







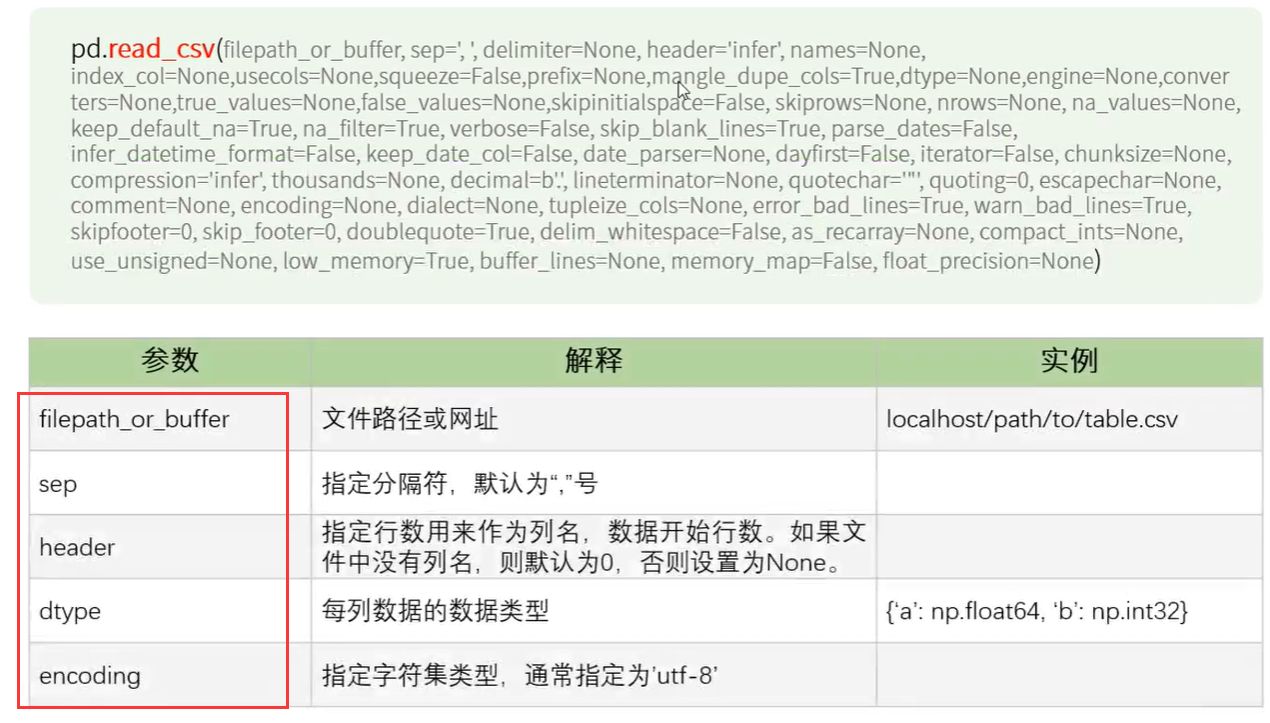
1、读取excel文件
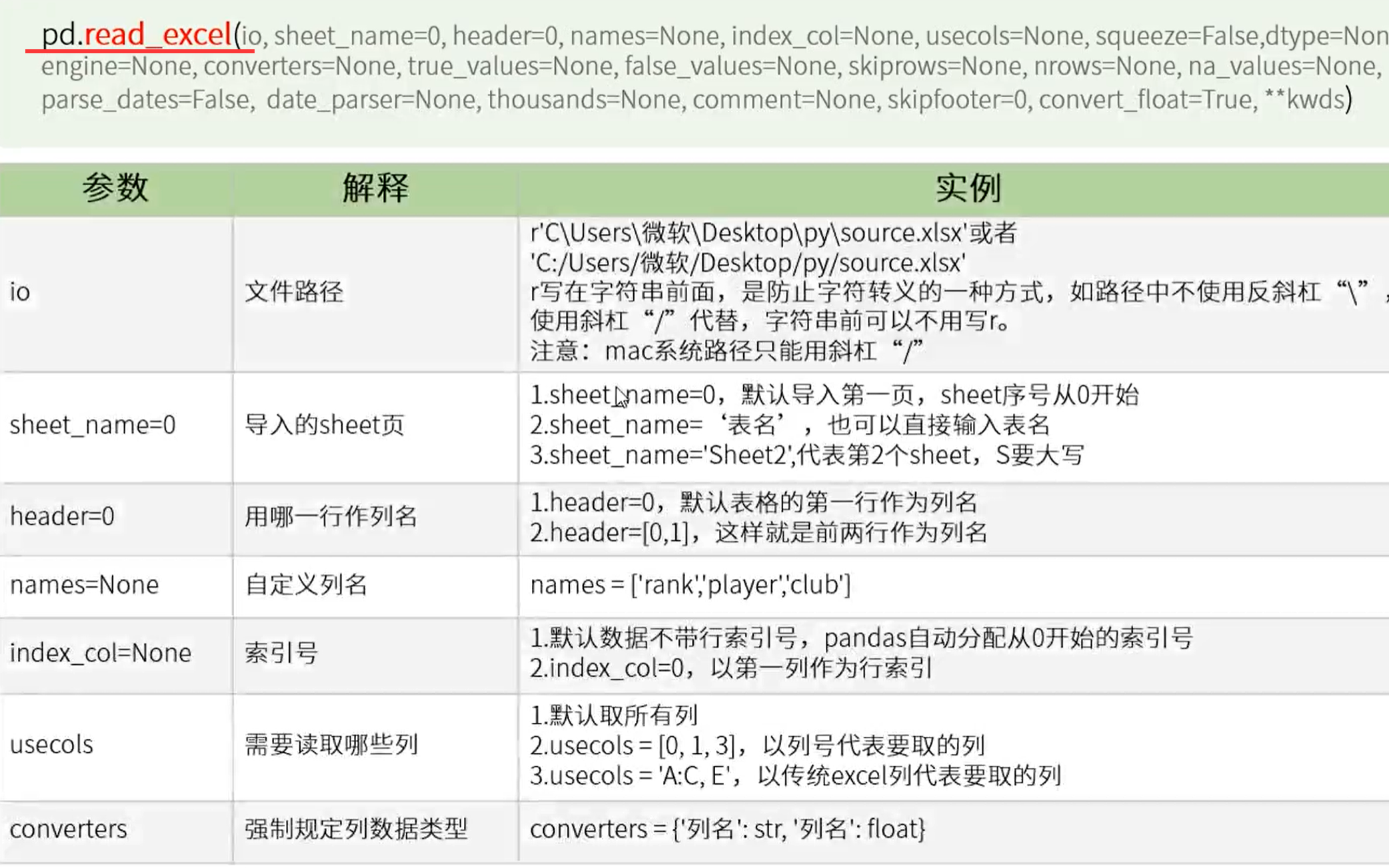
1.1 使用Pandas读取excel文件
- DataFrame 默认显示数据前5行(head()函数,指定几行数据)。
- df.head(10) # 显示前10行数据。
- df.tail(10) # 查看后10行数据。

1.2 计算
计算指标:求毛利和毛利率
Jupyter上运行如下
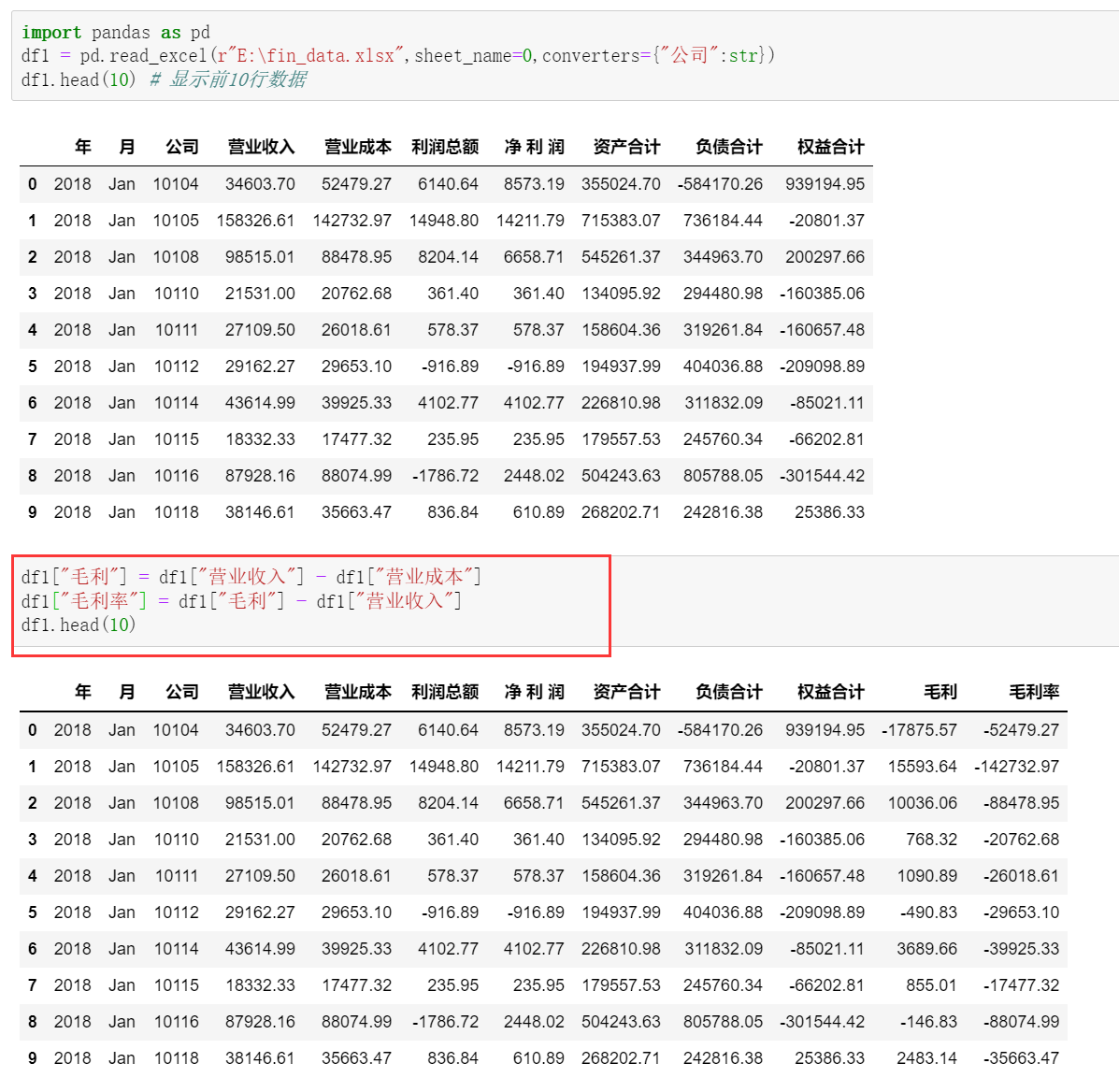
pycharm上运行如下
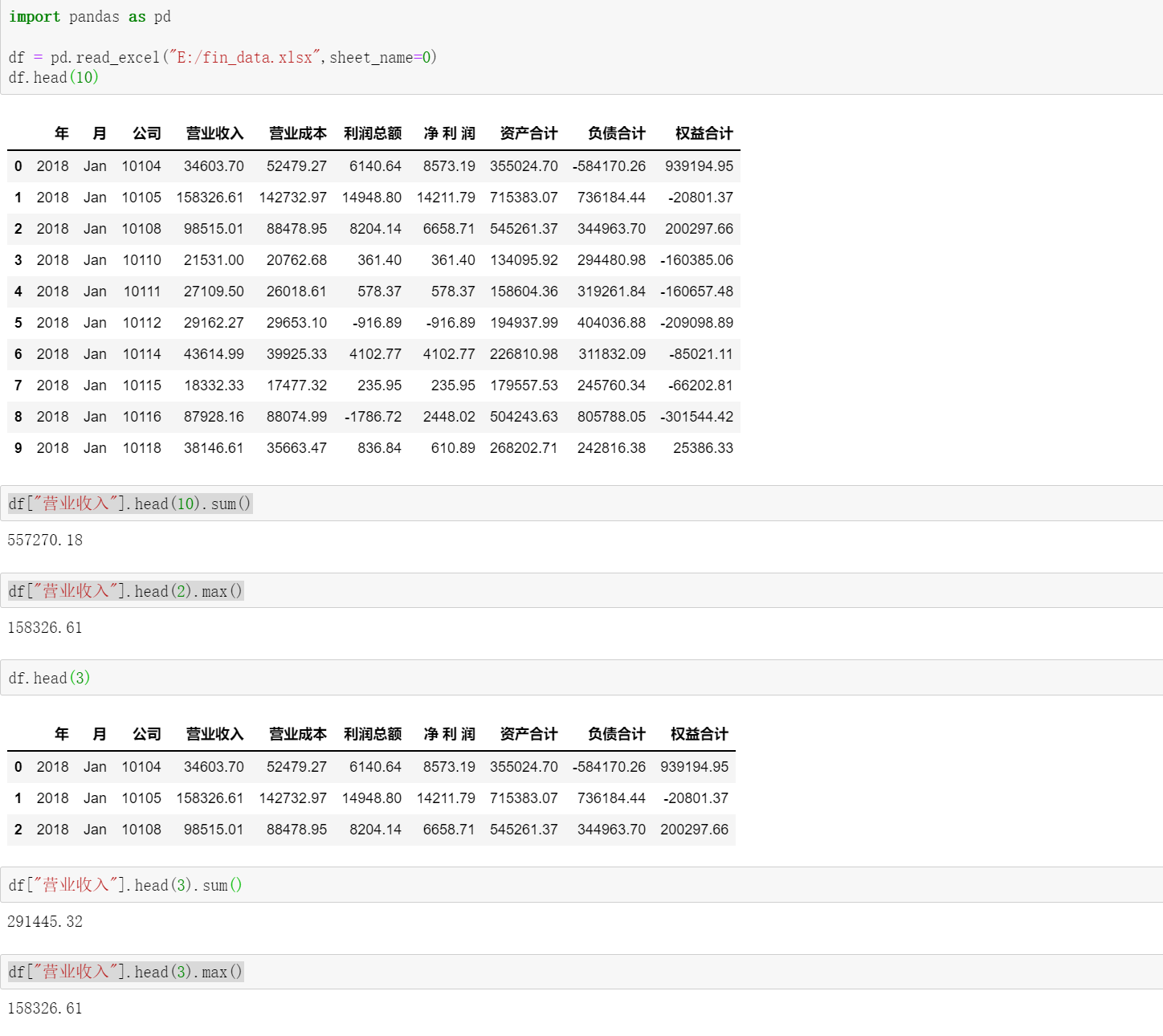
import pandas as pd
df1 = pd.read_excel("./fin_data.xlsx",sheet_name=0,converters={"公司":str})
df1["毛利"] = df1["营业收入"] - df1["营业成本"]
df1["毛利率"] = df1["毛利"] - df1["营业收入"]
print(df1.head(10)) # 显示前10行数据
输出:
年 月 公司 营业收入 ... 负债合计 权益合计 毛利 毛利率
0 2018 Jan 10104 34603.70 ... -584170.26 939194.95 -17875.57 -52479.27
