






记得刚开始做需要持久化数据的服务器端应用时,当时的我并不理解数据库有什么特别。为什么数据库那么重要?难道就不能直接把数据存储在磁盘上,需要时再读写吗?(剧透:当然不能!)
但当我开始处理实际业务应用而不仅仅是出于爱好做项目时,我终于意识到数据库其实是魔法,SQL 是施展魔法的咒语。我们可以简单地把数据库看作黑盒子,只要确保表索引合理,查询没有问题,剩下的数据库会自动处理。
实际上,数据库并没有那么复杂。我想说的是,虽然某种层面上看,数据库是复杂的,但如果深入了解数据库引擎后,你会发现数据库只是一种非常强大且聪明的抽象。而且,和大多数软件一样,数据库实际的复杂性大多来自于边界情况,特别是有关并发处理的。
我想通过生动的介绍,向熟悉关系型数据库但不清楚其内部运作的开发者揭示数据库引擎的奥秘。这篇文章将以我最熟悉的 PostgreSQL 为例。而且,Stack Overflow 在 2023 和 2024 年发布的开发者调研结果显示,PostgreSQL 也是开发者最常用的数据库。
首先,我会讨论 Postgres 如何在磁盘上存储数据。毕竟,这不就是一些文件吗?
从 Postgres 安装开始
Postgres 将所有数据存储在名为 /var/lib/postgresql/data的目录中。
首先,使用 Docker 创建空的 Postgres 安装容器,并将数据目录挂载到本地文件夹,方便后续查看。你也可以跟着一起操作,自己探索这些文件!
docker run --rm -v ./pg-data:/var/lib/postgresql/data -e POSTGRES_PASSWORD=password postgres:16
执行后,你会看到很多有趣的输出内容,比如 selecting dynamic shared memory implementation ... posix 和 performing post-bootstrap initialization ... ok,最终日志显示 LOG: database system is ready to accept connections。看到这条提示后,就可以用 Ctrl-C 终止服务器,查看已创建的文件。
$ ls -l pg-data
drwx------ - base/
drwx------ - global/
drwx------ - pg_commit_ts/
drwx------ - pg_dynshmem/
.rw-------@ 5.7k pg_hba.conf
.rw-------@ 2.6k pg_ident.conf
drwx------ - pg_logical/
drwx------ - pg_multixact/
drwx------ - pg_notify/
drwx------ - pg_replslot/
drwx------ - pg_serial/
drwx------ - pg_snapshots/
drwx------ - pg_stat/
drwx------ - pg_stat_tmp/
drwx------ - pg_subtrans/
drwx------ - pg_tblspc/
drwx------ - pg_twophase/
.rw------- 3 PG_VERSION
drwx------ - pg_wal/
drwx------ - pg_xact/
.rw-------@ 88 postgresql.auto.conf
.rw-------@ 30k postgresql.conf
.rw------- 36 postmaster.opts
这里列出了很多文件夹,但大多数是空的。
在我们深入探讨之前,可以先快速了解一下数据库相关术语:
| 术语 | 定义 |
|---|---|
| 数据库集群 | 这里的“集群”有些不恰当——我们这篇文章所说的集群与 Postgres 官方文档中的表述相同,指的是在同一台机器上运行多个数据库的 PostgreSQL 服务器实例(每个数据库都是通过 create database mydbname 创建的)。 |
| 数据库连接 | 当客户端连接到 Postgres 服务器时,会启动一个数据库连接。这时,Postgres 会在服务器上创建一个子进程。 |
| 数据库会话 | 连接通过认证后,客户端就建立了一个会话,之后可以用这个会话来执行 SQL 语句。 |
| 交易,即 tx,xact | 在事务会话中执行 SQL,事务是指执行、提交并成功完成的或作为单元任务执行失败的工作单位。如果事务失败,则会回滚,事务中所做的所有更改都会被撤销。 |
| 快照 | 每个事务都会有自己的数据库副本,称为快照。如果有多个会话同时读取和写入相同的数据,它们通常不会看到完全相同的数据,而是会根据事务的具体时间点看到不同的快照。支持同步和导出快照。 |
