







Three level
virtualization
concurrency
persistence
Why need OS virtualize resources?
This is not the main question, as the answer should be obvious: it makes the system easier to use.
How to virtualize resources?
This is the crux of problem. Thus, focus on how:
What mechanisms and policies are implemented by the OS to attain virtualization?
How does the OS do so efficiently?
What hardware support is needed?
What does a running program do?
It executes instructions.
Many millions (and these days, even billions) of times every second, the processor fetches an instruction from memory, decodes it (i.e., figures out which instruction this is), and executes it (i.e., it does the thing that it is supposed to do, like add two numbers together, access memory, check a condition, jump to a function, and so forth). After it is done with this instruction, the processor moves on to the next instruction, and so on, and so on, until the program finally completes.
Von Neumann model of computing.
OS does?
it takes physical resources, such as a CPU, memory, or disk, and virtualizes them. It handles tough and tricky issues related to concurrency. And it stores files persistently, thus making them safe over the long-term.
What is Process?
one of the most fundamental abstractions that the OS provides to users: the process. The definition of a process, informally, is quite simple: it is a running program.
The OS creates this illusion by virtualizing the CPU. By running one process, then stopping it and running another, and so forth, the OS can promote the illusion that many virtual CPUs exist when in fact there is only one physical CPU (or a few). This basic technique, known as time sharing of the CPU, allows users to run as many concurrent processes as they would like; the potential cost is performance, as each will run more slowly if the CPU(s) must be shared.
To implement virtualization of the CPU, and to implement it well, the OS will need both some low-level machinery(mechanisms) as well as some high level intelligence(policies).
Mechanisms
We call the low-level machinery mechanisms; mechanisms are low-level methods or protocols that implement a needed piece of functionality. For example, we’ll learn later how to implement a context switch, which gives the OS the ability to stop running one program and start running another on a given CPU; this time-sharing mechanism is employed by all modern OSes.
Policies
On top of these mechanisms resides some of the intelligence in the OS, in the form of policies. Policies are algorithms for making some kind of decision within the OS. For example, given a number of possible programs to run on a CPU, which program should the OS run? A scheduling policy in the OS will make this decision, likely using historical information (e.g., which program has run more over the last minute?), workload knowledge (e.g., what types of programs are run), and performance metrics (e.g., is the system optimizing for interactive performance, or throughput?) to make its decision.
Process API
Create
Destroy
Wait
Status
Process States
Running
Ready
Blocked
Done
Mechanism: Limited Direct Execution
Direct Execution Protocol (Without Limits)
Limited Direct Execution Protocol
Limited Direct Execution Protocol (Timer Interrupt)
Scheduling
assumptions
Make the following assumptions about the processes, sometimes called jobs, that are running in the system:
Each job runs for the same amount of time.
All jobs arrive at the same time.
Once started, each job runs to completion.
All jobs only use the CPU (i.e., they perform no I/O)
The run-time of each job is known.
Scheduling Metrics
Turnaround time
T(turnaround) = T(completion) − T(arrival)
Because we have assumed that all jobs arrive at the same time, for now T(arrival) = 0 and hence T(turnaround) = T(completion). This fact will change as we relax the aforementioned assumptions.
