










一、引言
本人关于网络爬虫学习的日志已经写了两篇了,这是第三篇。前面两篇是关于从百度搜索和新浪新闻搜索结果爬取数据的学习成果。
网络爬虫学习:从百度搜索结果抓取标题、链接、内容,并保存到xlsx文件中
网络爬虫学习:从新浪新闻搜索抓取所有新闻结果的标题、链接、内容、来源、时间
这次是写的关于从腾*新闻搜索结果获取数据的日志。(本篇日志发布了几次都提示版权不明,未通过,我也不知道问题出在哪里,只能尽量去修改可能的造成不通过的地方。)
二、功能实现
(一)用到的库
本日志代码只用到了一个库:requests。用于以POST方式向腾*网发送请求获取数据,分析工作不需要依赖其它的库,至于将抓取的结果保存到xlsx文件中,关于百度搜索的日志中已经有相关的代码了,这里不再重复。
(二)网页数据分析
最近一个多星期里,我的业余时间都用来研究爬虫技术,研究了好几个常见搜索引擎的数据爬取,积累了一些经验,对关键的爬虫知识也有了一些了解。这次研究腾*网又有了新的收获。
2.1 关于腾*网的搜索参数。
腾*搜索的参数还是比较简单,我所找到的就三个参数:
query:关键字。
page:页号,1-第1页,2-第2页,依此类推。
total:这个参数是可选参数,默认不会有,我也是无意中试出来的。该参数用来限制查到的结果数。经过测试发现实际结果数会大于等于设置的数字且是10的倍数,如设置5,实际会返回10个结果(1页),设置193,实际会返回200个结果(20页)。

(当前就获得了三个参数的含义)
另外page和total组合,可以让查询到的结果产生变化,如下图page设置为5,total设置为15,则返回的结果有2页共20个结果。这些结果与通常将page设置为1时得到的结果是不同的,通过对比,是排序相对靠后的一些结果。
不过在后面的实际爬取中,暂未用到total参数。

(total与page的组合可以使结果发生不同的变化)
2.2 怎样查看网页搜索结果数据
