







序言
记录机器学习基本概念,不做详细解释,常识积累。长期更新…
# 监督学习
- 监督学习:数据有label,主要是分类和回归两种方法
- 监督学习的任务是学习一个模型,对输入做一个好的预测
# 无监督学习
- 无监督学习:数据无label,主要是降维和聚类
- 无监督学习对数据直接进行建模,事先不知道输入数据的输出结果是什么
# 迁移学习
- 将某个领域或任务上学到的知识或模式应用到不同但相关领域的问题中
- 问题来源:监督学习要求数据同分布且完成数据标注,数据分布的差异和数据标注过期问题(主要是数据分布差异),如何更好的利用之前标注好的数据,保证新任务的模型精度,由此引入迁移学习的研究
# 分类
- 根据样本特征判断其属于有限类别中的哪一个;二分类问题,多分类问题
# 回归
- 根据样本特征预测一个连续值的结果;房价,票房,股票预测等
# 聚类
- 根据样本取出的特征让样本抱团、划分成不同的簇;新闻分类,用户群体划分等
# 过拟合
- overfitting. 对训练集性能很好,对测试集性能很差。即对训练集过拟合,泛化能力差
- 解决方法:正则化;增加训练数据集等
# 欠拟合
- underfitting. 学到的模型过于简单
- 解决方法:引入多项式;使用复杂模型等
# 权重weight
- 表示神经元之间的连接强度,权重的大小表示可能性的大小
# 偏置bias
- 偏置项,二维:直线斜截式方程y=kx++b;三维:一个决策面。偏置的设置是为了正确分类样本
# CNN
- Convolutional Neural Network,卷积神经网络
# DNN
- Deep Neural Network,深度神经网络
- 可以理解为有多个隐藏层的神经网络,至于多少隐藏层没有定论
# RNN
- Recurrent Neural Network,循环神经网络
- 是递归神经网络Recursive Neural Network的特例
- 递归神经网络:包括结构递归神经网络和时间递归神经网络,狭义上讲递归神经网络指结构递归神经网络,时间递归神经网络则称为循环神经网络
# LSTM
- Long-short Term Memory Network,长短时记忆网络
- 循环神经网络RNN演化而来
# GNN
- Graph Neural Network,图像神经网络
# GAN
- Generative Adversarial Network,生成式对抗网络
# SVM
- Support Vector Machine,支持向量机
- 优点:求得的解一定是全局最优而不是局部最优
- 缺点:只适用于二分类问题
# MLP
- Multi-Layer Perceptron,多层感知机
- 最经典的神经网络
- 典型的MLP包含三层:输入层+隐藏层+输出层
- MLP是一种全连接神经网络,上一层的任何一个神经元都与下一层的所有神经元连接。
- MLP最典型的例子就是数字识别