| 模式 | 一个数据库由多个模式(schemas 或 schemata)组成,每个模式都是表、函数、触发器和数据库存储的所有内容的逻辑命名空间。默认的模式叫做 public,如果你不指定,就相当于手动指定为 public。 |
| 表 | 一个数据库由多个表组成,每个表表示一个无序的 items 集合,具有特定数量的列,每列都是特定类型。 |
| 表空间 | 表空间是一种物理分隔(与 schema 不同,schema 是逻辑分隔)。稍后我们会详细讨论表空间。 |
| 行 | 一个表由多行无序的行组成,每行都是定义特定事物的数据点集合。 |
| 元组 | 元组与行非常相似,但元组是不可变的。特定时间点特定行的状态是一个元组,元组是指数据点集合的更通用术语。当从查询中返回数据时,你可以得到元组。 |
然后我们再快速过一下这些顶层文件和文件夹的用途。你无需知道每一个文件的用途,因为大多数文件夹都是用于更复杂的场景,所以我们这里看到的文件夹是空的。不过了解每份文件和文件夹的用途还是很有趣的。
| 目录 | 说明 |
|---|---|
| base/ | 包含每个数据库的子目录。在每个子目录中,都包含带有实际数据的文件。这点我们稍后会深入讨论。 |
| global/ | 直接包含集群范围内的表格文件,例如 pg_database。 |
| pg_commit_ts/ | 正如其名称中的缩写所表示的,pg_commit_ts/ 包含事务提交的时间戳。不过我们现在还没有任何提交或事务,所以这个目录是空的。 |
| pg_dynshmem/ | Postgres 使用多个进程(不是多个线程)。为了在进程之间共享内存,Postgres 有一个动态共享内存子系统。它可以在 Linux 上使用 shm_open、shmget 或 mmap 来实现,默认使用 shm_open。共享内存对象文件存储在这个文件夹中。 |
| pg_hba.conf | 基于主机的身份验证(Host-Based Authentication,HBA)文件,允许用户根据主机名配置集群的访问权限。例如,默认情况下这个文件设置了 host all all 127.0.0.1/32 trust,这意味着“如果用户从本地机器连接,则无需密码即可连接任何数据库”。如果你曾有为什么当 psql 与服务器运行在同一台机器上时不需要输入密码的疑问,这就是其背后的原因。 |
| pg_ident.conf | 用户名映射文件。 |
| pg_logical/ | 包含逻辑解码的状态数据。受篇幅限制,这里我们暂不能完整地讨论 Write-Ahead Log(WAL)的工作原理,但简单来说,Postgres 会先将要执行的更改写入 WAL,然后如果 Postgres 崩了,它可以重新读取并运行 WAL 中的所有操作来恢复到预期的数据库状态。将 WAL 出于恢复、复制或审计的目的,转换回高级操作的过程,称为逻辑解码,Postgres 将与这个过程相关的文件存储在这里。 |
| pg_multixact/ | Postgres 把“xact”称为事务,所以这个目录包含多事务的状态数据。多事务是在多个会话都试图对同一行进行行级锁定时发生的一种情况。 |
| pg_notify/ | 在 Postgres 中,用户可以监听频道上的变化并将变化内容通知到监听者。如果你的应用程序想要在特定事件发生时采取措施,pg_notify 将在此时发挥作用。例如,如果你的应用程序想要在特定表中每添加或更新一行时收到通知,并与外部系统同步,你可以设置一个触发器。每当表有变化时,它会通知所有的监听者。你的应用程序也可以监听这个通知,并按照自己的方式更新外部数据存储。 |
| pg_replslot/ | 复制是指数据库可以在多个运行的服务器实例之间同步。例如,如果你有一些非常重要的数据,为了避免丢失,可以设置多个副本,这样即使你的主数据库宕机并且丢失所有数据,你也可以从其中一个副本中恢复数据。复制可以是物理复制(直接复制磁盘文件)和逻辑复制(基本上是将 WAL 复制到所有副本,以便通过逻辑解码从副本的 WAL 重建主数据库)。这个目录包含各种复制槽的数据,复制槽是确保即使不再需要主数据库,也会保留 WAL items,以供特定副本使用的一种方式。 |
| pg_serial/ | 包含已提交的可串行化事务的信息。可串行化事务是事务隔离级别中最严格的一种。 |
| pg_snapshots/ | 包含导出的快照,例如 pg_dump 可以并行转储数据库时使用的快照。 |
| pg_stat/ | Postgres 计算各种表的统计信息,用于通知合理的查询计划和计划执行。例如,如果查询规划器知道需要对表进行顺序扫描,它可以查看该表中大约有多少行,以确定应分配多少内存。该文件夹包含根据表计算的永久统计文件。了解统计信息对于分析和修复不良的查询性能非常重要。 |