经过初步的研究,当使用前面两篇日志中的get方法向腾*网请求数据,我们获取到的结果并不包含网页浏览器中看到的哪些内容,也即网页真正的源代码无法通过get请求获取到,那么也就无法从网页源代码中查找到当前页面的搜索结果了。这样前面的网页文本分析手段(BeautifulSoup库或lxml库的方法)就用不上了。
response = requests.get(url, headers=headers) # 此方法不适用于腾*搜索引擎既然之前的方法用不上,那么我们又该从哪里获得这些搜索结果的原始数据呢?
还好,经过这些天的学习和探索,我已经积累了一些经验,对于这个问题我还能应付一下。我通过网页浏览器的“开发者工具”中的“网络”子工具对网页数据进行了一番研究,发现搜索结果都在result中。
先点开“网络”子工具界面,选择“Fetch/XHR”,这样可以屏蔽掉其它类型的数据。重新刷新页面,让组成这个页面数据重新下载一遍,刷新一遍后,可以看到“Fetch/XHR”类型的文件陆续出现,腾*网下载的文件不多,可以优先从容量大的文件查看起。
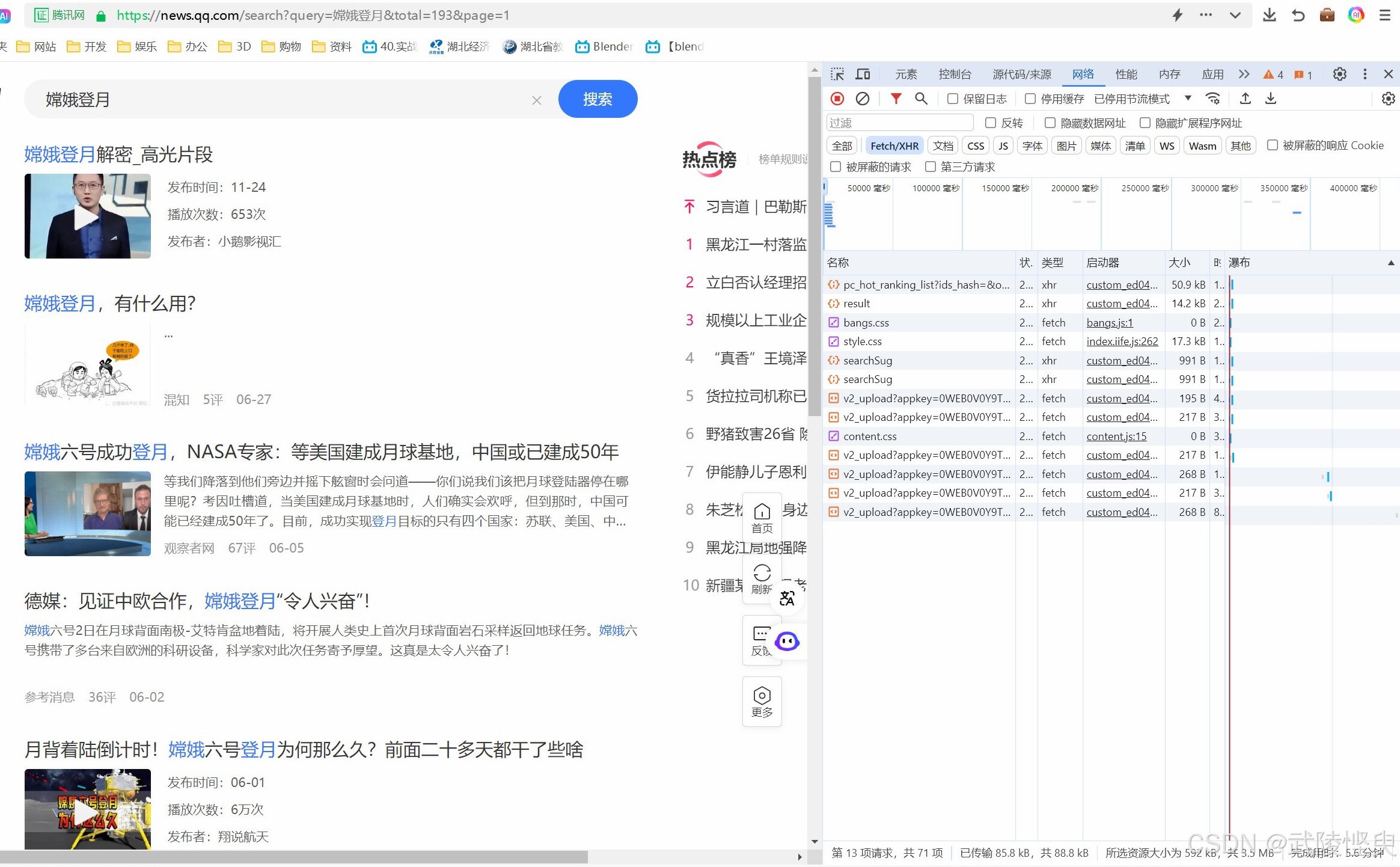
(重新刷新页面,通过“网络”子工具对数据进行分析)
每选中一个文件,在“预览”信息栏中就可以看到这个文件的内容。“Fetch”类的文件的内容都是自动展开的,“XHR”类型文件的内容并不会自动展开,需要点击黑色的三角形进行展开。在检查result文件时,在“secList”对象下面发现了与网页显示内容一致的数据。
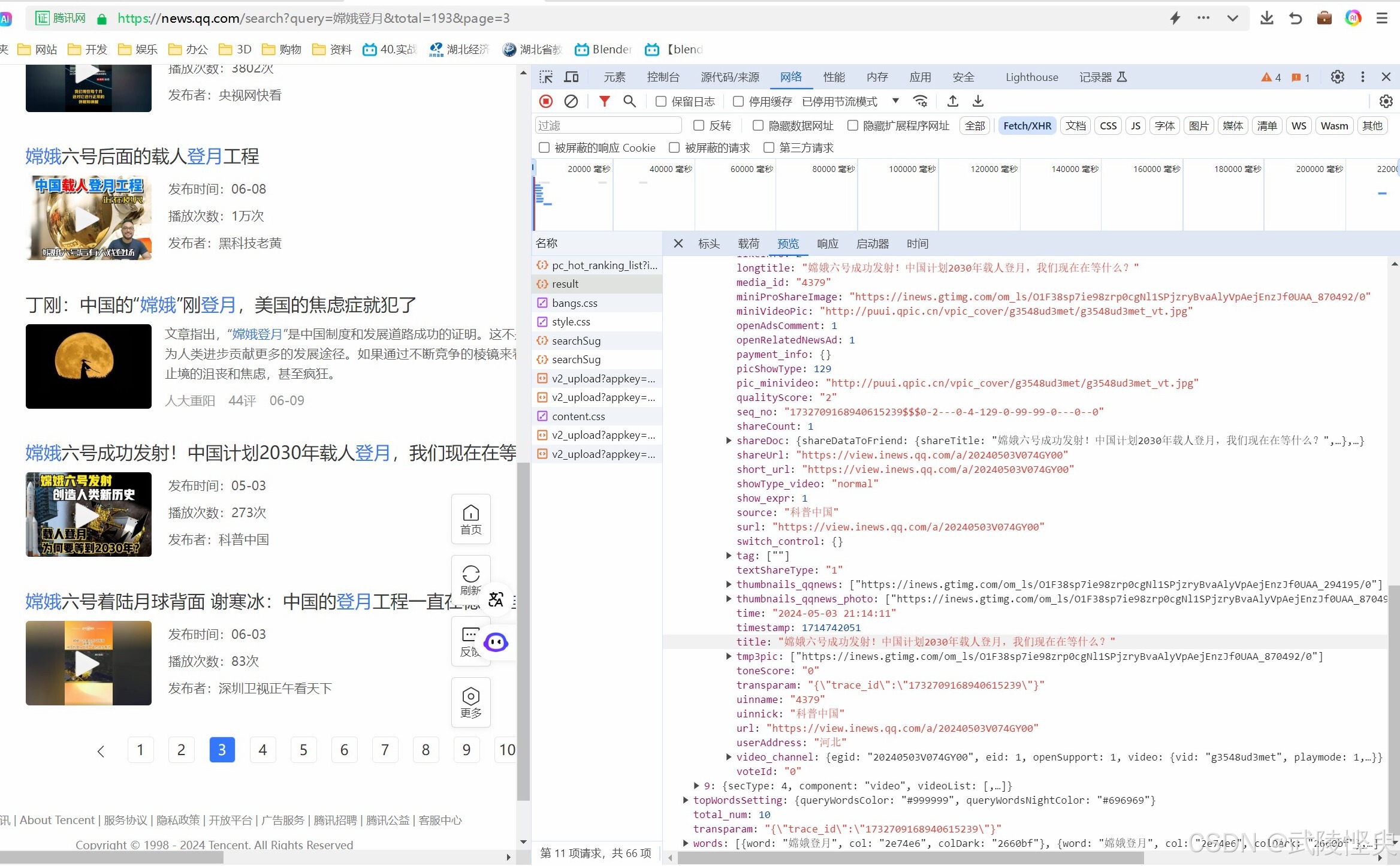
(利用“预览”模式对下载到的文件逐一查看,发现搜索结果在result中)
保持result选中状态,切换到“网络”子工具的“标头”信息栏,可以看到请求方法是POST,还要获取result的网址,这里也能查看请求标头的信息。在请求标头信息里,可以查看'Accept'、'Content-Type'、'Referer'、'User-Agent'等常用的请求头参数信息。这些参数在后续的抓取操作中会有用。
