoop.hbase.client.ScannerCallableWithReplicas$RetryingRPC.call(ScannerCallableWithReplicas.java:361)
at org.apache.hadoop.hbase.client.RpcRetryingCallerImpl.callWithRetries(RpcRetryingCallerImpl.java:107)
at org.apache.hadoop.hbase.client.ResultBoundedCompletionService$QueueingFuture.run(ResultBoundedCompletionService.java:80)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.hadoop.hbase.ipc.RemoteWithExtrasException(org.apache.hadoop.hbase.UnknownScannerException): org.apache.hadoop.hbase.UnknownScannerException: Unknown scanner '-8132455875588644781'. This can happen due to any of the following reasons: a) Scanner id given is wrong, b) Scanner lease expired because of long wait between consecutive client checkins, c) Server may be closing down, d) RegionServer restart during upgrade.
If the issue is due to reason (b), a possible fix would be increasing the value of'hbase.client.scanner.timeout.period' configuration.
at org.apache.hadoop.hbase.regionserver.RSRpcServices.getRegionScanner(RSRpcServices.java:2928)
at org.apache.hadoop.hbase.regionserver.RSRpcServices.scan(RSRpcServices.java:3297)
at org.apache.hadoop.hbase.shaded.protobuf.generated.ClientProtos$ClientService$2.callBlockingMethod(ClientProtos.java:42002)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:413)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:130)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:324)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:304)
at org.apache.hadoop.hbase.ipc.AbstractRpcClient.onCallFinished(AbstractRpcClient.java:387)
at org.apache.hadoop.hbase.ipc.AbstractRpcClient.access$100(AbstractRpcClient.java:95)
at org.apache.hadoop.hbase.ipc.AbstractRpcClient$3.run(AbstractRpcClient.java:410)
at org.apache.hadoop.hbase.ipc.AbstractRpcClient$3.run(AbstractRpcClient.java:406)
at org.apache.hadoop.hbase.ipc.Call.callComplete(Call.java:103)
at org.apache.hadoop.hbase.ipc.Call.setException(Call.java:118)
at org.apache.hadoop.hbase.ipc.NettyRpcDuplexHandler.readResponse(NettyRpcDuplexHandler.java:162)
at org.apache.hadoop.hbase.ipc.NettyRpcDuplexHandler.channelRead(NettyRpcDuplexHandler.java:192)
at org.apache.hbase.thirdparty.io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:359)
at org.apache.hbase.thirdparty.io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:345)
at org.apache.hbase.thirdparty.io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:337)
at org.apache.hbase.thirdparty.io.netty.handler.codec.ByteToMessageDecoder.fireChannelRead(ByteToMessageDecoder.java:323)
at org.apache.hbase.thirdparty.io.netty.handler.codec.ByteToMessageDecoder.channelRead(ByteToMessageDecoder.java:297)
at org.apache.hbase.thirdparty.io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:359)
at org.apache.hbase.thirdparty.io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:345)
at org.apache.hbase.thirdparty.io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:337)
at org.apache.hbase.thirdparty.io.netty.handler.timeout.IdleStateHandler.channelRead(IdleStateHandler.java:286)
at org.apache.hbase.thirdparty.io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:359)
at org.apache.hbase.thirdparty.io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:345)
at org.apache.hbase.thirdparty.io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:337)
at org.apache.hbase.thirdparty.io.netty.channel.DefaultChannelPipeline$HeadContext.channelRead(DefaultChannelPipeline.java:1408)
at org.apache.hbase.thirdparty.io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:359)
at org.apache.hbase.thirdparty.io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:345)
