







目录
1、过拟合欠拟合判断
1、过拟合:指算法模型在训练集上的性能非常好,但是泛化能力很差,泛化误差很大,即在测试集上的效果却很糟糕的情况。
- 过拟合的原因:将训练样本本身的一些特点当作了所有潜在样本都具有的一般性质,这会造成泛化能力下降;另一个原因是模型可能学到训练集中的噪声,并基于噪声进行了预测;
- 过拟合无法避免,只能缓解。因为机器学习的问题通常是 NP 难甚至更难的,而有效的学习算法必然是在多项式时间内运行完成。如果可以避免过拟合,这就意味着构造性的证明了
P=NP。2、欠拟合:模型的性能非常差,在训练数据和测试数据上的性能都不好,训练误差和泛化误差都很大。
3、过拟合和欠拟合判断:
- 通过交叉验证:在训练集上的acc比较高,测试集上比较低表明过拟合了
- 通过训练过程的loss判断:1、train loss 不断下降,test loss不断下降,说明网络仍在学习;2、train loss 趋于不变,test loss不断下降,说明数据集100%有问题;3、train loss 趋于不变,test loss趋于不变,说明学习遇到瓶颈,需要减小学习率或批量数目;4、train loss 不断上升,test loss不断上升,说明网络结构设计不当,训练超参数设置不当,数据集经过清洗等问题。
2、泛化能力
指模型对未知的、新鲜的数据的预测能力,通常是根据测试误差来衡量模型的泛化能力,测试误差越小,模型能力越强;
常用的对模型泛化能力的评估方法有以下几种,主要区别就是如何划分测试集。
- 留出法(Holdout):留出法是最简单也是最直接的验证方法,它就是将数据集随机划分为两个互斥的集合,即训练集和测试集,比如按照 7:3 的比例划分,70% 的数据作为训练集,30% 的数据作为测试集。也可以划分为三个互斥的集合,此时就增加一个验证集,用于调试参数和选择模型。
- k-fold 交叉验证(Cross Validation):a、将原始数据集划分为
k个大小相等且互斥的子集;b、选择k-1个子集作为训练集,剩余作为验证集进行模型的训练和评估,重复k次(每次采用不同子集作为验证集);c、将k次实验评估指标的平均值作为最终的评估结果。- 留一法(Leave One Out, LOO):留一法是
k-fold交叉验证的一个特例情况,即让k=N, 其中N是原始数据集的样本数量,这样每个子集就只有一个样本,这就是留一法。留一法的优点就是训练数据更接近原始数据集了,仅仅相差一个样本而已,通过这种方法训练的模型,几乎可以认为就是在原始数据集上训练得到的模型 。但缺点也比较明显,计算速度会大大降低,特别是原始数据集非常大的时候,训练N个模型的计算量和计算时间都很大,因此一般实际应用中很少采用这种方法。- 自助法(bootstrapping)
3、模型评估
3.1、分类模型
混淆矩阵
混淆矩阵就是分别统计分类模型归错类,归对类的观测值个数,然后把结果放在一个表里展示出来。这个表就是混淆矩阵。
真正(True Positive , TP):被模型预测为正的正样本。 假正(False Positive , FP):被模型预测为正的负样本。 假负(False Negative , FN):被模型预测为负的正样本。 真负(True Negative , TN):被模型预测为负的负样本。 真正率(True Positive Rate):TPR=TP/(TP+FN),被预测为正的正样本数/正样本实际数。 假正率(False Positive Rate):FPR=FP/(FP+TN),被预测为正的负样本数/负样本实际数。 假负率(False Negative Rate):FNR=FN/(TP+FN),被预测为负的正样本数/正样本实际数。 真负率(True Negative Rate):TNR=TN/(TN+FP),被预测为负的负样本数/负样本实际数。
- 查准率(精准率):Precision = TP / (TP+FP);
- 查全率(召回率):Recall = TP / (TP+FN);
- 正确率(准确率):Accuracy = (TP+TN) / (TP+FP+TN+FN)
- F值(F1-scores):Precision和Recall加权调和平均数,并假设两者一样重要。
F1-score = (2Recall*Precision) / (Recall + Precision)
ROC是一条线,如果我们选择用ROC曲线评判模型的准确性,那么越靠近左上角的ROC曲线,模型的准确度越高,模型越理想;
逻辑回归里面,对于正负例的界定,通常会设一个阈值,大于阈值的为正类,小于阈值为负类。如果我们减小这个阀值,更多的样本会被识别为正类,提高正类的识别率,但同时也会使得更多的负类被错误识别为正类。为了直观表示这一现象,引入ROC。根据分类结果计算得到ROC空间中相应的点,连接这些点就形成ROC curve,横坐标为False Positive Rate(FPR假正率),纵坐标为True Positive Rate(TPR真正率)。一般情况下,这个曲线都应该处于(0,0)和(1,1)连线的上方,如图:
AUC是线下面积,如果我们选择用AUC面积评判模型的准确性,那么模型的AUC面积值越大,模型的准确度越高,模型越理想;
AUC值是一个概率值,当你随机挑选一个正样本以及负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值,AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类。例如一个模型的AUC是0.7,其含义可以理解为:给定一个正样本和一个负样本,在70%的情况下,模型对正样本的打分(概率)高于对负样本的打分。


