







本博客说明
本博客来源于斯坦福大学机器学习课程,对上课学到的知识进行梳理和整理,加上自己的一些思考,形成自己的笔记,有需要的可以借鉴。
线性回归算法
线性回归简单来说就是用一条直线(一个变量时)来描述输入变量与输出之间的关系,并且可以通过这个关系对新输入的数据来预测。但是线性回归得出的模型并不一定是直线,当模型中有多个变量时,可能为一个平面或者更高维图形。
线性回归的模型为:
h
(
x
)
=
x
0
+
θ
1
x
1
+
θ
2
x
2
+
.
.
.
+
θ
n
x
n
h(x)=x_0+\theta_1x_1+\theta_2x_2+...+\theta_nx_n
h(x)=x0+θ1x1+θ2x2+...+θnxn 假设
θ
0
=
1
\theta_0=1
θ0=1,则线性回归模型可以表示为:
h
θ
(
x
)
=
∑
i
=
0
n
θ
i
x
i
h_\theta(x)=\sum_{i=0}^n\theta_ix_i
hθ(x)=i=0∑nθixi 也可以表示成矩阵形式:
h
(
x
)
=
θ
T
x
h(x)=\theta^Tx
h(x)=θTx 为了使模型更准确真实的输出值,则可以采用最小二乘法。最小二乘法(又称最小平方法)是一种数学优化技术。它通过最小化误差的平方和寻找数据的最佳函数匹配。
假设共有
m
m
m组数据,
y
y
y为实际值,则误差函数如下:
J
(
θ
)
=
1
2
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
J(\theta)=\frac12\sum_{i=1}^m(h_\theta(x_i)-y_i)
J(θ)=21i=1∑m(hθ(xi)−yi) 所以只需要找到
θ
\theta
θ使得
J
(
θ
)
J(\theta)
J(θ)最小,就可以得到最接近真实数据的模型。
梯度下降法
梯度下降法,是每走一步查看当前下降最快的方向,一定会停下来,但是可能会陷入局部最优解。梯度下降法依赖于参数初始值,由于初始值的不同,可能会陷入不同的局部最优解。其描述图如下:

其中黑色线条描述了梯度下降的路径。梯度下降算法描述如下:
- 更新第 i i i个参数的值: θ i : = θ i − α ∂ ∂ θ i J ( θ ) \theta_i:=\theta_i-\alpha\frac\partial{\partial \theta_i}J(\theta) θi:=θi−α∂θi∂J(θ),其中 α \alpha α是一个参数,称为学习速度,它控制梯度下降的步长。如果步长太小,会使下降的速度过慢,从而花很长的时间去熟练;但步长太大,又可能使算法越过了最小值。
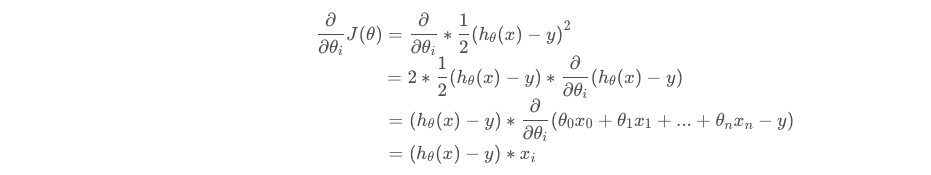
所以,更新函数可以改为:
θ
i
:
=
θ
i
−
α
(
h
θ
(
x
)
−
y
)
∗
x
i
\theta_i\;:=\;\theta_i-\alpha(h_\theta(x)-y)\ast x_i
θi:=θi−α(hθ(x)−y)∗xi 上式是对于只有一组参数的数据进行的推导。下面是对有
m
m
m个参数的时候的推导,也称为批梯度下降法。
θ
i
:
=
θ
i
−
α
∑
j
=
1
m
(
h
θ
(
x
(
j
)
)
−
y
(
j
)
)
∗
x
i
(
j
)
\theta_i\;:=\;\theta_i-\alpha\sum_{j=1}^m(h_\theta(x(j))-y(j))\ast x_i(j)
θi:=θi−αj=1∑m(hθ(x(j))−y(j))∗xi(j)
随机梯度下降法
当参数
m
m
m取值过大时,若直接采用梯度下降法,则迭代的次数将会变得十分庞大,因此可以采用随机梯度下降法。算法描述如下:
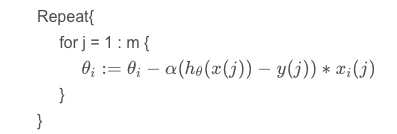
这个算法的好处是:开始学习和修改参数时,只需要查看第一个训练样本,然后利用第一个训练样本开始更新,然后使用第二个更改后的训练样本执行下一次更新,这样使得调整参数的速度会快很多,因为不需要在调整之前遍历所有的样本数据。
缺点是:不一定会精确的收敛到全局最小值,而是在最小值附近徘徊。
矩阵求导
定义一个新的符号。 ∇ θ J = [ ∂ J ∂ θ 0 ⋮ ∂ J ∂ θ n ] ∈ R n + 1 \nabla_\theta J=\begin{bmatrix}\frac{\partial J}{\partial\theta_0}\\\vdots\\\frac{\partial J}{\partial\theta_n}\end{bmatrix}\in R^{n+1} ∇θJ=⎣⎢⎡∂θ0∂J⋮∂θn∂J⎦⎥⎤∈Rn+1 那么上述参数的时候的更新式可重写为: θ : = θ − α ∇ θ J \theta\;:=\;\theta-\alpha\nabla_\theta J θ:=θ−α∇θJ
假设矩阵A是一个n*n的矩阵,那么矩阵A的迹,也就是矩阵A的对角元素和表示方法如下。 I f A ∈ R n + 1 t r A = ∑ i = 1 n A i i If\;\;A\in R^{n+1}\\tr\;A=\sum_{i=1}^nA_{ii} IfA∈Rn+1trA=i=1∑nAii 那么对于m*n维矩阵A,则有: f ( A ) , A ∈ R m ∗ n f(A),\;A\in R^{m\ast n} f(A),A∈Rm∗n ∇ A f ( A ) = ∣ ∂ f ∂ A 11 … ∂ f ∂ A 1 n ⋮ ⋱ ⋮ ∂ f ∂ A m 1 ⋯ ∂ f ∂ A m n ∣ \\\nabla_Af(A)=\begin{vmatrix}\frac{\partial f}{\partial A_{11}}&\dots&\frac{\partial f}{\partial A_{1n}}\\\vdots&\ddots&\vdots\\\frac{\partial f}{\partial A_{m1}}&\cdots&\frac{\partial f}{\partial A_{mn}}\end{vmatrix} ∇Af(A)=∣∣∣∣∣∣∣∂A11∂f⋮∂Am1∂f…⋱⋯∂A1n∂f⋮∂Amn∂f∣∣∣∣∣∣∣
和迹与矩阵求导有关的关键结论
和矩阵的转置、迹以及矩阵求导有关结论如下所示: t r A B = t r B A t r A B C = t r C A B = t r B C A i f f ( A ) = t r A B ∇ A t r A B = B T t r A = t r A T i f a ∈ R , t r a = a ∇ A t r A B A T C = C A B + C T A B T tr\;AB\;=\;tr\;BA\\tr\;ABC\;=\;tr\;CAB\;=\;trBCA\\if\;f(A)=tr\;AB\;\;\;\;\nabla_Atr\;AB\;=\;B^T\\tr\;A\;=\;tr\;A^T\\if\;a\in R,\;\;tr\;a=a\\\nabla_Atr\;ABA^TC=CAB+C^TAB^T trAB=trBAtrABC=trCAB=trBCAiff(A)=trAB∇AtrAB=BTtrA=trATifa∈R,tra=a∇AtrABATC=CAB+CTABT
设计矩阵
假设 x x x为设计矩阵,则有: X θ = [ ( x 1 ) T ( x 2 ) T ⋮ ( x m ) T ] θ X\theta=\begin{bmatrix}{(x_1)}^T\\{(x_2)}^T\\\vdots\\{(x_m)}^T\end{bmatrix}\theta Xθ=⎣⎢⎢⎢⎡(x1)T(x2)T⋮(xm)T⎦⎥⎥⎥⎤θ X θ = [ ( x 1 ) T θ ⋮ ( x m ) T θ ] = [ h θ ( x 1 ) ⋮ h θ ( x m ) ] \\X\theta=\begin{bmatrix}{(x_1)}^T\theta\\\vdots\\{(x_m)}^T\theta\end{bmatrix}=\begin{bmatrix}h_\theta(x_1)\\\vdots\\h_\theta(x_m)\end{bmatrix} Xθ=⎣⎢⎡(x1)Tθ⋮(xm)Tθ⎦⎥⎤=⎣⎢⎡hθ(x1)⋮hθ(xm)⎦⎥⎤ 令 y ⇀ = [ y 1 ⋮ y m ] \\令\overset\rightharpoonup y=\begin{bmatrix}y_1\\\vdots\\y_m\end{bmatrix} 令y⇀=⎣⎢⎡y1⋮ym⎦⎥⎤ 那么有:

其中 Z Z T ZZ^T ZZT表示矩阵的内积,因此,令 ∇ θ J ( θ ) = 0 \nabla_\theta J(\theta)=0 ∇θJ(θ)=0,可以得到如下表达式:

y T y y^Ty yTy与 θ \theta θ无关,所以求导为0。由前面所给出的和迹与矩阵求导有关的关键结论,可以得到下述结果,其中 I I I为单位矩阵。

所以最终 θ \theta θ可以表示为: θ = ( x T x ) − 1 x T y \theta={(x^Tx)}^{-1}x^Ty θ=(xTx)−1xTy















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









