









Sigmoid函数
利用Sigmoid函数来求得回归系数
σ(z)=11+e−z
曲线图如下
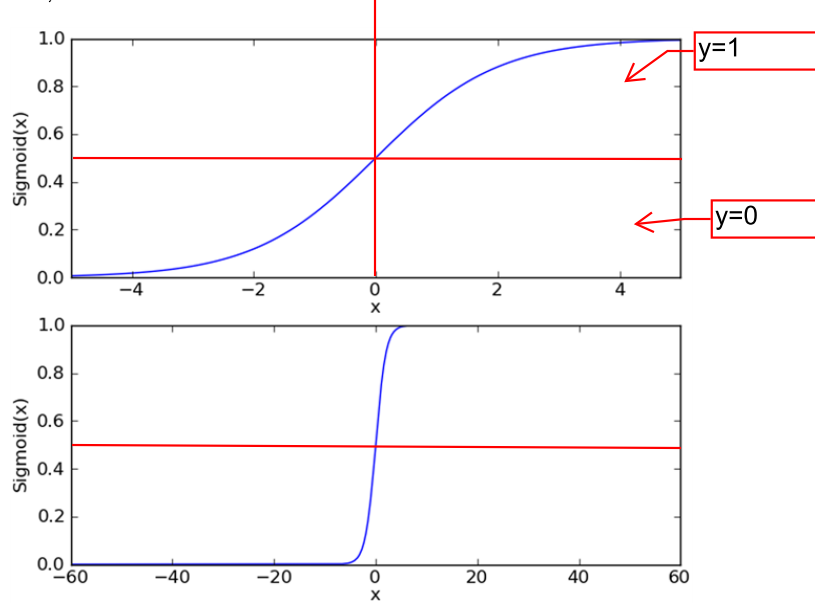
x=0时,Sigmoid函数的值为0.5;
x>0时,Sigmoid函数值大于0.5,x越大,函数值越接近1;
x<0时,Sigmoid函数值小于0.5,x越小,函数值越接近0;
为了实现逻辑回归分类器,在每个特征上都乘以一个回归系数,再把这些乘积相加,把这个和带入Sigmoid函数中的大一个范围在0~1的值。把大于0.5的数值归为1类,小于0.5的数值归为0类(上图中的y是指分类)。
所以,由上所述,sigmoid函数中的z,可以表示为:
z=w0x0+w1x1+w2x2+…+wnxn
问题变成了求最佳回归系数是多少?如何确定它们的大小?
于是
z
式可以采用向量写法可以写成
表示将这两个数值向量对应元素相乘后全部加起来即得到z值。其中 x 是分类器的输入数据,向量
梯度上升法确定决策边界
梯度上升法的基本思想
找到某函数的最大值,最好的方法是沿着该函数的梯度方向探寻。
函数
f(x,y)
的梯度由下式表示:
∇f(x,y)=⎛⎝⎜⎜⎜∂f(x,y)∂x∂f(x,y)∂y⎞⎠⎟⎟⎟
这个梯度意味着要沿 x 轴方向移动
沿梯度的方向移动,移动步长记作 α ,需要不停地迭代直到找到最优点,梯度上升算法的迭代公式如下:
梯度下降算法公式如下:
w:=w−α∇wf(x,y)
梯度上升算法求函数的最大值,梯度下降算法用来求函数的最小值。
该公式会一直被迭代执行,直到达到某个停止条件为止,比如迭代次数达到某个指定值或算法达到某个可以允许的误差范围。
在《Machine Learning in Action》中,作者例子的两行代码不明白:
error = (labelMat - h)
weights = weights + alpha * dataMatrix.transpose()*error这篇文章《学习Machine Leaning In Action(四)》给了推导过程。
随机梯度上升
梯度上升算法在每次更新回归系数时都会遍历整个数据集,当样本数据庞大到上亿和成千上万的特征时,计算复杂度就非常高。随机梯度上升算法就是弥补这个缺陷的。其伪代码,如下:
所有回归系初始化为1
对数据集中每个样本
计算该样本的梯度
使用alpha x gradient 更新回归系数值
返回回归系数值














 339
339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