# epoch
- 所有训练样本都已输入到模型中,称为一个epoch
# iteration
- 一批训练样本输入到模型中,称为一个iteration
# batchsize
- batch: 逐个样本训练,误差会很大;所有样本一起训练,训练太慢
- batchsize: 一批训练采用的样本数。批大小,决定一个epoch有多少个iteration
# learning rate
- lr,学习率。最优化理论中步长的概念
# 参数
- parameters
- 模型根据数据自动学出的变量,比如权重weight、偏差bias等
# 超参
- hyperparameters
- 用来确定模型的一些参数。比如batchsize/epoch/lr、迭代次数、层数、每层神经元个数等
- 超参是可调整的参数,用于控制模型优化的过程,不同的超参影响模型训练和收敛速率
- 通常说的模型参数是指模型超参数
# 归一化
- normalization,将数据变换到某个固定范围内,通常是[0, 1],图像可能是[0, 255],其他可能是[-1, 1]
- [0, 1]归一化值 = (属性值 - min) / (max - min)
- [-1, 1]归一化值 = (属性值 - mean) / (max - min)
# 标准化
- 将数值变换为均值为0方差为1的分布,并不一定是标准正太分布,即原始数据可能不是正太分布,因为变换后分布种类没有变
- 标准化值 = (属性值 - μ) / σ
- 归一化和标准化的差异:归一化后数据在一定范围比如[0,1],标准化后数据没有固定范围,只是均值为0标准差为1
# 正则化
- 正则化regularization,指为解决适定性问题(存在唯一解)或过拟合而加入额外信息的过程
- 正则化有 L1正则化 和 L2正则化
- L1和L2正则化可以看作损失函数的惩罚项
- L1正则化:指权值矩阵w中各个元素的绝对值之和,通常表示为||w||1
- L2正则化:指权值矩阵w中各个元素的平方和再求平方根,通常表示为||w||2
- 待细化
# PCA
- PCA = primary component analysis,主成分分析法,数据降维方法
- 如 样本分布在二维,画一条线,取各个点到直线的距离,就能得到一个一维数据
# k-means
- 俗称老大法。无监督学习聚类算法
- k个分组->k个初始老大(质心)->计算集合中每个小弟到老大的距离(离哪个老大近就跟哪个老大)->每个老大聚集的一票小弟再选新老大->新老大和老老大距离小于一定阈值终止迭代
# Keras
- Keras就是一个包含各种各样深度学习模型并且方便调用的模型库
- 高级操作:通过接口构造想要的模型,不需要关心内部实现
- 低级操作:乘积、卷积等,使用后端引擎来实现:tensorFlow/Theano/CNTK
- 其他: 纯python编写 + 支持GPU和CPU + 使用Python2.7及以上版本
# pooling
- 池化就是仿照人的视觉系统进行采样,用更高层抽象来表示图像特征
- 池化可以减小空间大小,减少网络参数,防止过拟合
- 最常见的池化操作包括:最大池化 和 平均池化
- 最大池化:
前向传播:选图像区域的最大值作为该区域池化后的值
反向传播:梯度通过最大值的位置传播,其它位置梯度为0 - 平均池化:
前向传播:计算图像区域的平均值作为该区域池化后的值
后向传播:梯度取均值后分给每个位置
# 偏差和方差
- 偏差bias:瞄的准不准,期望/均值,描述的是偏离真值的程度
- 方差variance:瞄的稳不稳(围绕某个值),描述的是数据的稳定程度
- 两者共同描述数据的误差情况
# fine-tuning
- 微调,也是实现迁移学习的一种手段
- 换一个与目标更接近的数据集或者只更新一部分参数等
# SGD
- Stochastic Gradient Descent,随机梯度下降法
- 为什么没有用牛顿法:牛顿法要求Hessian矩阵,二次微分,计算量很大,带来的是update的更准确
# SGDM
- SGD with momentum,SGD加入动量机制,加入动量机制后参数更新可以保持之前的更新趋势,而不会卡在当前梯度较小的点
- SGDM没有考虑对学习率做自适应更新
# AdaGrad
- Adaptive Gradient,自适应梯度下降
- 利用迭代次数和累积梯度,对学习率进行自动衰减
- 对学习率加以调整的优化方法
- 在SGD的基础上增加了二阶动量
- Adagrad有个致命问题,就是没有考虑迭代衰减
# RMSProb
- Root Mean Square Prob
- 与AdaGrad相似,加入了迭代衰减因子(学习率除以前t-1次迭代的梯度的加权平方和)
- 与当前迭代越近的梯度,对当前影响应该越大
# ADAM
- Adaptive Momentum
- Adam是SGDM和RMSProp的结合,它基本解决了之前提到的梯度下降的一系列问题,比如随机小样本、自适应学习率、容易卡在梯度较小点等问题,2015年提出
- 对学习率加以调整的优化方法
- 把一阶动量和二阶动量全部都用起来
# Optimizer
- 优化器/算法
- 五大优化器其实分为两类,SGD、SGDM 和 Adagrad、RMSProp、Adam。使用比较多的是SGDM和Adam
- SGDM多用于计算机视觉:图像分类,图像分割,目标检测等
- Adam多用于NLP、语音合成、GAN、强化学习等
# feature scaling
- 特征缩放,更新参数更容易,更有效率
- 示意图


