






github:swiftnet
一 、Swiftnet
(1)采用encoder-decoder的网络架构,选择resnet18和mobilenetv2作为其主干网;
(2)提出了一种扩大感受野的方法: fuse shared features at multiple resolutions in a novel fashion;
(3)给出了一些语义分割的小trick
二 、Basic building blocks
2.1 、Recognition encoder
swiftnet选择resnet18和mobilenetv2作为主干网。
resnet18的计算量是mobilenetv2的6倍。
但mobilenetv2中使用了深度可分离卷积,GPU firmware (the cuDNN library)并没有直接支持此类卷积,故很多实践中,mobilenetv2反而比resnet18速度慢。
DenseNet中同样存在此问题,因为其需要efficient convolution over a non-contiguous tensor,cuDNN并不支持此操作。
2.2、Upsampling decoder
为了保持实时的处理速度,上采样流程需尽可能简单。
首先低分辨率特征图使用双线性插值上采样,然后与来自lateral connection分支的lateral features相加。最后再输入到一个3x3 conv中。
需注意两点:
(1)lateral connection分支应该接在sum后,若接在relu后会降低准确率;
(2)若使用深度可分离卷积或1x1 conv替代最后的3x3 conv,准确率会下降。

所有蓝色UP(decoder单元)的channel数均为128,故lateral features需用1x1的卷积使特征图的channel一致。

2.3、Module for increasing the receptive field
使用spatial pyramid pooling和pyramid fusion方法扩大感受野的同时保证实时。
两个encoder共享权重

三、Experiment

3.1、Validation of the upsampling capacity

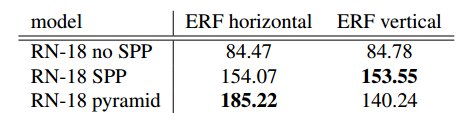
3.2、Size of the receptive field














 1980
1980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









