







1、Pandas 的起源 -Numpy
- Pandas 是基于Numpy构建的含有更高级数据结构和工具的数据分析包。
- Numpy是一个python第三方扩展程序库。支持大量的维度数组和矩阵运算,除此之外也针对数组运算提供大量的数学函数库。
1.1 数组(ndarray)的定义
- 用np.array()可以将列表数据类型(List)转化为ndarray数组。
- np.array是一个函数方法,用来创建一个ndarray对象。ndarray数组是用np.ndarray类的对象表示n维数组。
- nparray数组一般要求所有元素类型相同(同质)数组下标从0开始。
- 数组输出成[ ]形式,元素间由空格分开。
- 引入Numpy的约定别名一般是np,ndarray(数组)是Numpy最重要的数据类型。
- 引入规则 : import numpy as np
import numpy as np
a = np.array([[0,12,3,4,5],
[6,7,8,9,10]])
print(a)
输出:
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]]1.2 数组(ndarray)与列表(list)的区别
- 列表内部元素使用逗号分开,数组内部元素间用空格分开。
-
同一个列表里可以接收不同类型的数据,数组一般要求所有元素类型相同(称为同质,有助于节省运算和存储空间)。
- 数组对象可以去掉元素间循环直接计算(提升性能),列表需要循环。
- Pandas是基于NumPy的改造,因此Pandas也有相似的特征,可以提高运算。
1.3 ndarray的属性
- 数组维度ndim。
- 数组形状(行列)shape。
- 数组中元素的个数size(shape乘积)。
- 数组内元素的类型dtype。

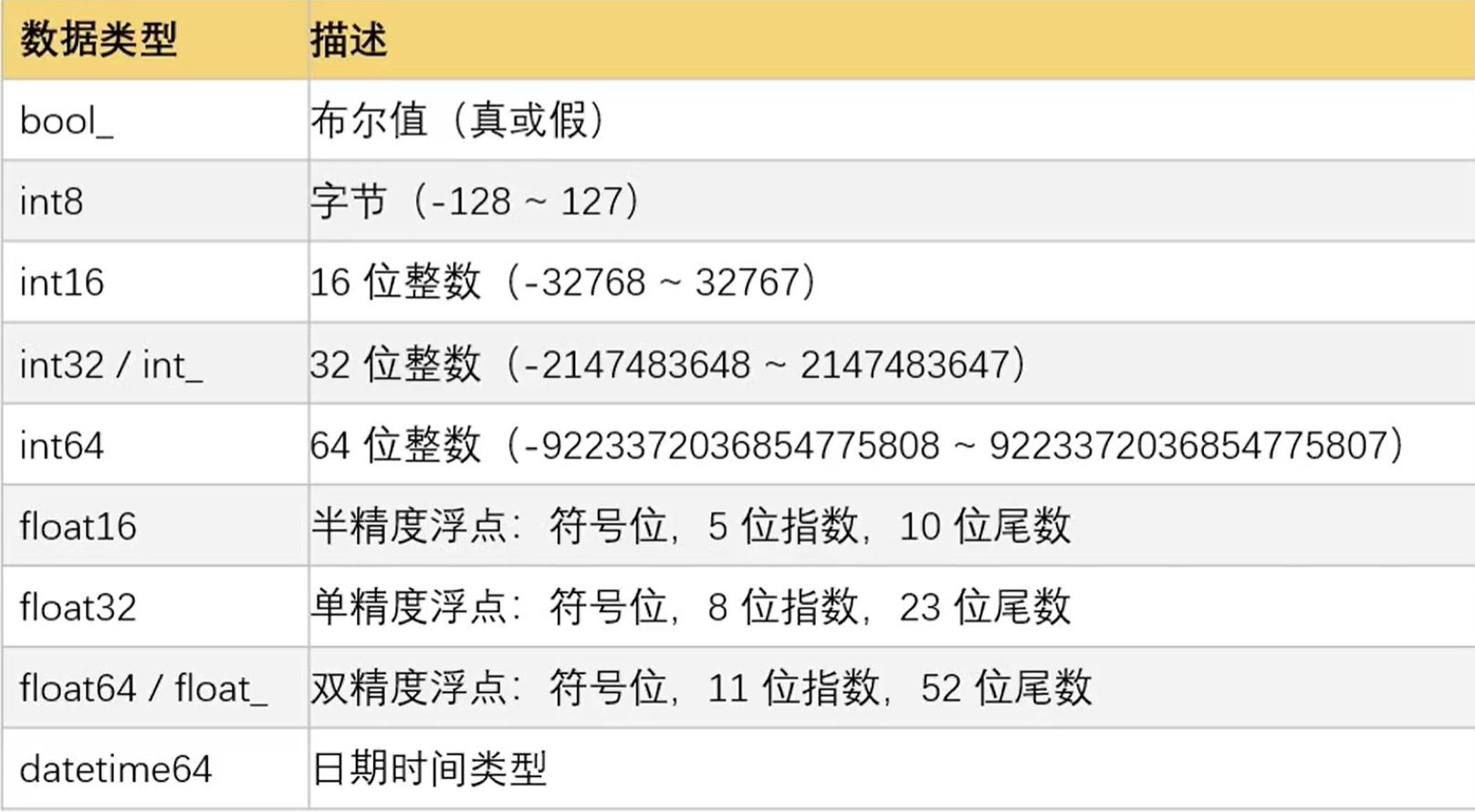
1.4 Numpy数组数据类型dtype
为了区别于python原生数据类型,合理使用存储空间并优化计算性能,bool/int/float/str等类型名称末尾都加上了_或位数。如下表
1.5 Numpy常用函数