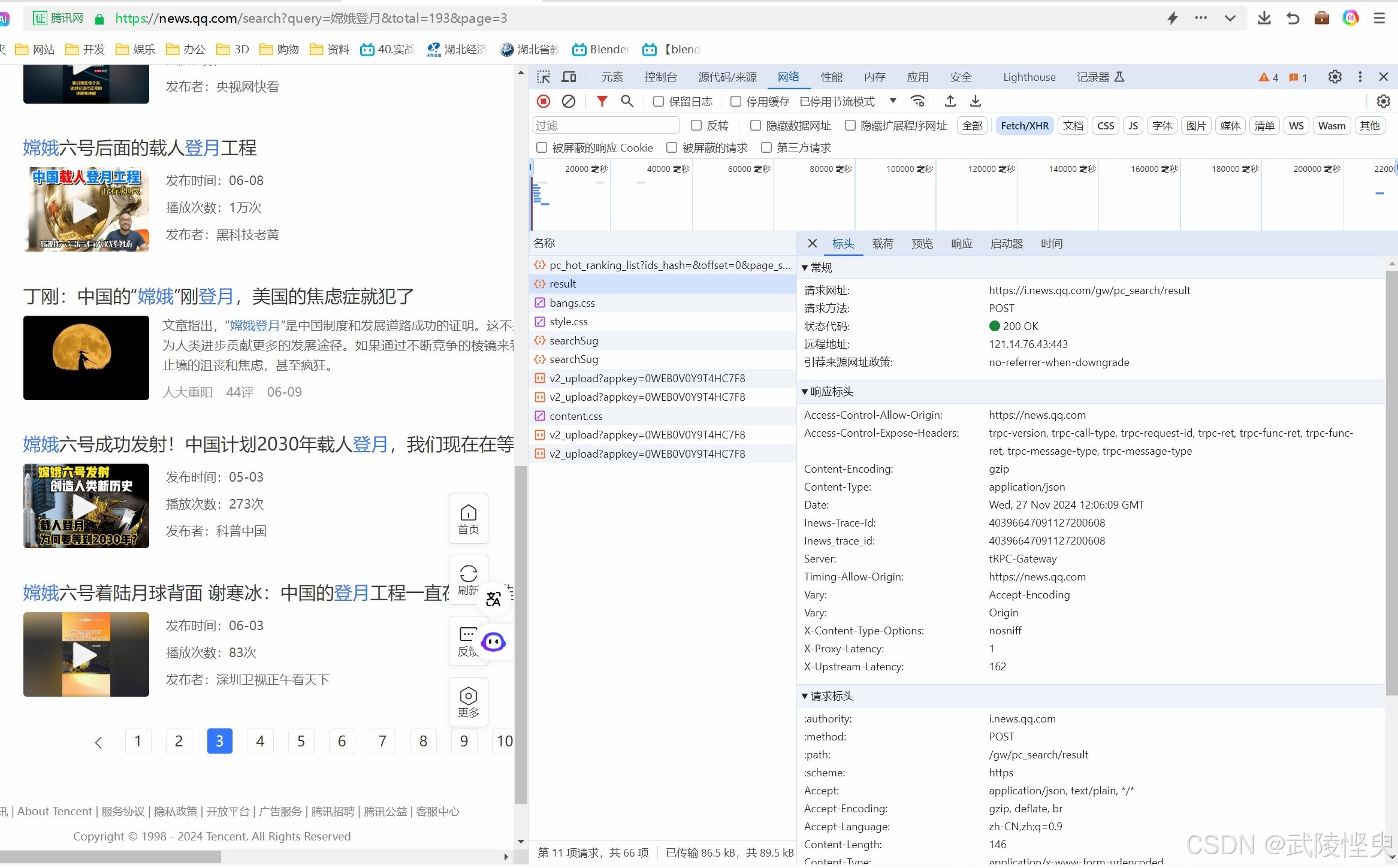
(“标头”信息栏查看请求标头信息)
点开“载荷”信息栏则可以几个参数,当看到其中的page和query时,我感觉自己找到了关键了。这几个参数在后面的POST方法中会用到。
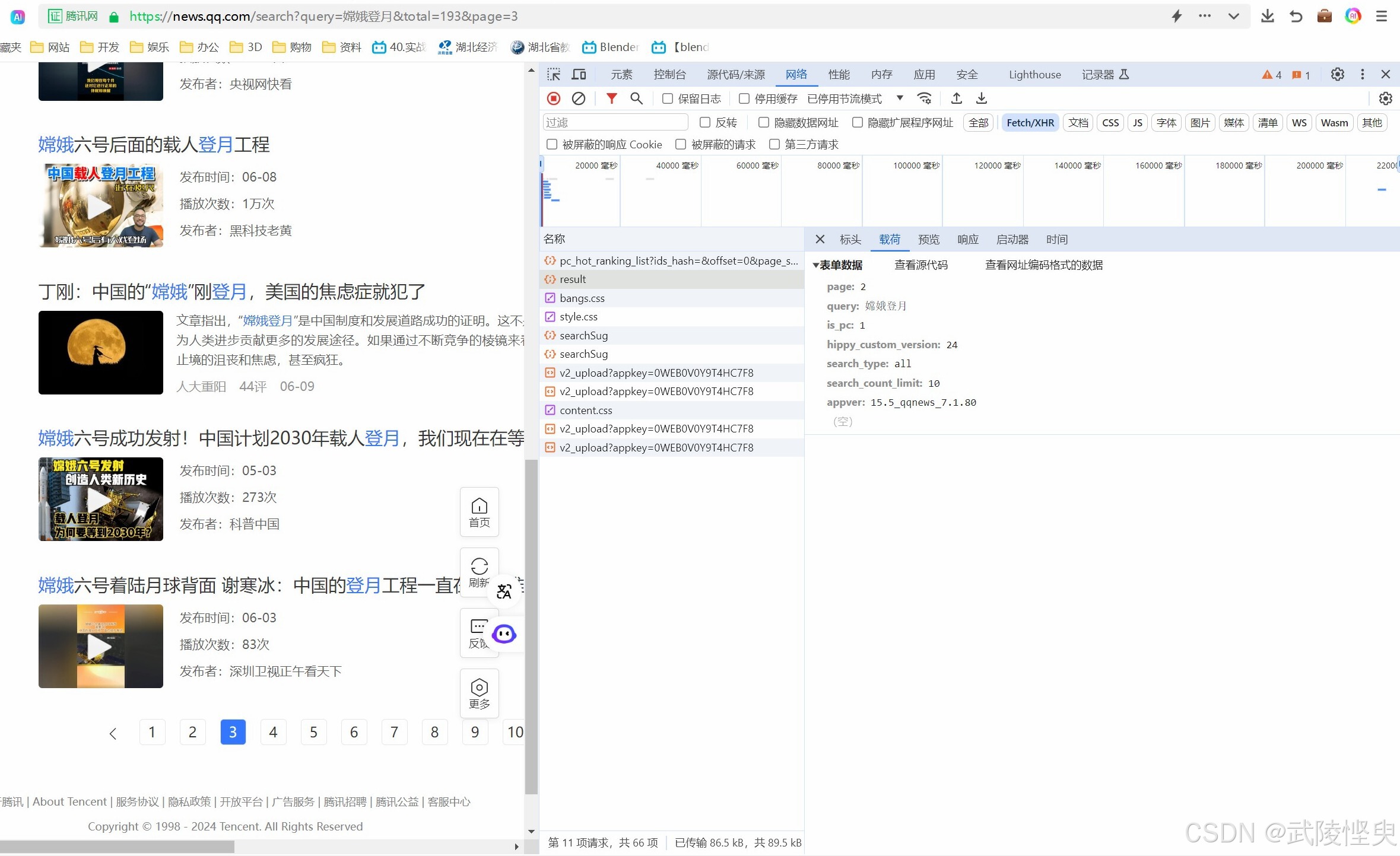
(“载荷”信息栏,存放了关键的信息)
2.3 请求数据
前面的步骤确认的搜索数据就在result,通过“标头”信息栏确认了该文件的请求方式是POST,请求网址是 'https://i.news.qq.com/gw/pc_search/result' ,还要发起POST请求需要的几个参数(“载荷”中),下面就是实现请求了。
我在前面的爬虫学习中都是用的get请求,这是第一次遇到需用post请求的场景。对post请求不熟悉的我,连忙补习了一下这方面的知识。
根据学到的知识,我使用的发送POST的代码形式是:
response = requests.post(url, data=data, headers=headers)url中是请求地址,这里不能用网页上显示的地址,而是在上面“标头”信息栏中查到的请求网址。
data中保存的是字典形式的请求参数,这些参数在“载荷”信息栏中可以查到。
headers中保存的请求头信息,如果不添加这个参数,容易被网站的反爬中机制给限制,我在测试的过程中,一开始没添加请求头信息参数,结果爬取几次后就被网站给限制了,导致无法正常请求到数据。
最终的POS请求代码如下:
import requests
query = '嫦娥登月' # 设置关键字
page = 1 # 1-第1页,2-第2页,3-第3页,依此类推(post中减1)
count_limit = 10 # 控制每次获取到的结果数量,默认为10,调大此值,一次请求可获取更多的数据
post_page = page - 1 # 在发送post请求时,页号要减1
# 在“载荷”中查到的几个参数,其中一部分的值设置成了变量
data = {