at org.apache.hbase.thirdparty.io.netty.channel.DefaultChannelPipeline.fireChannelRead(DefaultChannelPipeline.java:930)
at org.apache.hbase.thirdparty.io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read(AbstractNioByteChannel.java:163)
at org.apache.hbase.thirdparty.io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:677)
at org.apache.hbase.thirdparty.io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:612)
at org.apache.hbase.thirdparty.io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:529)
at org.apache.hbase.thirdparty.io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:491)
at org.apache.hbase.thirdparty.io.netty.util.concurrent.SingleThreadEventExecutor$5.run(SingleThreadEventExecutor.java:905)
at org.apache.hbase.thirdparty.io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30)
... 1 more
21/08/27 09:42:59 INFO sort.UnsafeExternalSorter: Thread 61 spilling sort data of 360.0 MB to disk (5 times so far)
21/08/27 09:43:34 INFO sort.UnsafeExternalSorter: Thread 61 spilling sort data of 360.0 MB to disk (6 times so far)
21/08/27 09:44:42 INFO sort.UnsafeExternalSorter: Thread 61 spilling sort data of 360.0 MB to disk (7 times so far)
21/08/27 09:45:28 INFO sort.UnsafeExternalSorter: Thread 61 spilling sort data of 360.0 MB to disk (8 times so far)
21/08/27 09:46:07 INFO sort.UnsafeExternalSorter: Thread 61 spilling sort data of 360.0 MB to disk (9 times so far)
21/08/27 09:47:12 INFO sort.UnsafeExternalSorter: Thread 61 spilling sort data of 360.0 MB to disk (10 times so far)
21/08/27 09:47:59 INFO sort.UnsafeExternalSorter: Thread 61 spilling sort data of 360.0 MB to disk (11 times so far)
21/08/27 09:48:44 INFO sort.UnsafeExternalSorter: Thread 61 spilling sort data of 360.0 MB to disk (12 times so far)
org.apache.hadoop.hbase.UnknownScannerException: org.apache.hadoop.hbase.UnknownScannerException: Unknown scanner '-8132455875588644741'. This can happen due to any of the following reasons: a) Scanner id given is wrong, b) Scanner lease expired because of long wait between consecutive client checkins, c) Server may be closing down, d) RegionServer restart during upgrade.
If the issue is due to reason (b), a possible fix would be increasing the value of'hbase.client.scanner.timeout.period' configuration.
ERROR1
.103:50108, server: bd.vn0109.jmrh.com/172.168.100.104:2181
21/08/24 15:33:23 INFO zookeeper.ZooKeeper: Session: 0x17b2a0cdd42a446 closed
21/08/24 15:33:23 INFO zookeeper.ClientCnxn: EventThread shut down
21/08/24 15:33:23 INFO zookeeper.ClientCnxn: Session establishment complete on server bd.vn0109.jmrh.com/172.168.100.104:2181, sessionid = 0x37b2a0cd92ea37f, negotiated timeout = 60000
21/08/24 15:33:23 INFO mapreduce.TableInputFormatBase: Input split length: 1.1 G bytes.
21/08/24 15:33:28 ERROR executor.Executor: Exception in task 386.0 in stage 0.0 (TID 386)
java.io.IOException: 设备上没有空间
at sun.nio.ch.FileDispatcherImpl.write0(Native Method)
at sun.nio.ch.FileDispatcherImpl.write(FileDispatcherImpl.java:60)
at sun.nio.ch.IOUtil.writeFromNativeBuffer(IOUtil.java:93)
at sun.nio.ch.IOUtil.write(IOUtil.java:51)
at sun.nio.ch.FileChannelImpl.write(FileChannelImpl.java:211)
at sun.nio.ch.FileChannelImpl.transferToTrustedChannel(FileChannelImpl.java:516)
at sun.nio.ch.FileChannelImpl.transferTo(FileChannelImpl.java:612)
at org.apache.spark.util.Utils$.copyFileStreamNIO(Utils.scala:437)
at org.apache.spark.util.Utils$$anonfun$copyStream$1.apply$mcJ$sp(Utils.scala:358)
at org.apache.spark.util.Utils$$anonfun$copyStream$1.apply(Utils.scala:352)
at org.apache.spark.util.Utils$$anonfun$copyStream$1.apply(Utils.scala:352)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1408)
at org.apache.spark.util.Utils$.copyStream(Utils.scala:373)
