








【深度学习】TensorFlow学习之路二
本系列文章主要是对OReilly的Hands-On Machine Learning with Scikit-learn and TensorFlow一书深度学习部分的阅读摘录和笔记。
一、感知机(Perceptron)
感知机是最简单的ANN(Artificial Neural Network)结构之一,它是由一系列线性阈值单元(LTU:linear threshold unit)组成的。
-
LTU基本结构
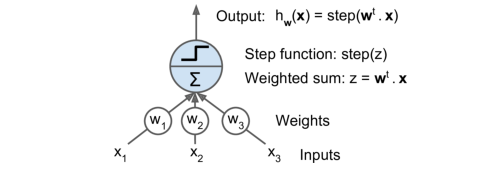
LTU即是对输入的样本向量X做一个加权加和,然后再放到一个阶跃函数中;如果把最后的阶跃函数换成sigmoid函数,其实LTU就是一个逻辑回归。 -
感知机基本结构
感知机即是一个由单层LTU组成的结构,每一个神经元都连接着所有的输入项(全连接结构),如下图是一个由两个输入项(x1和x2)和三个输出项构成的感知机结构,这样一个感知机可以同时输出三个二分类结果,所以可以用作一个多分类器。
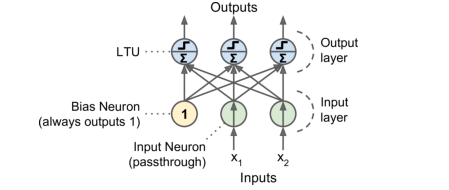
-
感知机如何训练
感知机其实就是寻找一个分割线,可以最大程度地把x1和x2这个二维空间内的所有点正确分割。其训练的目标就是使误分类的所有样本,到分割线的距离之和最小;具体过程为每次喂入一个训练样本,对这个样本的错分类输出项权重做梯度下降,表达式为:
w i , j n e x t _ s t e p = w i , j + η ( y p r e d j − y j ) x i w_{i,j}^{next\_step} = w_{i,j}+\eta(y_{pred_j}-y_{j})x_i wi,jnext_step=wi,j+η(ypredj−yj)xi
其中 w i , j w_{i,j} wi,j为第i个输入神经元和第j个输出神经元之间的权重值; y p r e d j y_{pred_j} ypredj为第j个输出神经元的预测值; y j y_{j} yj为第j个输出神经元的标签; x i x_i xi为输入训练样本的第i个输入项。 -
感知机代码实现
直接用sklearn里面的Perceptron分类器:from sklearn.linear_model import Perceptron其实我们也可以发现,感知机的训练过程就是一个每次取一个样本的随机梯度下降过程,所以调用SGDClassifier也可以达到一样的效果:
from sklearn.linear_model import SGDClassifier clf = SGDClassifier(loss="perceptron",penalty=None) -
感知机的局限性

像所以线性分类器一样,感知机不能解决异或问题:如上图所示,当x1和x2取值相同时,结果为0,取值不同时,结果为1,那么感知机就无法找到一个分割线来做出正确区分。
然而,当我们多搞几层感知机后,这个问题就迎刃而解了。
二、多层感知机(MLP)和后向传播
多层感知机(MLP)由一个输入层,一个或多个中间层(隐层)和最终输出层组成,除了输出层,每层都会增加一个偏差神经元,用于拟合截距项;每一层都是全连接的。当一个ANN拥有两个或多个隐层时,我们就称其为深度神经网络(DNN)。