'page': str(post_page),
'query': query,
'is_pc': '1',
'hippy_custom_version': '24',
'search_type': 'all',
'search_count_limit': str(count_limit), # 控制每次获取到的结果数量,默认为10
'appver': '15.5_qqnews_7.1.80'
}
url = f'https://i.news.qq.com/gw/pc_search/result'
# 请求头
headers = {
'Accept': 'application/json, text/plain, */*',
'Content-Type': 'application/x-www-form-urlencoded',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/86.0.4240.198 Safari/537.36 QIHU 360ENT',
}
# 发送post请求
response = requests.post(url, data=data, headers=headers) # 返回的是json格式的数据
response.encoding = 'utf-8'2.4 分析数据
通过上面的代码我们就可以从腾*网站获取到指定关键字的搜索结果了,获取到的结果是json格式的,其数据主要是字典和列表,使用python的基本语法就可以提取数据,无需使用第三方的库。
我通过“预览”信息栏对result的数据进行研究,确定了关键的对象,对照着编辑提取数据的代码即可。
# 将数据转换为json格式
json_data = response.json()
print('状态码为:', response.status_code) # 查看一下状态码
datas = [] # 存放返回结果
order = 0 # 序号
# 从json数据中提取搜索结果
# print(json_data['secList']) # 搜索结果都在'secList'中,它是列表,其中的元素是字典格式的
for data in json_data['secList']:
order += 1
# component的常见值:lingxi_baike-百科;pictext-图片文字;video-视频;top_show-顶层展示
component = data['component']
# secType的值: 0-图文信息;4-视频,相关资料在'secInfo'中
sec_type = data['secType']
if sec_type == 0:
# 图文信息类的搜索的结果在'newList'中
info_list = data['newsList'][0]
elif sec_type == 4:
# 视频类的搜索的结果则在'videoList'中
info_list = data['videoList'][0]
else:
print(order, '. ', '分析失败,跳过')
continue # 找不到数据的调过
title = info_list['title'] # 获取标题
link = info_list['surl'] # 获取链接
if sec_type == 4:
content = '' # 视频类的页面没有显示摘要,这里也就不获取了。
else:
content = ''
# 测试中出现过获取'abstract'值失败的情况, 因此这里使用了try语句
try:
content = info_list['abstract']
except Exception as e:
print(order, ' 获取内容失败')
source = info_list['source'] # 获取来源
time = info_list['time'] # 获取发布时间