at org.apache.spark.util.Utils.copyStream(Utils.scala)
at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.writePartitionedFile(BypassMergeSortShuffleWriter.java:201)
at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:163)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
查找资料后发现,可能是一下某个路径的磁盘空间不足导致
资料链接:
https://www.qedev.com/bigdata/194381.html
21/08/24 15:46:09 INFO zookeeper.ZooKeeper: Client environment:java.io.tmpdir=/var/tmp/chickpoint
21/08/24 15:46:09 INFO zookeeper.ZooKeeper: Client environment:java.compiler=<NA>
21/08/24 15:46:09 INFO zookeeper.ZooKeeper: Client environment:os.name=Linux
21/08/24 15:46:09 INFO zookeeper.ZooKeeper: Client environment:os.arch=amd64
21/08/24 15:46:09 INFO zookeeper.ZooKeeper: Client environment:os.version=3.10.0-1160.36.2.el7.x86_64
21/08/24 15:46:09 INFO zookeeper.ZooKeeper: Client environment:user.name=root
21/08/24 15:46:09 INFO zookeeper.ZooKeeper: Client environment:user.home=/root
21/08/24 15:46:09 INFO zookeeper.ZooKeeper: Client environment:user.dir=/var/tmp
在spark-submit 中增加如下参数:
spark在shuffle时产生的临时文件路径
--conf "spark.driver.extraJavaOptions=-Djava.io.tmpdir=/var/tmp/chickpoint"后重新提交任务,暂时未报错。
spark执行时临时目录设置:
--conf spark.local.dir=-D/var/tmp/chickpoint
hadoop临时文件路径:
--conf hadoop.tmp.dir=XXXX
https://www.runexception.com/q/1799
日志:
21/08/24 15:33:28 INFO scheduler.TaskSchedulerImpl: Stage 0 was cancelled
21/08/24 15:33:28 INFO scheduler.DAGScheduler: ShuffleMapStage 0 (csv at ReadHbaseDemo3.scala:141) failed in 1303.26 0 s due to Job aborted due to stage failure: Task 386 in stage 0.0 failed 1 times, most recent failure: Lost task 38 6.0 in stage 0.0 (TID 386, localhost, executor driver): java.io.IOException: 设备上没有空间
at sun.nio.ch.FileDispatcherImpl.write0(Native Method)
at sun.nio.ch.FileDispatcherImpl.write(FileDispatcherImpl.java:60)
at sun.nio.ch.IOUtil.writeFromNativeBuffer(IOUtil.java:93)
at sun.nio.ch.IOUtil.write(IOUtil.java:51)
at sun.nio.ch.FileChannelImpl.write(FileChannelImpl.java:211)
at sun.nio.ch.FileChannelImpl.transferToTrustedChannel(FileChannelImpl.java:516)
at sun.nio.ch.FileChannelImpl.transferTo(FileChannelImpl.java:612)
at org.apache.spark.util.Utils$.copyFileStreamNIO(Utils.scala:437)
at org.apache.spark.util.Utils$$anonfun$copyStream$1.apply$mcJ$sp(Utils.scala:358)
at org.apache.spark.util.Utils$$anonfun$copyStream$1.apply(Utils.scala:352)
at org.apache.spark.util.Utils$$anonfun$copyStream$1.apply(Utils.scala:352)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1408)
at org.apache.spark.util.Utils$.copyStream(Utils.scala:373)
at org.apache.spark.util.Utils.copyStream(Utils.scala)
at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.writePartitionedFile(BypassMergeSortShuffleWri ter.java:201)
at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:163)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:55)
at org.apache.spark.scheduler.Task.run(Task.scala:121)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$11.apply(Executor.scala:407)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1408)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:413)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Driver stacktrace:
21/08/24 15:33:28 INFO scheduler.DAGScheduler: Job 0 failed: csv at ReadHbaseDemo3.scala:141, took 1303.385186 s
21/08/24 15:33:28 INFO executor.Executor: Executor killed task 409.0 in stage 0.0 (TID 409), reason: Stage cancelled
21/08/24 15:33:28 WARN scheduler.TaskSetManager: Lost task 409.0 in stage 0.0 (TID 409, localhost, executor driver): TaskKilled (Stage cancelled)
21/08/24 15:33:29 ERROR datasources.FileFormatWriter: Aborting job a8219ae0-dff6-446a-bd29-1a2c3e6c43b0.