1 2018 Jan 10105 158326.61 ... 736184.44 -20801.37 15593.64 -142732.97
2 2018 Jan 10108 98515.01 ... 344963.70 200297.66 10036.06 -88478.95
3 2018 Jan 10110 21531.00 ... 294480.98 -160385.06 768.32 -20762.68
4 2018 Jan 10111 27109.50 ... 319261.84 -160657.48 1090.89 -26018.61
5 2018 Jan 10112 29162.27 ... 404036.88 -209098.89 -490.83 -29653.10
6 2018 Jan 10114 43614.99 ... 311832.09 -85021.11 3689.66 -39925.33
7 2018 Jan 10115 18332.33 ... 245760.34 -66202.81 855.01 -17477.32
8 2018 Jan 10116 87928.16 ... 805788.05 -301544.42 -146.83 -88074.99
9 2018 Jan 10118 38146.61 ... 242816.38 25386.33 2483.14 -35663.472、写入excel文件
2.1 to_excel()函数
- to_excel()函数如果写到一个已经存在的excel,会将原有的excel表格中的数据全部覆盖。

import pandas as pd
# 读取excel
df1 = pd.read_excel("./fin_data.xlsx", sheet_name=0, converters={"公司": str})
# 计算毛利和毛利率
df1["毛利"] = df1["营业收入"] - df1["营业成本"]
df1["毛利率"] = df1["毛利"] - df1["营业收入"]
# 写入excel
df1.to_excel("./target.xlsx", sheet_name="毛利")
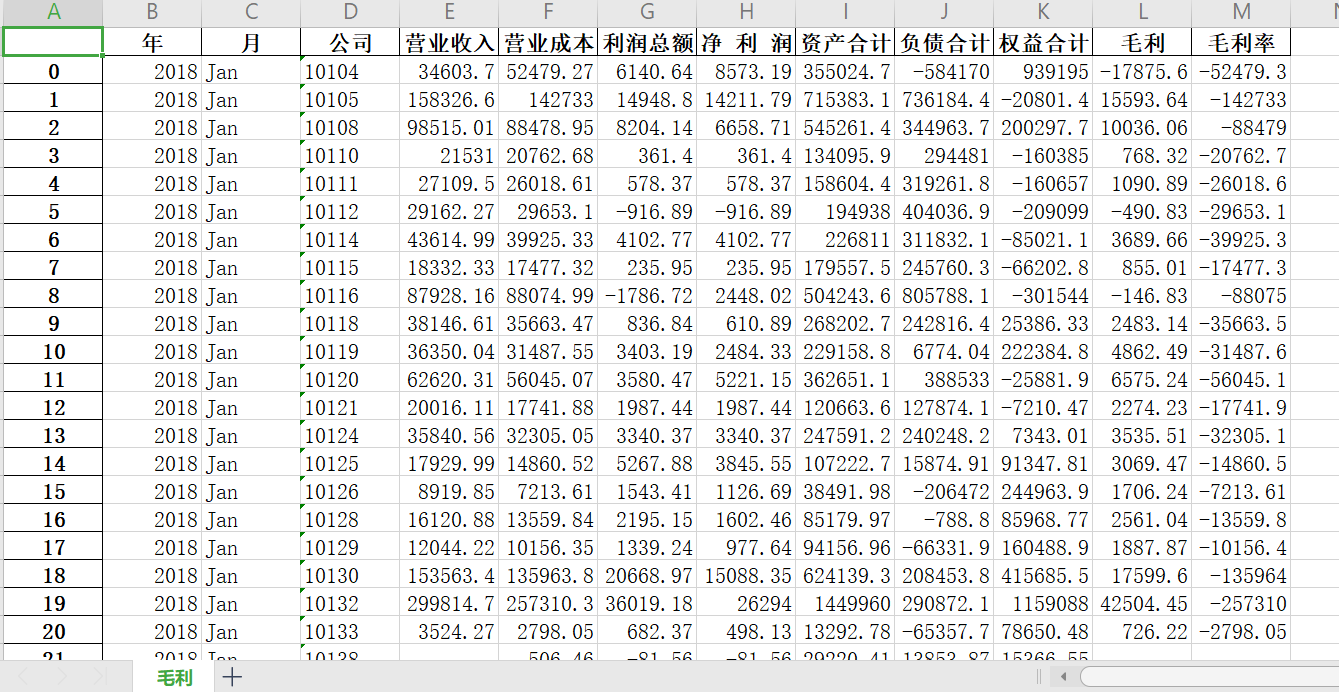
2.2 ExcelWriter()函数


import pandas as pd
# 读取excel
df1 = pd.read_excel("./fin_data.xlsx", sheet_name=0, converters={"公司": str})
with pd.ExcelWriter("./target.xlsx", mode="a") as writer:
df1.to_excel(writer, sheet_name="毛利2")
2.3 Pandas读写其他文件
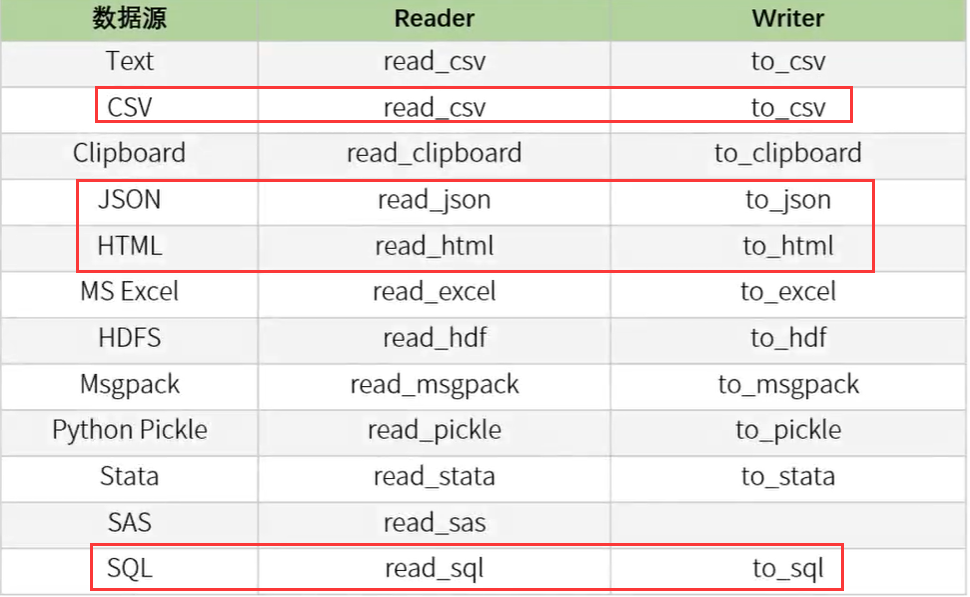
2.3.1 读取CSV
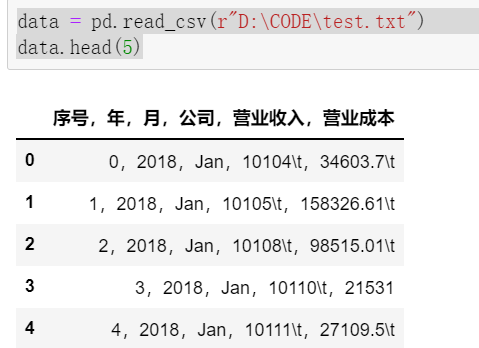

3、数据提取
3.1 直接索引
- df[ "列" ]:选取一列。