data_list.append([order, component, title, link, content, source, time])
# 在屏幕上输出
print(str(order) + ". " + title)
print(link)
print(content)
print(source, ' ', time)
print("数据类型:", component)
print(" ")2.5 最后的效果
有了这些基础代码,后续的爬取代码就可以基于此开发了,我最终的代码做成了,可指定关键字,要爬取的页数,每页的结果数量。根据输入的参数,进行循环爬取。最后效果如下:
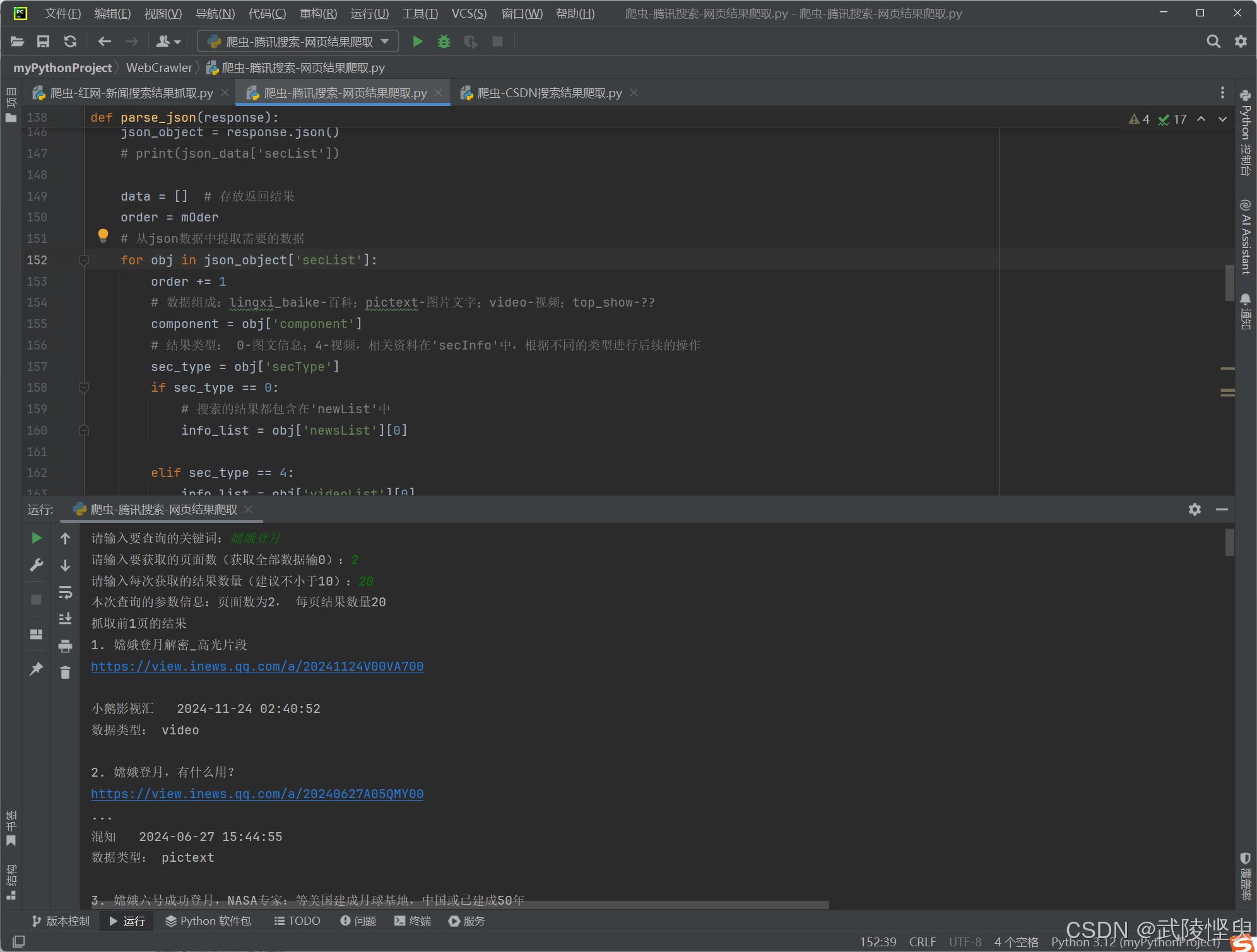
(爬取前可以设置关键字、爬取页数,每页结果数三个参数)
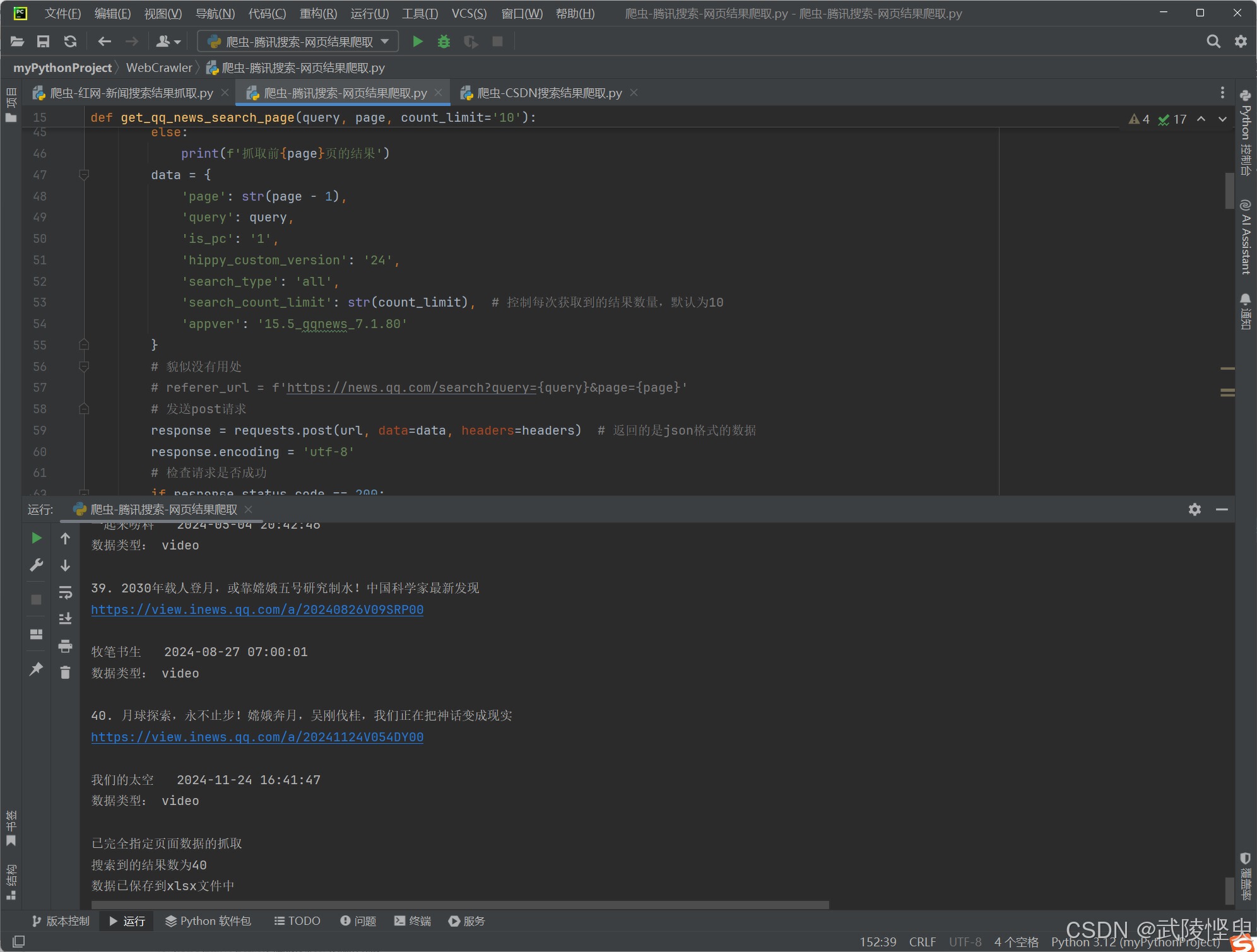
(爬取结果会在实时显示)
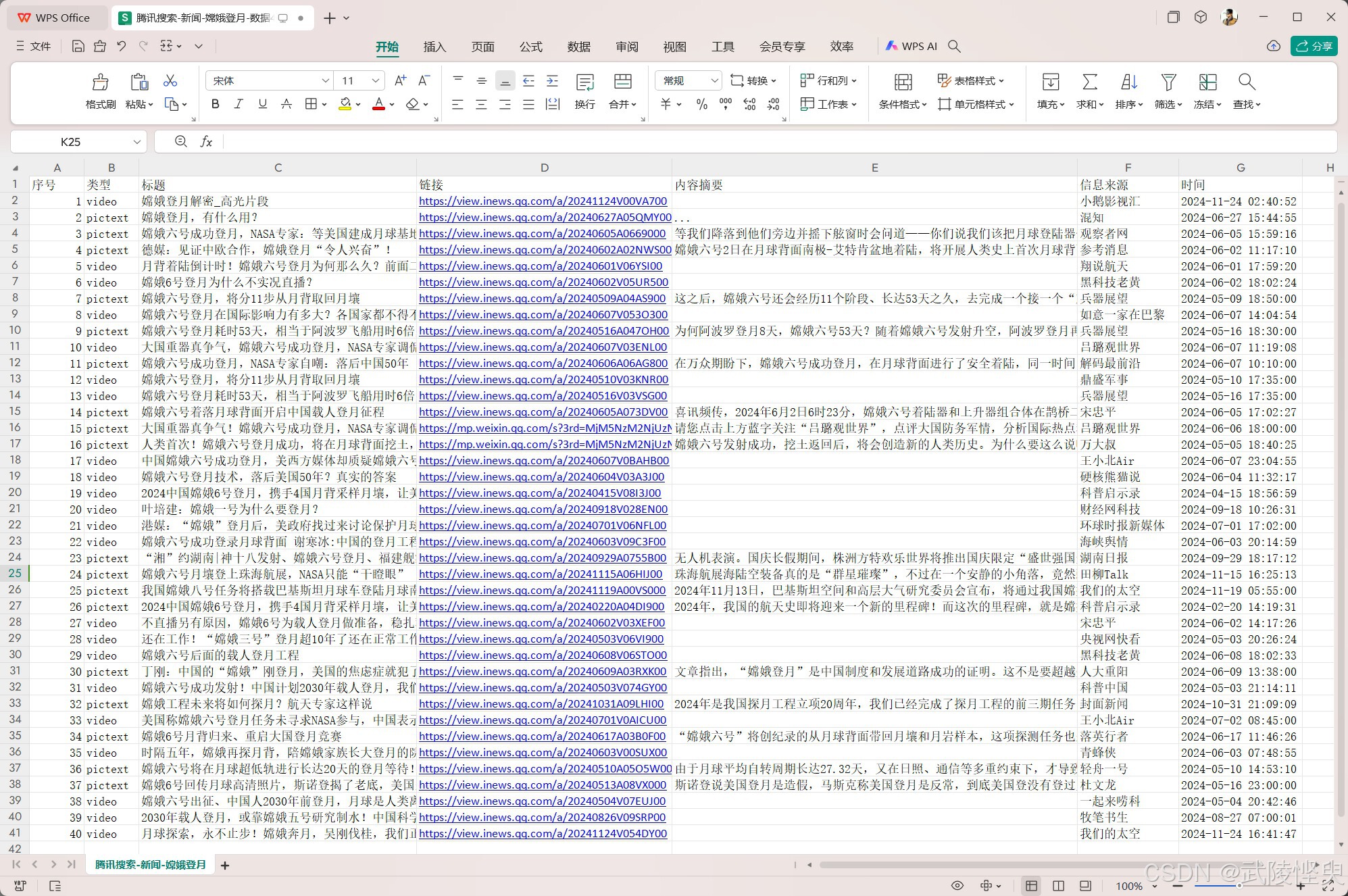
(爬取完成后,自动保存到xlsx文件中)
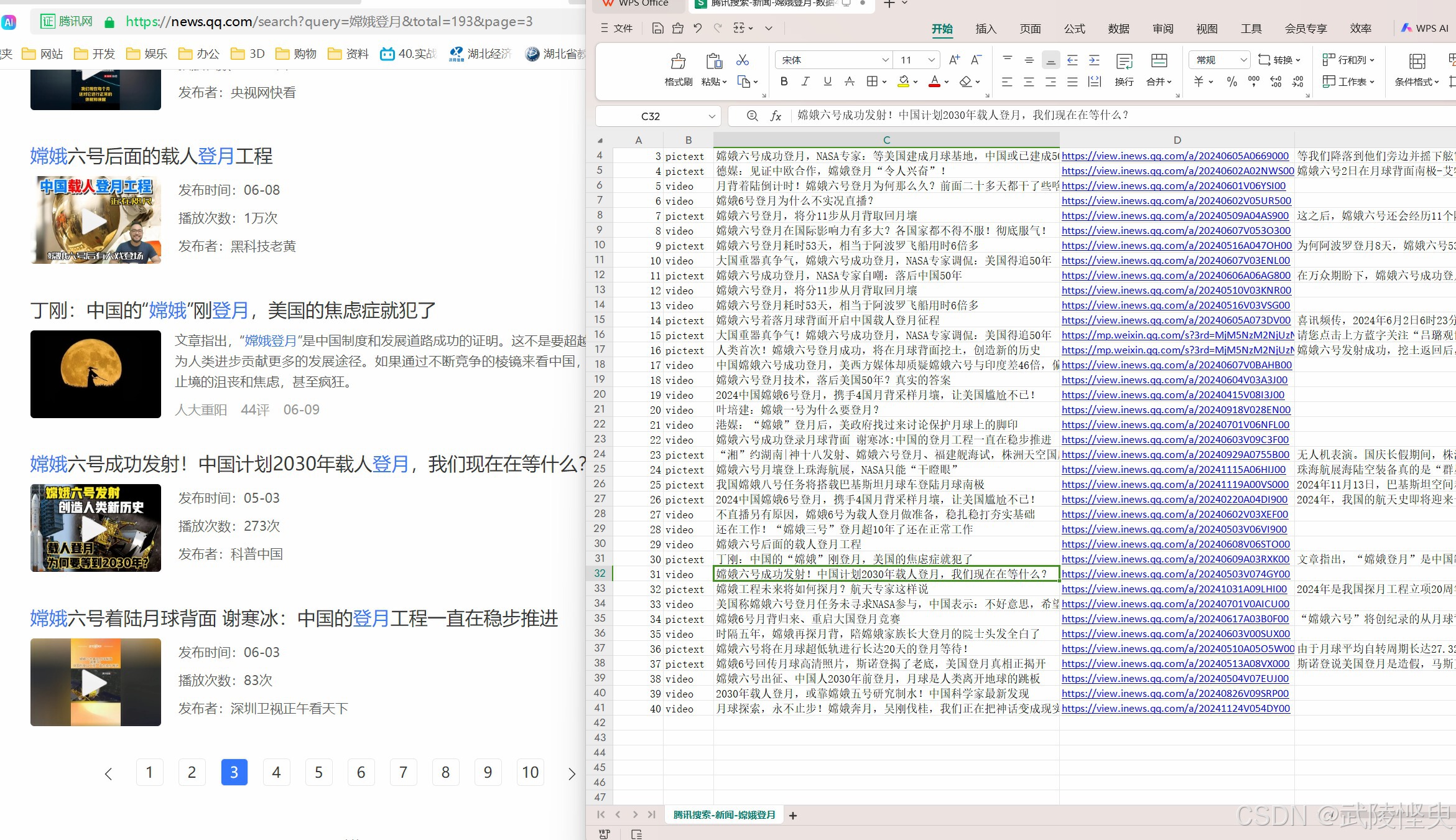
(对比一下爬取的结果与网页显示的结果,大部分数据一样,部分数据不同)
三、代码展示
最后上基础的爬取代码,更复杂的功能都是基于这段基础的代码,进一步的开发的。
import requests
query = '嫦娥登月' # 设置关键字
page = 1 # 1-第1页,2-第2页,3-第3页,依此类推(post中减1)
count_limit = 10 # 控制每次获取到的结果数量,默认为10,调大此值,一次请求可获取更多的数据
post_page = page - 1 # 在发送post请求时,页号要减1
# 在“载荷”中查到的几个参数,其中一部分的值设置成了变量
data = {
'page': str(post_page),
'query': query,
'is_pc': '1',
'hippy_custom_version': '24',