import numpy as np
b = np.random.random((2,4))
print(b) # 两行四列数组
print(np.sum(b)) # 求和
print(b.sum()) # 求和
print(np.min(b))
print(np.max(b))
输出:
[[0.10255578 0.09103664 0.98938642 0.74137929]
[0.47280561 0.55578626 0.1305344 0.61379109]]
3.697275470709449
3.697275470709449
0.091036637092282381.6 ndarry 对象
- NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引。
- ndarray 对象是用于存放同类型元素的多维数组。
- ndarray 中的每个元素在内存中都有相同存储大小的区域。
- 语法:numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
参数说明:
| object | 数组或嵌套的数列 |
| dtype | 数组元素的数据类型,可选 |
| copy | 对象是否需要复制,可选 |
| order | 创建数组的样式,C为行方向,F为列方向,A为任意方向(默认) |
| subok | 默认返回一个与基类类型一致的数组 |
| ndmin | 指定生成数组的最小维度 |
实例:
import numpy as np
# 多于一个维度
n1 = np.array([[1, 2, 3], [11, 22, 33], [111, 222, 333]])
print(n1)
输出:
[[ 1 2 3]
[ 11 22 33]
[111 222 333]]
# 最小维度ndmin
n2 = np.array([[1, 2, 3], [11, 22, 33], [111, 222, 333]],ndmin=3)
print(n2)
输出:
[[[ 1 2 3]
[ 11 22 33]
[111 222 333]]]
# dtype 参数
n3 = np.array([[1, 2, 3], [11, 22, 33], [111, 222, 333]],ndmin=3,dtype=str)
print(n3)
输出:
[[['1' '2' '3']
['11' '22' '33']
['111' '222' '333']]]2、Pandas
2.1 简介
- Pandas是Python第三方库,提供高性能易用数据类型和分析工具,提供了核心数组操作,它定义了处理数据的基本结构,并且赋予它们促进操作的方法,例如:
- 读取数据
- 调整索引
- 使用日期和时间序列
- 排序,分组,重新排序和数据调整
- 处理缺失值等
- 引入规则 import pandas as pd。
- Pandas包含两种数据类型:Series 和 DataFrame(DataFrame数据框就相当于我们平时接触的excel表格,Series数据类型就相当于从excel表中任取一列进行操作)。
- Numpy 和 Pandas的区别:
- Numpy只能存储相同数据类型的array,Pandas能处理不同数据类型的数据(例如:二维表格中不同列可以是不同类型的数据,一列为整数一列为字符串)。
- Numpy是数值计算扩展包,处理数组和矩阵非常方便。Pandas是python的一个数据分析包,是基于Numpy的一种工具,主要做数据处理用的,以处理二维表格为主提供处理数据的函数和方法。
- Numpy用于数值计算。Pandas用于数据处理和分析。
- Numpy核心数据结构是n维数组类型ndarray。 Pandas核心数据结构是Series和DataFrame。
2.2 Series 数据结构

Series 由索引(index)和列组成,函数如下:
语法:pandas.Series(data,index,dtype,name,copy)
参数说明如下:
- data:一组数据(ndarry类型)
- index:数据索引标签,如果不指定,默认从0开始
- dtype:数据类型,默认会自己判断
- name:设置名称
- copy:拷贝数据,默认False
实例如下:
import pandas as pd
data = [1,2,3]
df1 = pd.Series(data,index=["X","Y","Z"])
print(df1)
输出:
X 1
Y 2
Z 3
dtype: int642.3 DataFrame 数据结构
- Pandas中的数据结构-DataFrame,它以表格形式存储,并且有对应的行和列。
- DataFrame和我们日常中使用的Excel长的相似,和数据库表也如出一辙。
- DataFrame是一个表格型的数据类型,每列值类型可以不同。
- DataFrame既有行索引,也有列索引。
- DataFrame常用于二维数据。