- df[ [ "列1" , "列2" ] ]: 选取多列,方括号里是一个列名组成的list。
- df[ n : m ]:按位置选取连续的行。
import pandas as pd
# 通过列表创建
data = [["100-浙江公司", 11111.00, 7777.00], ["200-北京公司", 22222.00, 8888.00], ["300-上海公司", 33333.00, 9999.00]]
df = pd.DataFrame(data=data, columns=["公司", "收入", "成本"], index=range(1, 4))
print(df["公司"]) # 选取一列
print(df[["公司", "收入"]]) # 选取多列
print(df[1:3]) # 按照位置选取连续的行
输出:
1 100-浙江公司
2 200-北京公司
3 300-上海公司
Name: 公司, dtype: object
公司 收入
1 100-浙江公司 11111.0
2 200-北京公司 22222.0
3 300-上海公司 33333.0
公司 收入 成本
2 200-北京公司 22222.0 8888.0
3 300-上海公司 33333.0 9999.0
3.2 布尔索引
布尔索引,也称为带有条件判断的索引,通过条件在数组中筛选出条件为True的数据。
- df[ (df["列"] == 条件) ] : 选取某列满足一定条件的行。
- df[ (df["列1"]==条件) & df["列2"] <= 条件)]:选取多列满足一定条件的行。