- 后向传播算法
这样一个深度神经网络要如何训练呢?不妨参照一下线性回归的拟合过程:从目标函数MSE出发,对每一个变量的权重值 w i w_i wi求偏导以评估每一个变量对最终误差的贡献,然后沿着目标函数梯度方向一次一小步地调整每个权重值,直至让最终误差(目标函数)最小。
深度神经网络也是同样的道理,只不过表达式相比线性回归复杂了一些,所以它的拟合过程是这样的:
- 把样本喂入神经网络计算出预测值;
- 计算预测值和真实值之间的误差;
- 通过对每个权重求偏导的方式,计算上一层隐层中的每一个神经元对最终误差的贡献;
- 计算再上一层每个神经元对误差的贡献直至到输入层为止;
- 对每一层的每一个权重值进行一小步调整,使误差减小。
这样一个计算过程即是后向传播算法,目的是计算出每一层每个权重值的梯度方向,然后让所有的权重沿着梯度下降一小步,不断迭代直至收敛。
为了能执行这样的后向传播算法,必须要让每一步计算都得有梯度。所以首先要做优化的地方就是把梯度处处为0的阶跃函数给替换掉,换成其他有梯度的激活函数。
- 常见激活函数
- sigmoid激活函数:
σ ( z ) = 1 1 + e − z \sigma(z) = \frac{1}{1+e^{-z}} σ(z)=1+e−z1 - 双曲正切激活函数:
t a n h ( z ) = 2 σ ( 2 z ) − 1 tanh(z) =2\sigma(2z)-1 tanh(z)=2σ(2z)−1
和sigmoid函数类似,都是S型且处处可导,取值范围和sigmoid不同,为-1到1,相当于对每一层的输出多多少少做了正则化,可以加速收敛。 - Relu激活函数:
R e l u ( z ) = m a x ( 0 , z ) Relu(z) =max(0,z) Relu(z)=max(0,z)
虽然在0点处不可导,但是公式简单,计算快。