- 语法:pd.DataFrame(data,columns=[序列],index=[序列]) ,columns(列名)和index不写,默认从0开始的数字。
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
- data:一组数据(ndarry,series,map,lists,dict等类型)
- index:索引值,或者称为行标签
- columns:列标签,默认RangeIndex(0,1,2......n)
- dtype:数据类型
- copy:拷贝数据,默认为Flase
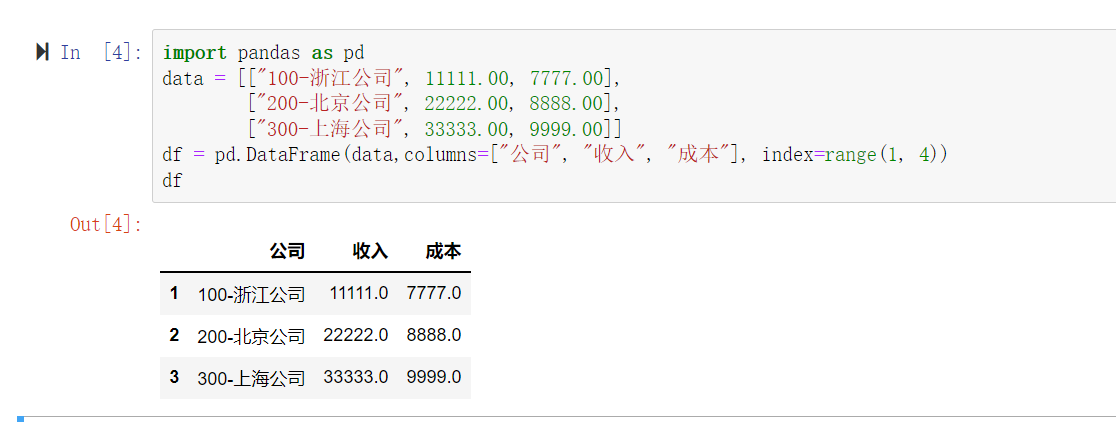
- 创建一个DataFrame

import pandas as pd
# 通过列表创建
data = [["100-浙江公司", 11111.00, 7777.00], ["200-北京公司", 22222.00, 8888.00], ["300-上海公司", 33333.00, 9999.00]]
print(pd.DataFrame(data=data, columns=["公司", "收入", "成本"], index=range(1, 4)))
# 通过字典创建
dic_data = {"公司": ["100-浙江公司", "200-北京公司", "300-上海公司"],
"收入": [11111.00, 22222.00, 33333.00],
"成本": [7777.00, 8888.00, 9999.00]}
print(pd.DataFrame(data=dic_data))
输出:
公司 收入 成本
1 100-浙江公司 11111.0 7777.0
2 200-北京公司 22222.0 8888.0
3 300-上海公司 33333.0 9999.0
公司 收入 成本
0 100-浙江公司 11111.0 7777.0
1 200-北京公司 22222.0 8888.0
2 300-上海公司 33333.0 9999.0
2.3.1 Jupyter 安装及使用
- pip install jupyter
- 创建空文件夹(例如:Jupyter_Notebooks)
- 打开本地文件夹Jupyter_Notebooks终端,执行命令:jupyter notebook
- 开启Jupyter
- 默认浏览器访问URL:http://localhost:8888/tree
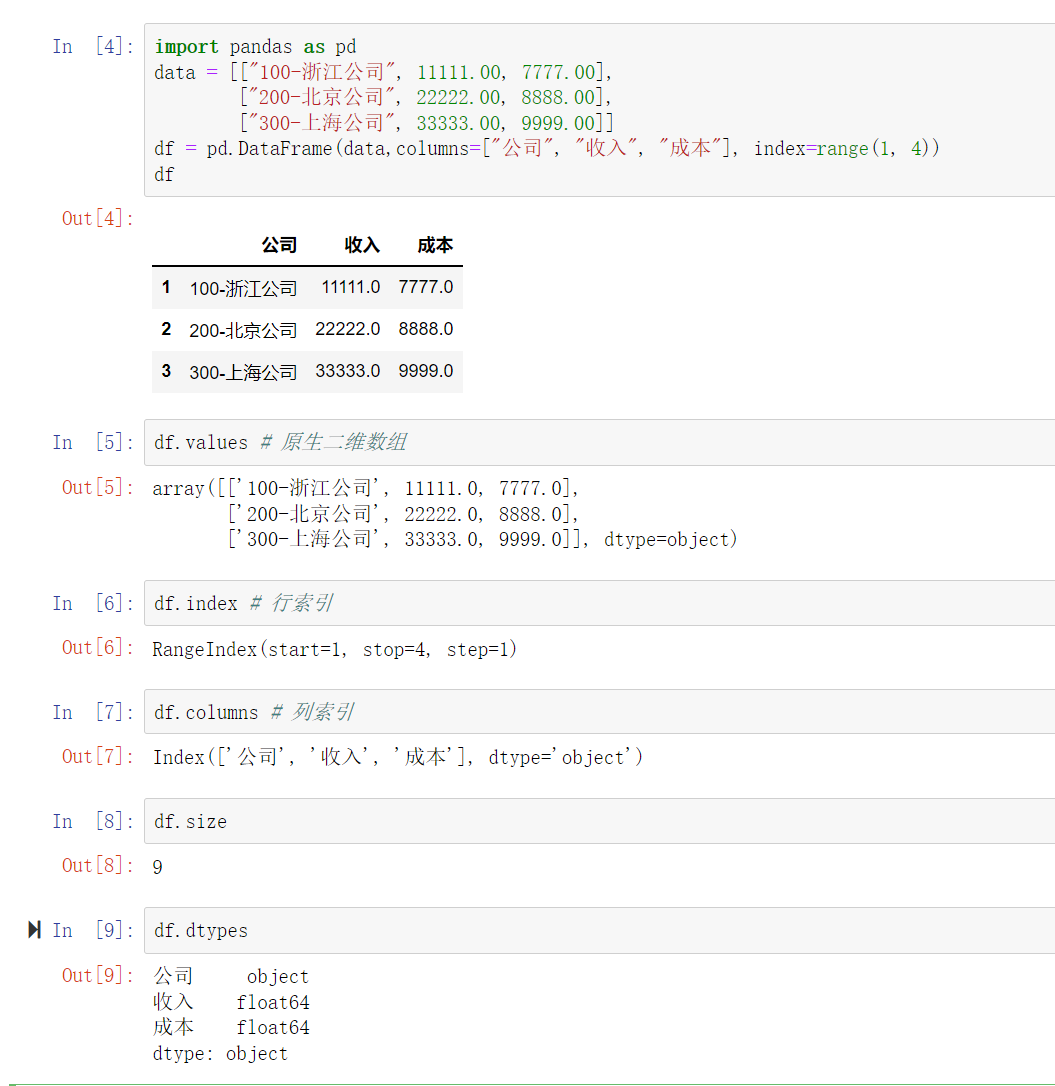
2.4 DataFrame 的属性