- 注意:索引列表中可以使用&、| 等操作符,但是不能使用and, or, not等关键字。
import pandas as pd
# 通过列表创建
data = [["100-浙江公司", 11111.00, 7777.00], ["200-北京公司", 22222.00, 8888.00], ["300-上海公司", 33333.00, 9999.00]]
df = pd.DataFrame(data=data, columns=["公司", "收入", "成本"], index=range(1, 4))
print(df[(df["公司"] == "100-浙江公司")]) # 选取公司是100-浙江公司的
print(df[(df["公司"] == "200-北京公司") & (df["收入"] >= 2222.00)])
输出:
公司 收入 成本
1 100-浙江公司 11111.0 7777.0
公司 收入 成本
2 200-北京公司 22222.0 8888.03.3 索引器
- Pandas中两种索引器应用于DataFrame,原始索引和自定义索引并存。
- 截取部分数据。
3.3.1 loc索引器
- 语法 : loc[index,column]
- loc索引器,只能使用数组的自定义索引,未设置自定义索引情况下,才可以使用原始索引,切片区间为闭区间。根据index和column进行选取,先index后column,可以只插入index。
- df.loc["行"] :选取一行。
- df.loc[["行1","行2"],["列1","列2"]] :选取行列组合。
- df.loc[行1:行2,列1:列2] :(切片)按列名选取连续列。
- df.loc[(df["列"]>条件)]: 选取列满足一定条件的行。
import pandas as pd
# 通过列表创建
data = [["100-浙江公司", 11111.00, 7777.00], ["200-北京公司", 22222.00, 8888.00], ["300-上海公司", 33333.00, 9999.00]]
df = pd.DataFrame(data=data, columns=["公司", "收入", "成本"], index=range(1, 4))
print(df.loc[1]) # 选取一行
print(df.loc[[1, 2], ["公司", "成本"]]) # 行列组合
print(df.loc[[3], "公司": "成本"]) # 按照列名选取连续的列
输出 :
公司 100-浙江公司
收入 11111.0
成本 7777.0
Name: 1, dtype: object
公司 成本
1 100-浙江公司 7777.0
2 200-北京公司 8888.0
公司 收入 成本
3 300-上海公司 33333.0 9999.0
3.3.2 iloc索引器
- 语法: iloc[index,column]
- iloc索引器与loc索引器的使用几乎相同,唯一不同的是,iloc索引器中只能使用原始索引,不能使用自定义索引(会报错)。