org.apache.spark.SparkException: Job aborted due to stage failure: Task 386 in stage 0.0 failed 1 times, most recent failure: Lost task 386.0 in stage 0.0 (TID 386, localhost, executor driver): java.io.IOException: 设备上没有空间
at sun.nio.ch.FileDispatcherImpl.write0(Native Method)
at sun.nio.ch.FileDispatcherImpl.write(FileDispatcherImpl.java:60)
at sun.nio.ch.IOUtil.writeFromNativeBuffer(IOUtil.java:93)
at sun.nio.ch.IOUtil.write(IOUtil.java:51)
at sun.nio.ch.FileChannelImpl.write(FileChannelImpl.java:211)
at sun.nio.ch.FileChannelImpl.transferToTrustedChannel(FileChannelImpl.java:516)
at sun.nio.ch.FileChannelImpl.transferTo(FileChannelImpl.java:612)
at org.apache.spark.util.Utils$.copyFileStreamNIO(Utils.scala:437)
at org.apache.spark.util.Utils$$anonfun$copyStream$1.apply$mcJ$sp(Utils.scala:358)
at org.apache.spark.util.Utils$$anonfun$copyStream$1.apply(Utils.scala:352)
at org.apache.spark.util.Utils$$anonfun$copyStream$1.apply(Utils.scala:352)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1408)
at org.apache.spark.util.Utils$.copyStream(Utils.scala:373)
at org.apache.spark.util.Utils.copyStream(Utils.scala)
at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.writePartitionedFile(BypassMergeSortShuffleWri ter.java:201)
at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:163)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:55)
at org.apache.spark.scheduler.Task.run(Task.scala:121)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$11.apply(Executor.scala:407)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1408)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:413)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentSta ges(DAGScheduler.scala:1890)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1878)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1877)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1877)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:929)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:929)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:929)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2111)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2060)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2049)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:740)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2081)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.write(FileFormatWriter.scala:167)
at org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelationCommand.run(InsertIntoHadoopFsRelati onCommand.scala:159)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult$lzycompute(commands.scala: 104)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult(commands.scala:102)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.doExecute(commands.scala:122)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:131)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:127)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:155)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:152)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:127)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:80)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:80)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:668)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:668)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:78)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:125)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:73)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:668)
at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:276)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:270)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:228)
at org.apache.spark.sql.DataFrameWriter.csv(DataFrameWriter.scala:656)
at myspark.sql.ReadHbaseDemo3$.main(ReadHbaseDemo3.scala:141)
at myspark.sql.ReadHbaseDemo3.main(ReadHbaseDemo3.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:851)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:167)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:195)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:926)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:935)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.io.IOException: 设备上没有空间
at sun.nio.ch.FileDispatcherImpl.write0(Native Method)
at sun.nio.ch.FileDispatcherImpl.write(FileDispatcherImpl.java:60)
at sun.nio.ch.IOUtil.writeFromNativeBuffer(IOUtil.java:93)
at sun.nio.ch.IOUtil.write(IOUtil.java:51)
at sun.nio.ch.FileChannelImpl.write(FileChannelImpl.java:211)
at sun.nio.ch.FileChannelImpl.transferToTrustedChannel(FileChannelImpl.java:516)
at sun.nio.ch.FileChannelImpl.transferTo(FileChannelImpl.java:612)
at org.apache.spark.util.Utils$.copyFileStreamNIO(Utils.scala:437)
at org.apache.spark.util.Utils$$anonfun$copyStream$1.apply$mcJ$sp(Utils.scala:358)
at org.apache.spark.util.Utils$$anonfun$copyStream$1.apply(Utils.scala:352)
at org.apache.spark.util.Utils$$anonfun$copyStream$1.apply(Utils.scala:352)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1408)
at org.apache.spark.util.Utils$.copyStream(Utils.scala:373)
at org.apache.spark.util.Utils.copyStream(Utils.scala)
at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.writePartitionedFile(BypassMergeSortShuffleWri ter.java:201)
at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:163)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:55)
at org.apache.spark.scheduler.Task.run(Task.scala:121)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$11.apply(Executor.scala:407)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1408)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:413)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Exception in thread "main" org.apache.spark.SparkException: Job aborted.