# Meta Learning
- 元学习。学习如何学习,学习到比人类设计更为有效的模型
# 激活函数
- 激活函数即非线性映射,引入激活函数的目的是为了增加神经网络的非线性。如果没有激活函数,每层都相当于矩阵相乘,叠加若干层后仍然只起到线性映射的作用,无法应用到非线性模型当中
- 常见的三个激活函数
- sigmoid函数:值域(0, 1)。输出0~1,符合门控的物理定义
σ ( x ) = 1 ( 1 + e − x ) σ(x) = \frac{1}{(1 + e^{-x})} σ(x)=(1+e−x)1

- tanh函数:双曲正切函数,值域(-1, 1)。tanh函数是sigmoid函数向下平移和收缩后的结果,tanh函数在输入为0附近相比sigmoid有更大的梯度,通常使模型收敛更快
t a n h ( x ) = 2 σ ( 2 x ) − 1 = ( 1 − e − 2 x ) ( 1 + e − 2 x ) tanh(x) = 2σ(2x) - 1 = \frac{(1 - e^{-2x})} {(1 + e^{-2x})} tanh(x)=2σ(2x)−1=(1+e−2x)(1−e−2x)

- ReLU函数:值域[0, +无穷),由于sigmoid和tanh存在上述的缺点,relu激活函数成为了大多数神经网络的默认选择
f ( x ) = m a x ( 0 , x ) f(x) = max(0, x) f(x)=max(0,x)
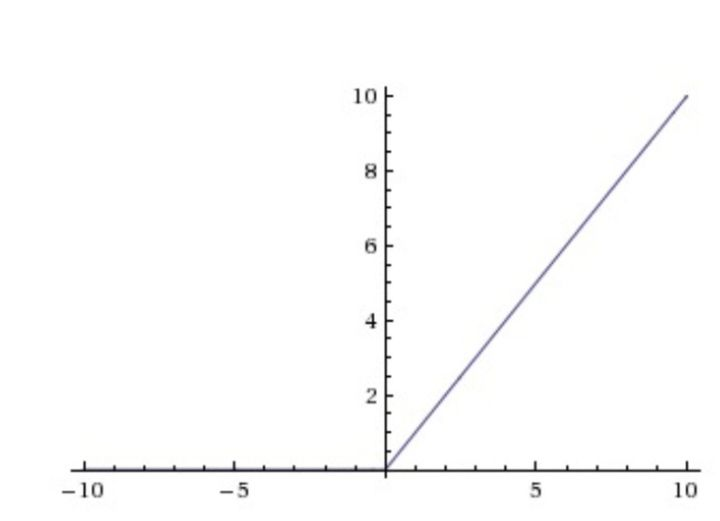
# softmax
-
归一化指数函数,它是二分类sigmoid函数在多分类问题上的推广
-
softmax首先将模型预测结果转换到指数函数上,这样保证了概率的非负性
然后将转换后的结果进行归一化处理 -
输入为向量,输出为值为0-1之间的向量,和为1
s o f t m a x ( x ) = e x i ∑ j = 1 k e x j softmax(x) = \frac {e^{x_i}} {\sum_{j=1}^{k}e^{x_j}} softmax(x)=∑j=1kexjexi
其中k表示多个输出或类别数,x表示输出向量,xj表示输出向量中第j个输出或类别的值import numpy as np data=np.array([0.1, 0.3, 0.6, 2.1 ,0.55]) np.exp(data)/np.sum(np.exp(data))array([ 0.07795756, 0.09521758, 0.12853029, 0.57603278, 0.12226179])
# …
下一篇:机器学习的基本概念/术语2
参考文章:
激活函数图像和优缺点比较
softmax/argmax/softargmax比较
created by shuaixio, 2022.05.02














 4289
4289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