3.2、回归模型
回归模型评估有三种方法,分别是:平均绝对值误差、均方误差和R平方值。
平均绝对误差 Mean Absolute Error(MAE)
MAE用来描述预测值和真实值的差值。数值越小越好。假设是真实值,是相对应的预测值,则n个样本的MAE可由下式出给:
MAE优缺点:虽然平均绝对误差能够获得一个评价值,但是你并不知道这个值代表模型拟合是优还是劣,只有通过对比才能达到效果。
均方误差 Mean Squared Error(MSE)
Mean Squared Error也称为Mean Squared Deviation(MSD),计算的是预测值和实际值的平方误差。同样,数值越小越好。假设是真实值,是相对应的预测值,则n 个样本的MSE由下式公式给出:
由于MSE与我们的目标变量的量纲不一致,为了保证量纲一致性,我们需要对MSE进行开方,即均方根误差(RMSE)
均方根误差 Root Mean Squared Error(RMSE)
均方根误差RMSE(root-mean-square error), 均方根误差亦称标准误差,它是观测值与真值偏差的平方与观测次数比值的平方根。均方根误差是用来衡量观测值同真值之间的偏差。标准误差对一组测量中的特大或特小误差反映非常敏感,所以,标准误差能够很好地反映出测量的精密度。可用标准误差作为评定这一测量过程精度的标准。计算公式如下:
这不就是MSE开个根号么。有意义么?其实实质是一样的。只不过用于数据更好的描述。
RMSE与MAE对比:RMSE相当于L2范数,MAE相当于L1范数。次数越高,计算结果就越与较大的值有关,而忽略较小的值,所以这就是为什么RMSE针对异常值更敏感的原因(即有一个预测值与真实值相差很大,那么RMSE就会很大)。
R-平方
该指标判断的是预测模型和真实数据的拟合程度,最佳值为1,同时可为负值。
其中是y 的均值,即
如果结果是0,就说明我们的模型跟瞎猜差不多。如果结果是1。就说明我们模型无错误。如果结果是0-1之间的数,就是我们模型的好坏程度。如果结果是负数。说明我们的模型还不如瞎猜。
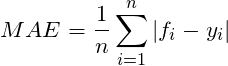
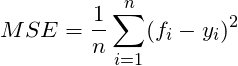
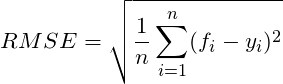
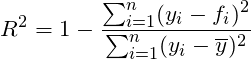
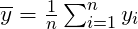
4、NDCG
NDCG(Normalized Discounted Cumulative Gain)
NDCG,Normalized Discounted cumulative gain 直接翻译为归一化折损累计增益。这个指标通常是用来衡量和评价搜索结果算法。DCG的两个思想:
- 高关联度的结果比一般关联度的结果更影响最终的指标得分
有高关联度的结果出现在更靠前的位置的时候,指标会越高
- 累计增益(CG):CG,cumulative gain,是DCG的前身,只考虑到了相关性的关联程度,没有考虑到位置的因素。它是一个搜素结果相关性分数的总和。reli 代表i这个位置上的相关度。
- 折损累计增益(DCG):DCG, Discounted 的CG,就是在每一个CG的结果上处以一个折损值,为什么要这么做呢?目的就是为了让排名越靠前的结果越能影响最后的结果。假设排序越往后,价值越低。
当然还有一种比较常用的公式,用来增加相关度影响比重的DCG计算方式是:
- 归一化折损累计增益(NDCG):NDCG, Normalized 的DCG,由于搜索结果随着检索词的不同,返回的数量是不一致的,而DCG是一个累加的值,没法针对两个不同的搜索结果进行比较,因此需要归一化处理,这里是除以IDCG
IDCG为理想情况下最大的DCG值。
其中 |REL| 表示,结果按照相关性从大到小的顺序排序,取前p个结果组成的集合。也就是按照最优的方式对结果进行排序。
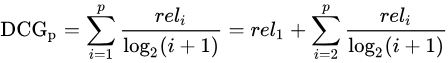
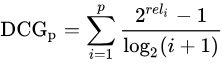
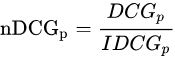
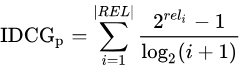















 3314
3314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