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.write(FileFormatWriter.scala:198)
at org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelationCommand.run(InsertIntoHadoopFsRelati onCommand.scala:159)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult$lzycompute(commands.scala: 104)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult(commands.scala:102)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.doExecute(commands.scala:122)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:131)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:127)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:155)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:152)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:127)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:80)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:80)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:668)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:668)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:78)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:125)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:73)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:668)
at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:276)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:270)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:228)
at org.apache.spark.sql.DataFrameWriter.csv(DataFrameWriter.scala:656)
at myspark.sql.ReadHbaseDemo3$.main(ReadHbaseDemo3.scala:141)
at myspark.sql.ReadHbaseDemo3.main(ReadHbaseDemo3.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:851)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:167)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:195)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:926)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:935)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
INFO: Will not attempt to authenticate using SASL (unknown error)
hbase 大量session断开
解决方法:
增加会话超时的设置
minSessionTimeout=600000
maxSessionTimeout=900000
修改之后
(unknown error)出现的频率下降很明显,偶尔会出现几次
zookeeper设置客户端连接超时被expired
https://www.cnblogs.com/kuang17/p/10907285.html
21/08/27 13:08:11 INFO zookeeper.ZooKeeper: Client environment:user.dir=/data/hadoop/yarn/nm/usercache/hdfs/appcache/application_1629973222908_0007/container_1629973222908_0007_01_000031
21/08/27 13:08:11 INFO zookeeper.ZooKeeper: Initiating client connection, connectString=172.168.100.171:2181,172.168.100.103:2181,172.168.100.104:2181 sessionTimeout=90000 watcher=org.apache.hadoop.hbase.zookeeper.ReadOnlyZKClient$$Lambda$28/860646470@3c60d909
21/08/27 13:08:12 INFO zookeeper.ClientCnxn: Opening socket connection to server bd.vn0108.jmrh.com/172.168.100.103:2181. Will not attempt to authenticate using SASL (unknown error)
21/08/27 13:08:12 INFO zookeeper.ClientCnxn: Socket connection established, initiating session, client: /172.168.100.105:54482, server: bd.vn0108.jmrh.com/172.168.100.103:2181
21/08/27 13:08:12 INFO zookeeper.ClientCnxn: Session establishment complete on server bd.vn0108.jmrh.com/172.168.100.103:2181, sessionid = 0x27b81f8a8f80bef, negotiated timeout = 90000
21/08/27 13:08:13 INFO mapreduce.TableInputFormatBase: Input split length: 0 bytes.
21/08/27 13:08:20 INFO codegen.CodeGenerator: Code generated in 6193.980826 ms
21/08/27 13:08:20 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2
21/08/27 13:08:20 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
21/08/27 13:08:23 INFO datasources.SQLHadoopMapReduceCommitProtocol: Using output committer class org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
21/08/27 13:08:25 INFO zookeeper.ZooKeeper: Session: 0x27b81f8a8f80bef closed
资料
查看spark job 日志
https://blog.csdn.net/weixin_39572937/article/details/103598117
spark中的job、stage、task
https://blog.csdn.net/wolf_333/article/details/99613193















 1062
1062











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