Response time
T(response) = T(first_run) − T(arrival)
Evolution
only Turnaround time
FIFO –(relax 1)–> SJF –(relax 2)–(relax 3)–> STCF
First in First out(FIFO)
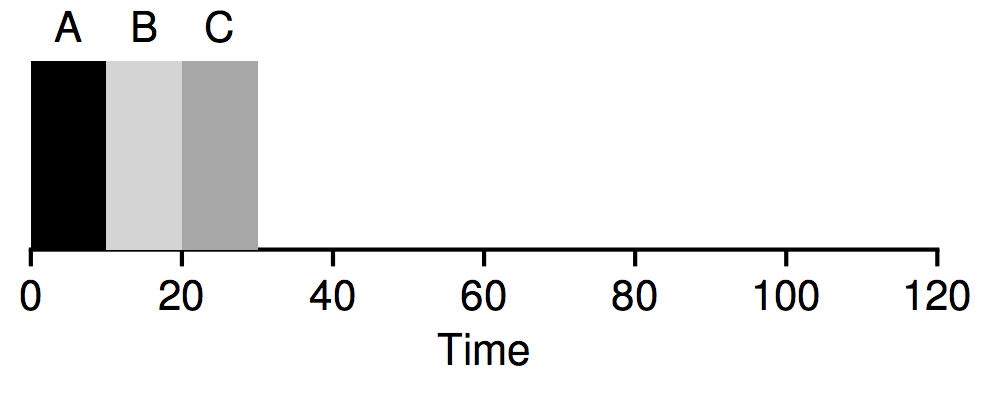
A finished at 10, B at 20, and C at 30. Thus, the average turnaround time for the three jobs is simply (10+20+30)/3 = 20.
Why FIFO Is Not That Great?
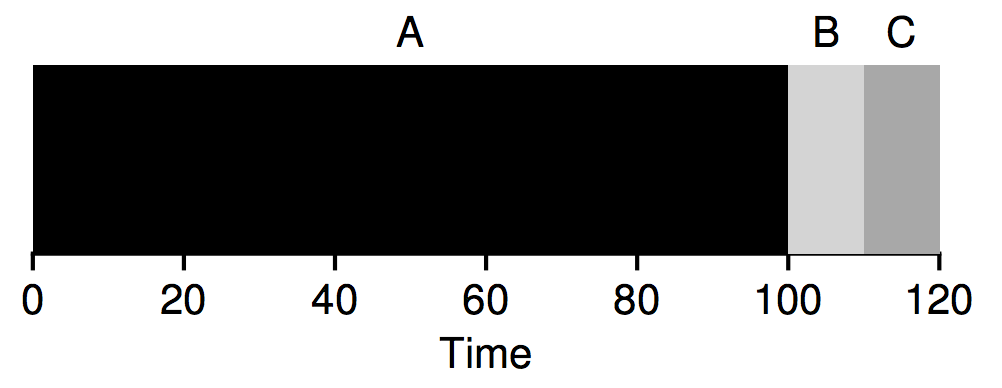
a painful 110 seconds: (100+110+120)/3 = 110.
Shortest Job First(SJF)
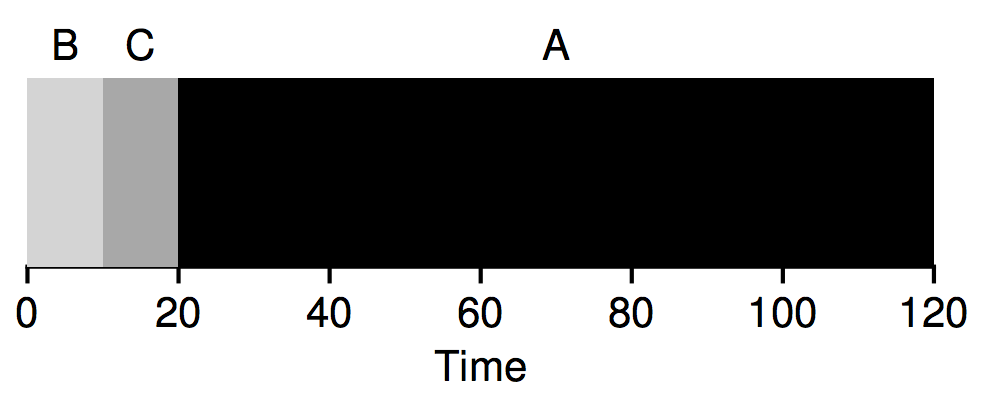
turnaround from 110 seconds to 50: (10+20+120)/3 = 50.
