







 本文介绍了基尼系数的概念,由意大利经济学家基尼提出,用于衡量收入分配不平等。基尼系数的范围在0到1之间,数值越小表示分配越平等。文章通过公式法和洛伦茨曲线两种方法计算了美国2008年的基尼系数,并展示了如何使用Python进行计算。同时,文中探讨了列表推导式和条件赋值在编程中的应用。
本文介绍了基尼系数的概念,由意大利经济学家基尼提出,用于衡量收入分配不平等。基尼系数的范围在0到1之间,数值越小表示分配越平等。文章通过公式法和洛伦茨曲线两种方法计算了美国2008年的基尼系数,并展示了如何使用Python进行计算。同时,文中探讨了列表推导式和条件赋值在编程中的应用。
前些天听了南京大学周耿老师关于“基尼系数计算”的直播课,需要时间好好消化,便有了整理此篇文章的想法。
1 基尼系数
1.1 简介
1912年意大利经济学家基尼,设计了一个测度社会贫富差距的方法沿用至今,成为国际通用的标准。
基尼系数最大为“1”,最小等于“0”。基尼系数越接近0表明收入分配越是趋向平等。国际上并没有一个组织或教科书给出最适合的基尼系数标准。但有不少人认为基尼系数小于0.2时,居民收入过于平均,0.2-0.3之间时较为平均,0.3-0.4之间时比较合理,0.4-0.5时差距过大,大于0.5时差距悬殊。
世界部分国家基尼系数排行1970-2019
1.2 定义
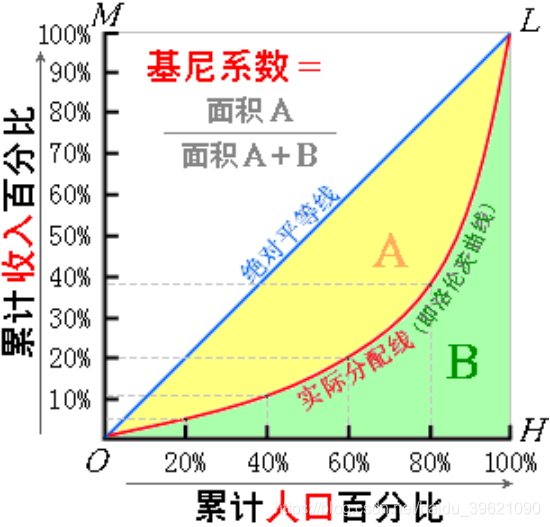
基尼系数有好几种定义方式,老师在课上公式法中运用的是下面第二张图中的公式,还有其他的一些公式,感兴趣的也可以自己通过代码实现,用来对比不同算法之间的差异。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-F2mfW2uU-1625838881521)(【0701】python基尼系数计算实践(案例+代码).assets/image-20210709205553354.png)]](https://i-blog.csdnimg.cn/blog_migrate/f930fcc3014fc1b991ec8da8f49c9db5.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1YZG6aNE-1625838881541)(【0701】python基尼系数计算实践(案例+代码).assets/image-20210709205651303.png)]](https://i-blog.csdnimg.cn/blog_migrate/246bd49d72c135c40331b0c0bb1c7260.png)
2 实践
2.1 公式法
G = ∑ i = 1 n ∑ j = 1 n ∣ x i − x j ∣ 2 ∑ i = 1 n ∑ j = 1 n x j = ∑ i = 1 n ∑ j = 1 n ∣ x i − x j ∣ 2 n ∑ i = 1 n x i G=\frac{\sum_{i=1}^{n} \sum_{j=1}^{n}\left|x_{i}-x_{j}\right|}{2 \sum_{i=1}^{n} \sum_{j=1}^{n} x_{j}}=\frac{\sum_{i=1}^{n} \sum_{j=1}^{n}\left|x_{i}-x_{j}\right|}{2 n \sum_{i=1}^{n} x_{i}} G=2∑i=1n∑j=1nxj∑i=1n∑j=1n∣xi−xj∣=2n∑i=1nxi∑i=1n∑j=1n∣xi−xj∣
代码如下:
def gini(L):
s1=0 #分子
s2=0 #分母
for i in L:
s2+=2*len(L)*i
for j in L:
s1+=abs(i-j)
return s1/s2
gini(r) # 这里的r是老师通过random模块paretovar()方法构造的帕累托分布,大家也可以自己生成数据测试代码效果
我们同样用美国2008年收入数据来检验下公式法。
代码如下:
#生成列表,带入函数计算
df=pd.read_csv('usa_income.csv')
L=[]
for i in df.index:
L=L+[ df.loc[i,'income'] for j in range(int(df.loc[i,'people']/10000))] #列表推导式
gini(L)
# out:0.5979213459691597
2.2 估算美国2008年基尼系数
2.2.1 读取数据并计算
代码如下:
#读取数据
df=pd.read_csv('usa_income.csv')
df['all_income']=df['people']*df['income']
df['people_cum']=df['people'].cumsum()
