







上一篇:机器学习的基本概念/术语1
序言
记录机器学习基本概念,不做详细解释,常识积累。长期更新…
# KNN
-
k-Nearest Neighbor
-
K最近邻算法,每个样本都可以用它最接近的k个邻居来代表
-
既可以用于分类也可以用于回归,是一种监督学习算法
-
KNN用于分类的计算过程:
1)计算待分类点与已知类别的点之间的距离
2)按照距离递增次序排序
3)选取与待分类点距离最小的K个点
4)确定前K个点所在类别的出现次数
5)返回前K个点出现次数最高的类别作为待分类点的预测分类 -
KNN用于回归的计算过程:
要预测的点的值通过求与它距离最近的K个点的值的平均值得到
这里的"距离最近"可以是欧氏距离,也可以是其他距离 -
KNN的关键点:
(1)算法超参数K
(2)距离度量,特征空间中样本点的距离是样本点间相似程度的反映
(3)分类决策规则,少数服从多数。
# dropout rate
-
丢弃率
-
dropout: 训练的时候会停止训练一些神经元,但是测试的时候,整个模型是完整的不会dropout 任何神经元
-
dropout效果可能更好的原因:
第一是模型不会依赖于某些神经元,每个神经元都会受到特殊关注,从而使网络变得更强大。最终模型对输入的微小变化不再敏感,这等价于测试阶段输入前所未见的样本时,模型也能很好地进行预测;
第二是dropout可以看成是一种集成学习方法,每次对神经元进行随机丢弃,都会产生一个不同的神经网络结构,那么训练完毕后所得到的最终的神经网络,就可以看作是所有这些小型神经网络的集成 -
如果发现模型可能发生严重的过拟合问题,可以增大dropout rate,比如大型神经网络模型
-
而如果模型发生过拟合的风险较小,那么可以减小dropout rate,比如小型神经网络模型
# GRU
-
Gated Recurrent Unit,门控循环单元结构,LSTM模型的变体
更新门 + 重置门
LSTM:输入门 + 输出门 + 遗忘门 -
同LSTM一样,可以有效捕捉长序列之间的语义关联,缓解梯度消失或者梯度爆炸现象,结构比LSTM简单;不能完全解决梯度消失问题,也不能并行计算,数据量和模型体谅增大后存在瓶颈
# ResNet
-
Residual Neural Network,残差网络
残差:观测值和估计值的差 f(x) = h(x) – x->h(x) = f(x)+x -
引入残差解决由于网络层数加深导致的训练/测试准确率下降问题,网络的加深可能会导致梯度消失和梯度爆炸问题
# NB
-
Naive Bayes,朴素贝叶斯算法。基于贝叶斯定理和特征条件独立假设的分类方法
-
前提假设:各个特征条件之间是相互独立的
-
优点:
算法逻辑简单易于实现,分类过程中时空开销小,也具有比较好的解释性 -
缺点:
特征条件或属性相互独立的假设在实际中往往不成立,当属性之间相关性比较大时分类效果不好 -
朴素贝叶斯算法一般应用在文本分类,垃圾邮件的分类,信用评估,钓鱼网站检测等
# GCN
- Graph Convolutional Network, 图卷积网络
# GAT
- Graph Attention Network, 图注意力网络
# TCN
- Time Convolutional Network, 时间卷积网络
# HMM
- Hidden Markov Model,隐马尔可夫模型,是一个统计模型,用来描述含有隐含未知参数的马尔可夫过程
# GMM
- Gaussian Mixture Model, 高斯混合模型
- 任何一个数据的分布,都可以看作是若干高斯分布的叠加
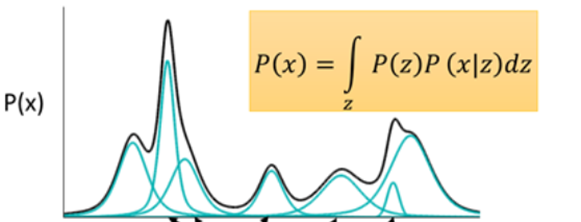
- 如图所示,如果P(x)是一种分布的话,存在一种拆分方法能让它表示成图中若干浅蓝色曲线对应的高斯分布的叠加。且已证明,当拆分数量达到512时,其叠加的分布已经相当于原始分布,误差已经非常小了
# VRNN
- Variational RNN,变分递归神经网络
- 将VAE融入了RNN当中,利用RNN的隐藏状态来建立时间序列的依赖关系,并在此基础上用VAE来对序列建模