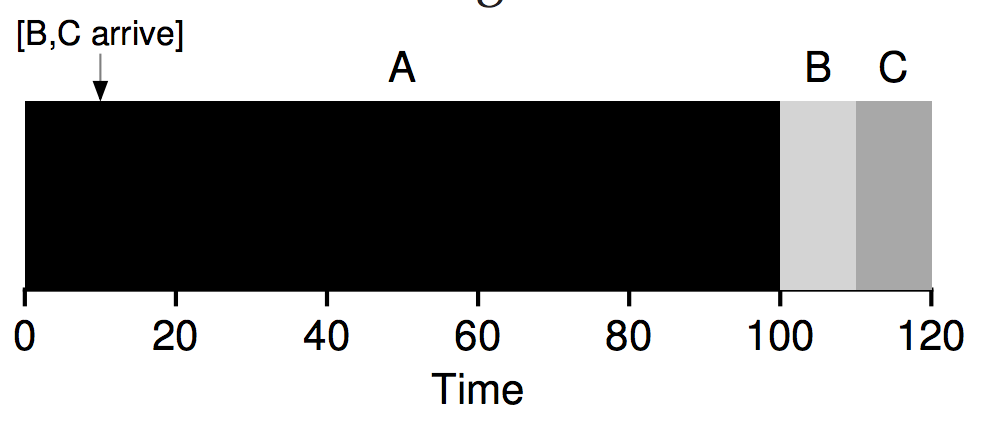
Average turnaround time for these three jobs is 103.33 seconds: (100+(110−10)+(120−10))/3 = 103.33.
Shortest Time-to-Completion First (STCF)

The result is a much-improved average turnaround time: 