- 注意:原始索初始值从0开始,切片前闭后开。自定义索引切片为闭区间。
import pandas as pd
# 通过列表创建
data = [["100-浙江公司", 11111.00, 7777.00], ["200-北京公司", 22222.00, 8888.00], ["300-上海公司", 33333.00, 9999.00]]
df = pd.DataFrame(data=data, columns=["公司", "收入", "成本"], index=range(1, 4))
print(df.iloc[:2, 1:3])
输出:
收入 成本
1 11111.0 7777.0
2 22222.0 8888.03.4 DataFrame 索引
- DataFrame索引包含“行索引”和“列索引”。
- DataFrame中,原始索引(也就是从0开始的数字)和自定义索引并存。
- loc的参数只能接收自定义索引,未设置自定义索引的情况下使用原始索引。
- iloc的参数只能接受原始索引。
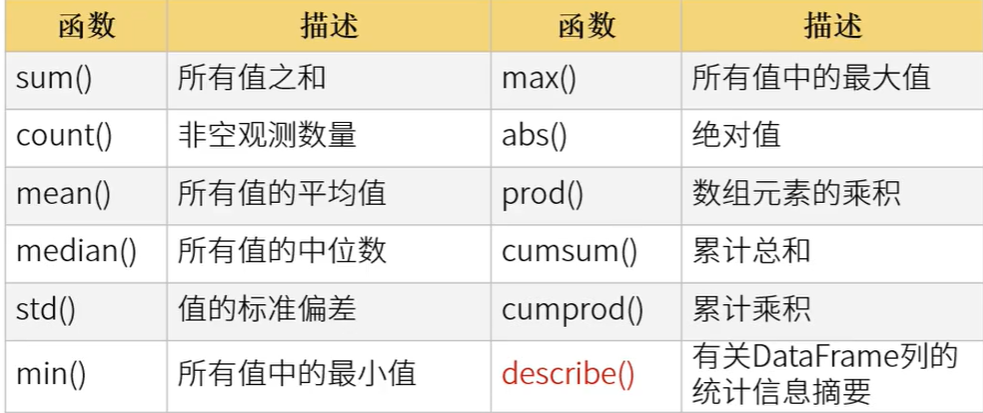
4、统计分析
4.1 统计函数
以下函数除了describe函数外,都有一个axis轴参数,默认axis=0时逐列计算,axis=1时逐行计算
4.2 Describe函数
- describe()函数 将所有数值列进行总体描述统计分析。
- 返回的DataFrame里计算出了常见的统计指标。
- 也可以结合索引器单独提取想要的指标数据。


4.3 数组排序