三、TensorFlow高封装API实现MLP
import tensorflow as tf
#载入mnist手写数字数据
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
#把数据转换为一个n行,28*28列的数组,让每一个像素点代表一个特征
X_train = X_train.astype(np.float32).reshape(-1, 28*28) / 255.0
X_test = X_test.astype(np.float32).reshape(-1, 28*28) / 255.0
y_train = y_train.astype(np.int32)
y_test = y_test.astype(np.int32)
#取前5000个样本
X_valid, X_train = X_train[:5000], X_train[5000:]
y_valid, y_train = y_train[:5000], y_train[5000:]
feature_cols = [tf.feature_column.numeric_column("X", shape=[28 * 28])]
dnn_clf = tf.estimator.DNNClassifier(hidden_units=[300,100], n_classes=10,
feature_columns=feature_cols)
input_fn = tf.estimator.inputs.numpy_input_fn(
x={"X": X_train}, y=y_train, num_epochs=40, batch_size=50, shuffle=True)
dnn_clf.train(input_fn=input_fn)
四、TensorFlow直接搭建DNN
为了对DNN有更清楚的理解和更多的控制,我们依照上一章,自己来搭建一个DNN计算流程图:
n_inputs = 28*28 # MNIST
n_hidden1 = 300
n_hidden2 = 100
n_outputs = 10
reset_graph()
#X和Y设置为占位符,方便后续我们采用mini-batch梯度下降方法
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int32, shape=(None), name="y")
#这里我们自己定义一个生成中间层的函数
def neuron_layer(X, n_neurons, name, activation=None):
with tf.name_scope(name):
#获取输入数据X的第二维长度
n_inputs = int(X.get_shape()[1])
stddev = 2 / np.sqrt(n_inputs)
init = tf.truncated_normal((n_inputs, n_neurons), stddev=stddev)
#随机初始化W,W是一个n_inputs x n_neurons维的数组,代表每一个输入神经元和每一个下一层神经元之间的连接权重
#随机初始化的方式为在一个截断正态分布中随机取值,这样不会取到比较大的随机值(减缓训练速度)
W = tf.Variable(init, name="kernel")
b = tf.Variable(tf.zeros([n_neurons]), name="bias")
#计算该中间层的输出Z,Z会是一个n(X的第一维长度) x n_neurons维的数组
Z = tf.matmul(X, W) + b
if activation is not None:
return activation(Z)
else:
return Z
with tf.name_scope("dnn"):
#构造第一层隐层,激活函数选择Relu
hidden1 = neuron_layer(X, n_hidden1, name="hidden1",
activation=tf.nn.relu)
#构造第二层隐层,激活函数选择Relu
hidden2 = neuron_layer(hidden1, n_hidden2, name="hidden2",
activation=tf.nn.relu)
#构造输出层,不做激活函数处理
logits = neuron_layer(hidden2, n_outputs, name="outputs")
当然,这里我们自己定义搭建中间层的函数只是为了对DNN结构有个更清楚的理解,TensorFlow其实也对这样一个函数有封装tf.layers.dense,直接调用这个函数即可:
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, name="hidden1",
activation=tf.nn.relu)
hidden2 = tf.layers.dense(hidden1, n_hidden2, name="hidden2",
activation=tf.nn.relu)
logits = tf.layers.dense(hidden2, n_outputs, name="outputs")
下一步是要定义一个损失函数用来评估预测误差,并进行梯度下降,一般多分类我们都用交叉熵损失函数:
J
=
−
1
m
∑
i
=
1
m
∑
k
=
1
K
y
k
(
i
)
l
o
g
(
p
k
(
i
)
)
J = -\frac{1}{m}\sum_{i=1}^{m}\sum_{k=1}^{K}y_{k}^{(i)}log(p_{k}^{(i)})
J=−m1i=1∑mk=1∑Kyk(i)log(pk(i))
当第i个样本的分类为k时,
y
k
(
i
)
y_{k}^{(i)}
yk(i)等于1,否则为0。当只有两个类别时,交叉熵损失就是逻辑回归里面的logloss。
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y,logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
learning_rate = 0.01
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
在搭建流程图的最后一步,我们也需要指定如何评估这个模型的好坏,这里我们用正确率来评估,可以直接调用TensorFlow的in_top_k()函数,这个函数一个包含0-1的数组,表示最大的logit值是不是和标签相对应。
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
计算流程图阶段完成了,最后放到session里面用mini-batch方法逐步优化即可:
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_epochs = 40
batch_size = 50
def shuffle_batch(X, y, batch_size):
#对X的行序号进行随机排序
rnd_idx = np.random.permutation(len(X))
n_batches = len(X) // batch_size
#把随机排序的行序号均分成n_batches份,每次取一份batch_size大小的数据出来
for batch_idx in np.array_split(rnd_idx, n_batches):
X_batch, y_batch = X[batch_idx], y[batch_idx]
yield X_batch, y_batch
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for X_batch, y_batch in shuffle_batch(X_train, y_train, batch_size):
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
acc_batch = accuracy.eval(feed_dict={X: X_batch, y: y_batch})
acc_val = accuracy.eval(feed_dict={X: X_valid, y: y_valid})
print(epoch, "Batch accuracy:", acc_batch, "Val accuracy:", acc_val)
save_path = saver.save(sess, "./my_model_final.ckpt")
最后,使用训练好的模型进行预测:
with tf.Session() as sess:
saver.restore(sess, "./my_model_final.ckpt") # or better, use save_path
X_new_scaled = X_test[:20]
Z = logits.eval(feed_dict={X: X_new_scaled})
y_pred = np.argmax(Z, axis=1)
五、DNN的调参
- 中间层层数
对于很多问题,只用1-2层隐层都能够达到不错的效果(比如MNIST数据只用1层几百个神经元的中间层DNN就可以达到97%以上的准确率),但比较深的DNN结构训练起来更高效,同样解决比较复杂的问题,深度的DNN虽然中间层数增加了,但是需要的神经元个数却比浅的DNN呈指数级减少。
实际训练中我们可以从1-2层中间层开始训练,逐渐增加中间层的数量,直至开始过拟合时停止。另外,对于很多复杂问题,我们没有必要从头开始训练,往往可以复用解决过类似问题,提前训练过的模型的前几层,在此基础上进行训练。 - 每层的神经元个数
每个中间层的神经元个数可以不一样,但我们也可以人为地把它们都定为一样的值,这样可以相应减少超参的个数。
实际操作中,我们可以一上来就选用一个比较深的网络和比较多的神经元,然后使用early_stopping和随机失活方法来控制过拟合。这样的方法被称为“紧身裤”方法,即不必花费时间去选一个合适的裤子,直接选个大的,然后让它收缩到合适尺寸。 - 激活函数
大部分情况下,激活函数选用Relu或它的变种Leaky-Relu,因为它的计算比其它几种更快(不涉及指数运算),而且不存在梯度平原的问题(像sigmoid函数在除0附近的地方上梯度都非常小,会导致梯度下降很慢)。















 13万+
13万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