# BEV
- Bird’s Eye View,鸟瞰图也称为上帝视角,是一种描述感知世界的视角或坐标系(3D)
- 将视觉信息转换到3D坐标系:由图像空间转换到BEV空间
- 理论上BEV可以应用在前、中、后融合上,不过前融合难度大,一般很少将BEV应用在前融合,偶尔也会用在后融合上,更多会应用在介于数据级融合和目标级融合之间的特征级融合,即中融合上;
# GAP
- Global Average Pool,全局平均池化层,特征取平均值
# ADE/FDE
-
ADE:Average Displacement Error,平均位移误差
预测轨迹和真值轨迹所有点的平均欧氏距离 -
FDE:Final Displacement Error,最终位移误差
预测轨迹和真值轨迹最后一个点的欧氏距离
# Embedding
-
其实可以理解为映射,将稀疏特征,映射到稠密特征,很多人也称为查表
-
这个稠密vector的每一个特征可以认为是有实际意义的,比如单/复数、名词/动词等
-
利用线性和非线性转换对复杂的数据进行自动特征抽取,并将特征表示为向量vector,这一过程一般也称为嵌入/embedding
-
Embedding是NLP领域最重要的发明之一,把独立向量相关联。经过embedding之后,一个长达数十万的稀疏vector被映射到数百维的稠密vector,这个稠密vector的每一个特征可以认为是有实际意义的,比如单复数,名词动词等等。在语言模型里,具有相似特性和意义的词语往往具有相似的周边词语,通过语言模型的训练,相似词语往往会具有相似的稠密vector表示,因此词语之间的相似性便可以简单的利用向量之间角度来衡量
# Backbone
- 主干网络,大多数时候指的是特征提取的网络,提取图片的信息供后面的网络使用
- 这些网络经常使用的是ResNet/VGG等,这些网络已经证明了在分类等问题上的特征提取能力是很强的;在用这些网络作为backbone的时候,都是直接加载官方已经训练好的模型参数,后面接着我们自己的网络。在训练过程中会对其进行微调,使其更适合我们的任务
# VGG
- Visual Geometry Group
- 是牛津大学计算机视觉组(Visual Geometry Group)和谷歌 DeepMind 一起研究出来的深度卷积神经网络,因而冠名为 VGG;通常人们说的VGG是指VGG-16(13层卷积层+ 3层全连接层)
# Bottle-neck Layer
- 瓶颈层,对应网络数据降维卷积再升维的过程,网络看起来像瓶颈
- Bottleneck的核心思想是利用多个小卷积核替代一个大卷积核,利用 1x1 卷积核替代大的卷积核的一部分工作
- 这种结构比较常出现在ResNet block残差网络中
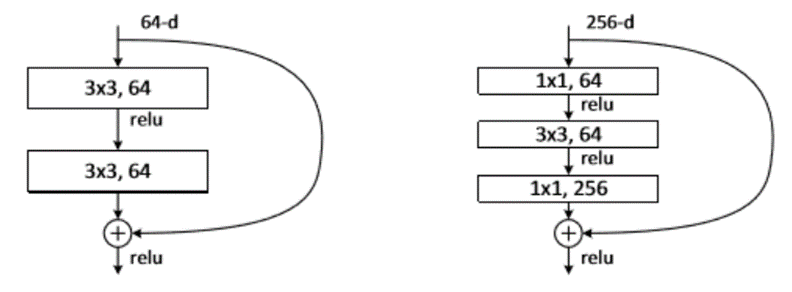
- 左边没有bottle-neck模块,右边有bottle-neck模块
- 使用 1×1的网络结构很方便改变维度;灵活设计网络,并且减小计算量
# Head
-
head是获取网络输出内容的网络,利用之前提取的特征,做出预测
-
一般网络的大致结构:
input → backbone → neck → head → output
# 有限差分
- 前向差分
f ′ ( x i ) = y i ′ ≈ y i + 1 − y i x i + 1 − x i f^{'}(x_{i} ) =y_{i} ^{'} \approx \frac{y_{i+1}-y_{i} }{x_{i+1}-x_{i} } f′(xi)=yi′≈xi+1−xiyi+1−yi
- 后向差分
f ′ ( x i ) ≈ y i − y i − 1 x i − x i − 1 f^{'}(x_{i} ) \approx \frac{y_{i}-y_{i-1} }{x_{i}-x_{i-1} } f′(xi)≈xi−xi−1yi−yi−1
- 中心差分