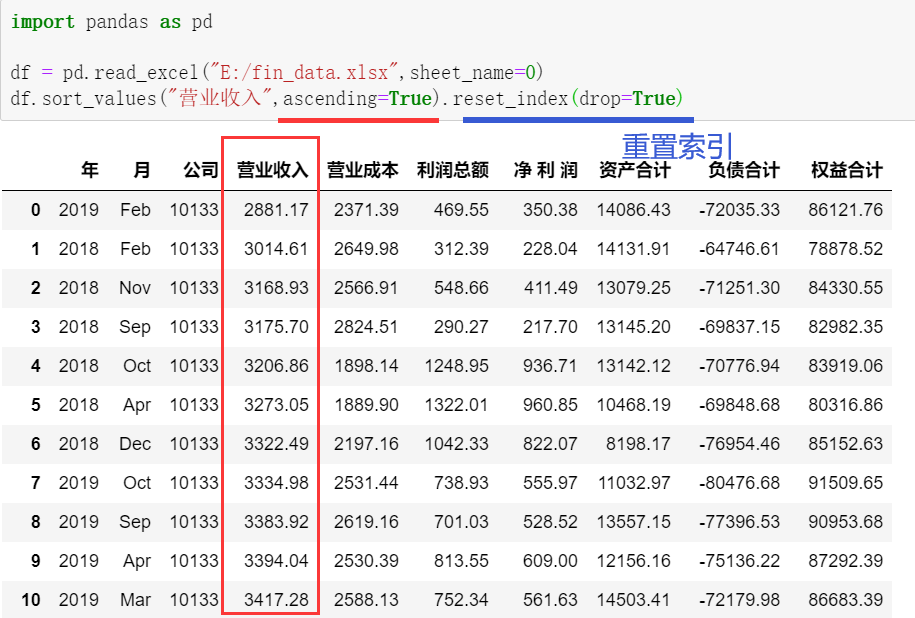
4.3.1 sort_values()函数
- 可以按照某行或者某列的值进行升序或者降序排序。
- 语法:DataFrame.sort_values(by,axis=0,ascending=True)。

- reset_index():索引重置,drop=True参数设置删除原有索引,默认重置后会增加新的列存储原有索引。
4.3.2 sort_index()函数
- 可以指定轴上根据索引值对数据进行排序,默认使用行索引升序排序。
- 语法:sort_index(axis=0,ascending=True)
4.3.3 drop()函数 和 insert()函数

4.4 累计统计
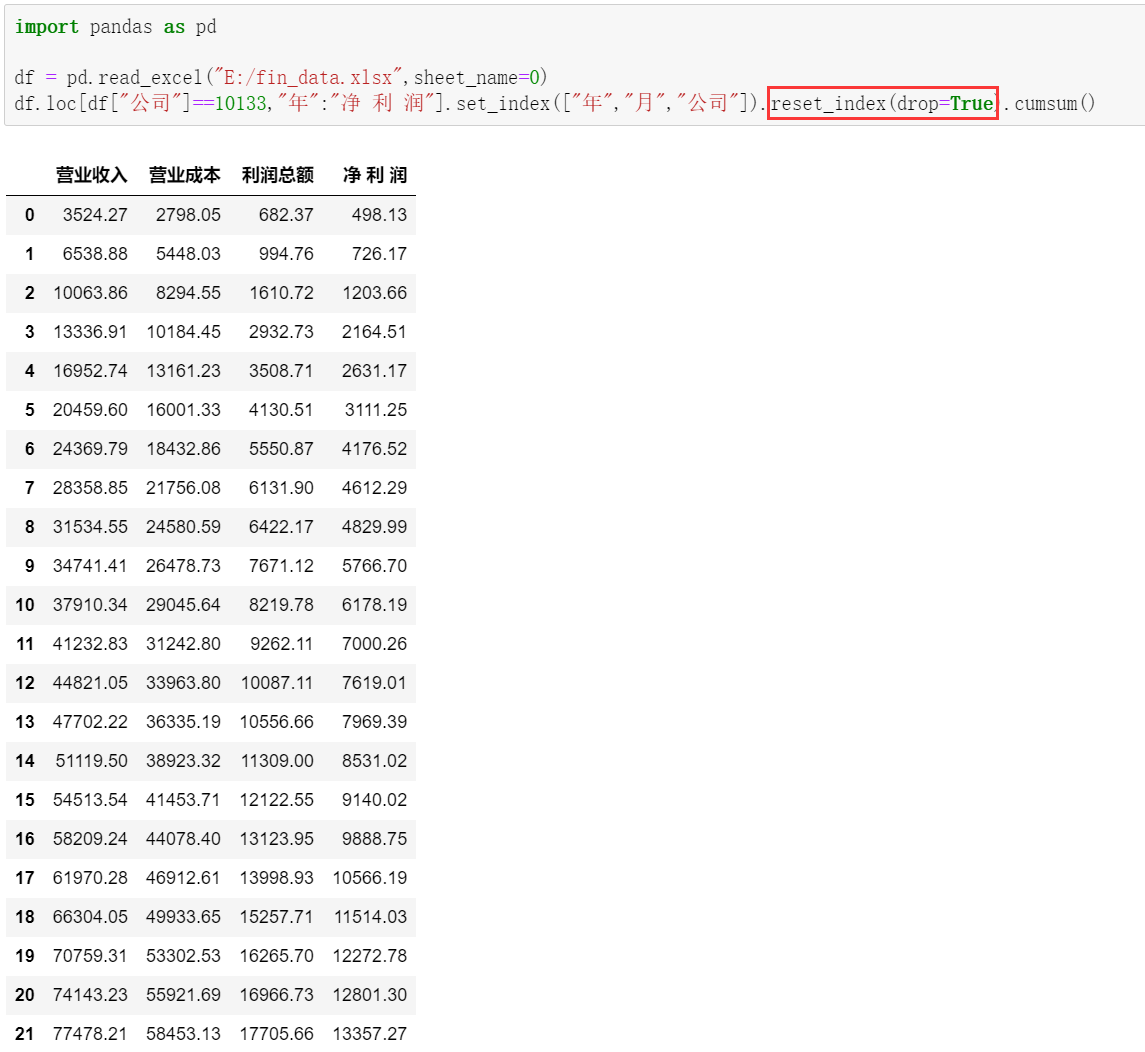
4.4.1 累计统计函数cumsum()函数

4.4.2 set_index(drop=True) 函数
将DataFrame中的列转化为行索引,想要保留原来的列索引可以使用drop=False参数,默认为True。

4.4.3 reset_index(drop=True) 函数
重置索引,获取新的index(0开始的数字)的同时,原来的index变成列保留下来。如果不想保留原来的index,使用参数drop=True(默认Flase,保留原来索引)。














 441
441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