50 seconds: ((120−0)+(20−10)+(30−10)) / 3 = 50.
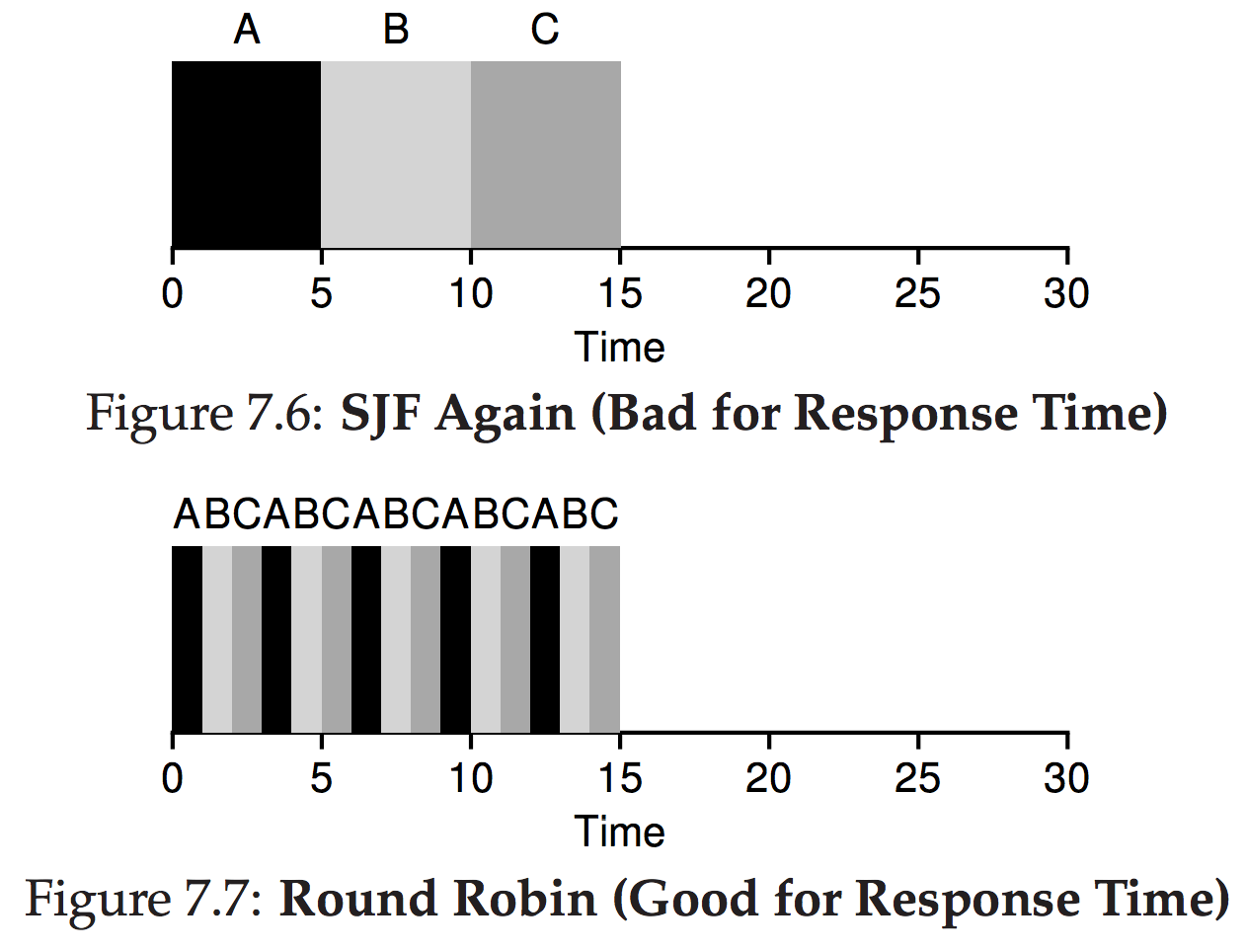
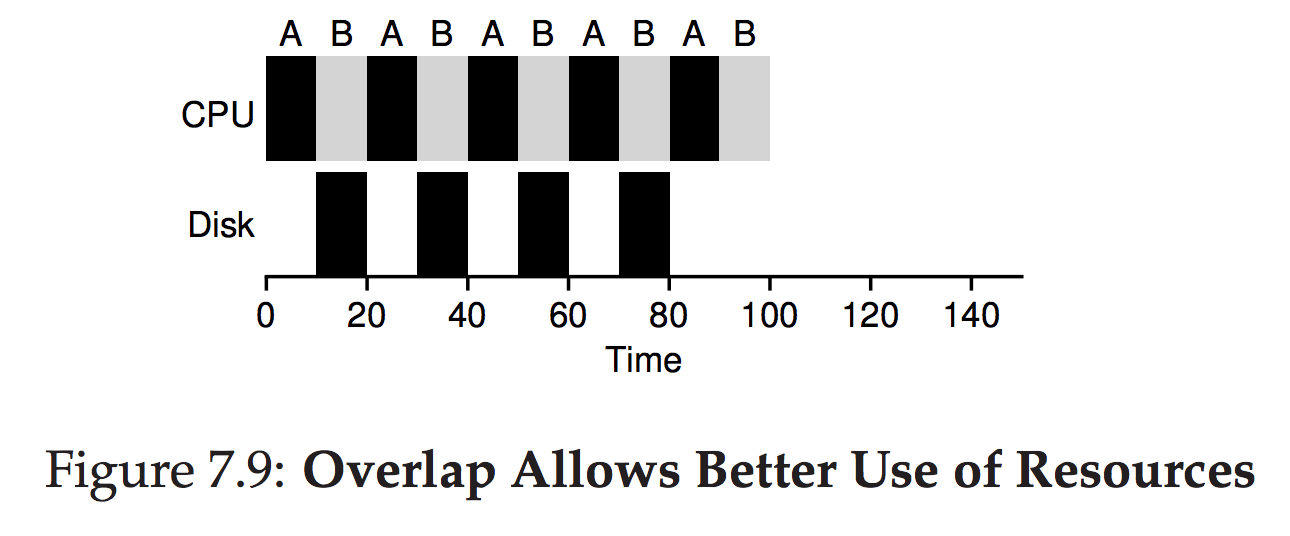
- add Response time















 2251
2251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