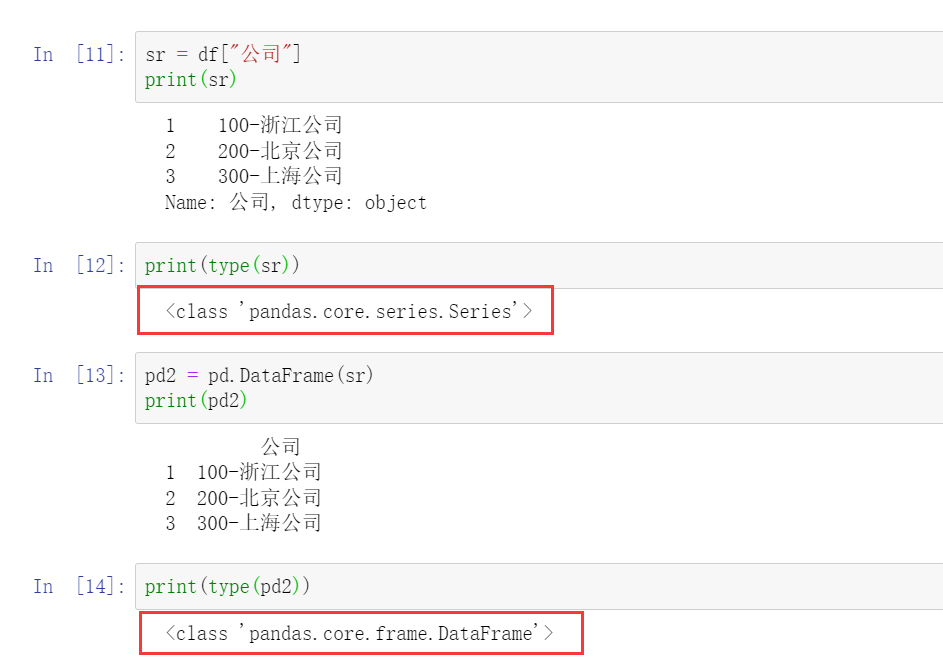
2.5 DataFrame 和 Series相互转化
DataFrame单独取一行或者一列就是一个Series,也可以将Series转化成单列的DataFrame。
2.6 DataFrame 的简单运算
例如:计算每家公司的毛利和毛利率
DataFrame的计算具有自动对齐功能,所以计算结果会一一对应索引。
















 6459
6459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