'search_type': 'all',
'search_count_limit': str(count_limit), # 控制每次获取到的结果数量,默认为10
'appver': '15.5_qqnews_7.1.80'
}
url = f'https://i.news.qq.com/gw/pc_search/result'
# 请求头
headers = {
'Accept': 'application/json, text/plain, */*',
'Content-Type': 'application/x-www-form-urlencoded',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/86.0.4240.198 Safari/537.36 QIHU 360ENT',
}
# 发送post请求
response = requests.post(url, data=data, headers=headers) # 返回的是json格式的数据
response.encoding = 'utf-8'
# 将数据转换为json格式
json_data = response.json()
print('状态码为:', response.status_code) # 查看一下状态码
datas = [] # 存放返回结果
order = 0 # 序号
# 从json数据中提取搜索结果
# print(json_data['secList']) # 搜索结果都在'secList'中,它是列表,其中的元素是字典格式的
for data in json_data['secList']:
order += 1
# component的常见值:lingxi_baike-百科;pictext-图片文字;video-视频;top_show-顶层展示
component = data['component']
# secType的值: 0-图文信息;4-视频,相关资料在'secInfo'中
sec_type = data['secType']
if sec_type == 0:
# 图文信息类的搜索的结果在'newList'中
info_list = data['newsList'][0]
elif sec_type == 4:
# 视频类的搜索的结果则在'videoList'中
info_list = data['videoList'][0]
else:
print(order, '. ', '分析失败,跳过')
continue # 找不到数据的调过
title = info_list['title'] # 获取标题
link = info_list['surl'] # 获取链接
if sec_type == 4:
content = '' # 视频类的页面没有显示摘要,这里也就不获取了。
else:
content = ''
# 测试中出现过获取'abstract'值失败的情况, 因此这里使用了try语句
try:
content = info_list['abstract']
except Exception as e:
print(order, ' 获取内容失败')
source = info_list['source'] # 获取来源
time = info_list['time'] # 获取发布时间
data_list.append([order, component, title, link, content, source, time])
# 在屏幕上输出
print(str(order) + ". " + title)
print(link)
print(content)
print(source, ' ', time)
print("数据类型:", component)
print(" ")

















 3828
3828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