f ′ ( x i ) = y i ′ ≈ y i + 1 − y i − 1 2 h f^{'}(x_{i} ) =y_{i} ^{'} \approx \frac{y_{i+1}-y_{i-1} }{2h } f′(xi)=yi′≈2hyi+1−yi−1
# 属性空间/样本空间/输入空间
- 比如西瓜的”色泽”、”根蒂”、”敲声”等称为属性或特征,属性上的取值称为属性值;属性张成的空间称为属性空间、样本空间或输入空间。有时候整个数据集也称为一个样本,可看做样本空间的采样,可通过上下文判断出样本是单个实例还是数据集
# 特征空间
- 我们把每个样本称为一个实例,由特征向量表示;所有特征向量存在的空间称为特征空间,特征空间有时和输入空间相同也可能不同,不同的情况是输入空间通过某种映射生成了特征空间;在代数中,基向量-特征值-特征向量-特征空间(从一维到多维);某特征值对应的特征向量的线性组合依然是特征向量,这些线性组合后的特征向量组成了特征空间
# 输出空间/标记空间
- 输出label所有可能的取值集合,通常输出空间远小于输入空间
# 假设空间/版本空间
-
假设空间:
我们把学习的过程看作一个在所有假设组成的空间中进行搜索的过程,这个空间就是假设空间。假设空间一般是对于学习到的模型而言的,模型表达了输入到输出的一种映射集合,这个集合就是假设空间,假设空间表明着模型学习的范围 -
版本空间:
因为训练样本数量有限,假设空间含有很多假设,最终筛选后有可能剩下多个假设是符合训练样本的,这些剩下的假设组成的集合就称为版本空间
# 损失函数
- Loss Function,是定义在单个样本上的,算的是一个样本的误差
# 代价函数
- Cost Function,是定义在整个训练集上的,可能是损失函数的平均
# 目标函数
- Object Function,机器学习多数算法都需要最大化或最小化一个函数,即"目标函数"。一般把最小化的一类函数称为"损失函数"
# 风险函数
- Risk Function,损失函数的期望,期望损失Expected Loss/期望风险Expected Risk。可以认为是平均意义下的损失;风险函数有两种,不考虑正则项的是经验风险Empirical Risk,考虑过拟合问题加上正则项的是结构风险Structural Risk。期望风险与经验风险和结构风险的关系,类似期望和均值的关系,期望是先验、均值是后验;均值为多个随机变量的和再除以个数,相当于还是一个随机变量,当数量足够多的时候,这个随机变量会收敛,这个收敛的值为期望。所以期望风险是理想的全局最优的,是对所有样本预测错误程度的均值,基于所有样本点损失函数最小化,经验风险是局部最优
# 评估指标
- 为什么不直接把评估指标作为损失函数
当建立一个算法时,我们希望最大化一个评估指标,比如召回率或者精确率等,有些问题中评估函数可以直接作为评估指标,如回归问题中的MSE等;而且通常情况下损失函数对于模型参数是可微的,在某些情况下是凸的,更加容易优化,这是没有直接把评估指标当做损失函数的一个原因
# 数据增强
-
数据增强也叫数据扩增,意思是在不实质性的增加数据的情况下,让有限的数据产生等价于更多数据的价值。虽然现在各种任务的公开数据集有很多,但其数据量也远远不够,而公司或者学术界去采集、制作这些数据的成本其实是很高的,像人工标注数据的任务量就很大,这时候可以通过数据增强更好的利用现有的成本
-
传统的数据增强方法:随机翻转、旋转、裁剪、变形缩放、添加噪声、颜色扰动
-
此外还有随机擦除数据增强、马赛克数据增强等
# …
下一篇:机器学习基本概念/术语3
【参考文章】
KNN算法
dropout rate
ResNet
NB例子
GMM
BEV
Embedding
Embedding
Bottle-neck
Bottle-neck
有限差分
各种空间
特征空间的代数解释
created by shuaixio, 2022.07.30


















 472
472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