df['people_ratio']=df['people']/df['people'].sum()*100
df['people_ratio_cum']=df['people_cum']/df['people_cum'].max()*100
df['all_income_cum']=df['all_income'].cumsum()
df['Lorenz curve']=df['all_income_cum']/df['all_income_cum'].max()*100 #洛伦茨曲线
df
效果如图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7dN2u6uv-1625838881543)(【0701】python基尼系数计算实践(案例+代码).assets/image-20210709212335453.png)]](https://i-blog.csdnimg.cn/blog_migrate/7288b5851adf18b006ec0cc2d28ad0a3.png)
2.2.2 画洛伦兹曲线
代码如下:
df['avg']=df['people_ratio_cum'] #绝对平均线
df.plot(x='people_ratio_cum', y=['Lorenz curve','avg']) #画图
效果如图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ULIpAvvZ-1625838881548)(【0701】python基尼系数计算实践(案例+代码).assets/image-20210709213234571.png)]](https://i-blog.csdnimg.cn/blog_migrate/dcb946ab138d397a096514630b4a60c8.png)
2.2.3 按图形面积计算
#面积A+B=100*100*0.5=5000
#面积B
s=0
for i in df.index[1:]:
people1=df.loc[i-1,'Lorenz curve'] #梯形的下底
people2=df.loc[i,'Lorenz curve'] #梯形的上底
people_ratio=df.loc[i,'people_ratio']
s+=(people1+people2)*people_ratio*0.5
Gini=round((100*100*0.5-s)/(100*100*0.5),8) # 三角形的面积好求,洛伦兹曲线计算需要思考
Gini # 计算结果为:0.60257495
不难发现,公式法与面积法计算结果还是比较接近的。
3 列表推导式与条件赋值
学习pandas,列表推导式最好一并掌握。
在生成一个数字序列的时候,在 Python 中可以如下写出:
L = []
def my_func(x):
return 2*x
for i in range(5):
L.append(my_func(i))
L
# Out: [0, 2, 4, 6, 8]
事实上可以利用列表推导式进行写法上的简化: [* for i in *] 。其中,第一个 * 为映射函数,其输入为后面 i 指代的内容,第二个 * 表示迭代的对象。
[my_func(i) for i in range(5)]
# Out:[0, 2, 4, 6, 8]
列表表达式还支持多层嵌套,如下面的例子中第一个 for 为外层循环,第二个为内层循环:
[m+'_'+n for m in ['a', 'b'] for n in ['c', 'd']]
# out:['a_c', 'a_d', 'b_c', 'b_d']
除了列表推导式,另一个实用的语法糖是带有 if 选择的条件赋值,其形式为 value = a if condition else b :
value = 'cat' if 2>1 else 'dog'
value
# out: 'cat'
等价于如下的写法:
a, b = 'cat', 'dog'
condition = 2 > 1 # 此时为True
if condition:
value = a
else:
value = b
下面举一个例子,截断列表中超过5的元素,即超过5的用5代替,小于5的保留原来的值:
L = [1, 2, 3, 4, 5, 6, 7]
[i if i <= 5 else 5 for i in L]
# out:[1, 2, 3, 4, 5, 5, 5]
References
How Has the Literature on Gini’s IndexEvolved in the Past 80 Years?



















 1419
1419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











