







机器学习-cs229-线性回归part one
任务:预测房价
价格= F(面积,床数)

目标函数:

向量表示:

损失函数cost function
我们最终确定的线性函数 h(x) 上每个x值对应的 h(x) 值 & 真实的y值之间的差别,而差别我们用平方差来表示。

- 注:
– 1/2是为了后续求导时能够约掉平方,对于结果来说无影响
– 这里针对其中一个i的情况,而所有情况是1/2m(如果有m个房间)
– 为什么要用平方?
线性回归的逻辑:
要确定参数θ—》就要确定使得J(θ)最小的θ,让代价函数越低,越靠近样本值----》求J(θ)的极小值----》方法:梯度下降法
梯度下降法
- 梯度:多元函数的导数
表示:
- 梯度下降的式子

这里梯度前面有一个参数η,意义是:沿η率的梯度下降达到更新后的值
-图片表示:

房价函数的梯度下降式子:

学习率learning rate:参数 α
是对梯度做调整,防止步长过大或者过小,错过极小值
由于h(x)由参数θ和x决定,在损失函数中由于
求J(θ)的极小值

所以原来的梯度下降的式子可以写成:

当梯度下降表达式稳定收敛时,我们才能求出对应的参数θ值。
梯度下降算法主要有三种变种,主要区别在于使用多少数据来计算目标函数的梯度。 不同方法主要在准确性和优化速度间做权衡。
方法一:BDG 批量梯度下降,计算整个数据集的梯度
-
优点:
对于凸目标函数,可以保证全局最优; 对于非凸目标函数,可以保证一个局部最优。 -
缺点:
速度慢; 数据量大时不可行; 无法在线优化(即无法处理动态产生的新样本)
单变量示例:

多变量示例:


在多变量里,我们看到一个3维的图,这个图的含义是,底部xy轴是变量,当取不同变量值时,对应的损失函数的值呈现3维上的凸函数:

用矩阵化的形式表示代价函数:

当我们运行BDG方法时,当J(θ)的梯度无限接近于0,则说明此时的θ为我们要的解。
伪代码

方法二:随机梯度下降法
如果使用梯度下降法(批量梯度下降法),那么每次迭代过程中都要对 n个样本进行求梯度,所以开销非常大,随机梯度下降的思想就是随机采样一个样本**J(xi)**来更新参数,那么计算开销就从 O(n)下降到 O(1)。
随机梯度下降虽然提高了计算效率,降低了计算开销,但是由于每次迭代只随机选择一个样本,因此随机性比较大,所以下降过程中非常曲折(图片来自《动手学深度学习》)
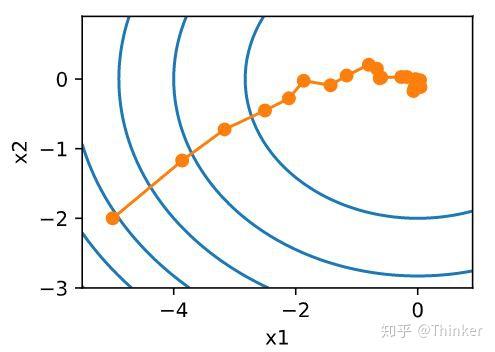
作者:Jackpop
链接:https://www.zhihu.com/question/264189719/answer/932262940

缺点:
对于最优化问题,凸问题,虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近。
优点:
但是相比于批量梯度,这样的方法更快,更快收敛,虽然不是全局最优,但很多时候是我们可以接受的,所以这个方法用的也比上面的多。















 427
427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