| pg_stat_tmp/ | 与 pg_stat/ 类似,但这个目录包含与 Postgres 保存的统计信息相关的临时文件,而不是永久文件。 |
| pg_subtrans/ | 子事务是另一种类型的事务,类似于多事务。它们是将单个事务拆分成多个较小的子事务的一种方式,这个目录包含它们的状态数据。 |
| pg_tblspc/ | 包含对不同表空间的符号引用。表空间是一个物理位置,数据库管理员可以将数据库对象存储在这里。例如,如果你有一个频繁使用的索引,你可以使用表空间将该索引放在高速但同时价格也很高的固态驱动器上,而其余的表仍然存储在更便宜但速度更慢的磁盘上。 |
| pg_twophase/ | 可以“准备”事务,这意味着事务与当前会话分离,并存储在磁盘上。这一方式对于二阶段提交很有用,在二阶段提交中,用户一般希望同时将更改提交到多个系统,并确保两个事务要么都失败并回滚,要么都成功并提交。 |
| PG_VERSION | 它包含一个单一的数字,表示我们正在使用的 Postgres 的主版本号。对于本文,我们希望这个文件包含数字 16。 |
| pg_wal/ | 这里存储了预写式日志(Write-Ahead Log, WAL)文件。 |
| pg_xact/ | 包含事务提交的状态数据,即元数据日志。 |
| postgresql.auto.conf | 这个文件包含服务器配置参数,就像 postgresql.conf 一样,但是会被 alter system 命令自动写入。alter system 是一种 SQL 命令,可用于动态修改服务器参数。 |
| postgresql.conf | 这个文件包含可以为 Postgres 实例配置的所有可能的服务器参数。这些参数从 autovacuum_naptime 到 zero_damaged_pages 应有尽有。如果你想了解所有可能的 Postgres 服务器参数及其功能,我强烈建议你查看 postgresqlco.nf。 |
| postmaster.opts | 这个简单的文件包含上一次运行 Postgres 时使用的完整命令行命令。 |
还有一个叫 postmaster.pid 的文件,只有在 Postgres 进程运行时才会看到这个文件,它包含有关 postmaster 进程 ID、监听端口、启动时间等信息。这里我们停止了 Postgres 服务器,所以看不到它。
内容有些多但也很有趣,如果你没完全理解也没关系,接下来我们将要讨论实际的数据库存储,不需要完全掌握上述内容也可以理解。
探索数据库文件夹
我们提到过 base/ 目录,它包含集群中每个数据库的子目录。我们先来看看这里有什么:
$ ls -l pg-data/base
drwx------ - 1/
drwx------ - 4/
drwx------ - 5/
等等,为什么这里已经有 3 个文件夹?毕竟我们还没有创建任何数据库。
原因是,当启动一个新的 Postgres 服务器时,Postgres 会自动创建 3 个数据库。它们分别是:
postgres:连接到服务器时,需要数据库名称,但你可能不知道数据库名称具体是什么。其实数据库管理工具也不知道。虽然并非必要,但是可以依赖 postgres 数据库。如果连接到这个空的默认数据库,可以执行列出服务器上的所有其他数据库、创建新数据库等等操作。template0,template1:顾名思义,这些数据库是用于创建数据库的模板。
为什么子目录是数字而不是名字?
在 Postgres 中,所有系统表(如命名空间、角色、表和函数)都使用对象标识符(OID,Object IDentifier)来标识它们。在这种情况下,1、4 和 5 分别是 postgres、template0 和 template1 的 OID。
玩转数据
这些内置的表里没什么内容,一般都比较无趣,所以我们创建一个新数据库并加入数据,用来检查数据文件。
首先,运行并分离 Postgres 容器,方便查询。
docker run -d --rm -v ./pg-data:/var/lib/postgresql/data -e POSTGRES_PASSWORD=password postgres:16
我们可以使用任何数据作为数据集,我喜欢地理数据,所以我们创建一个包含一些国家信息的表。
首先将一些国家的数据下载到容器中并加载到新数据库中。
curl 'https://raw.githubusercontent.com/lukes/ISO-3166-Countries-with-Regional-Codes/master/all/all.csv' \
--output ./pg-data/countries.csv
我们可以使用本地工具如 psql 或 TablePlus 检查数据库,这里我将直接进入容器并使用容器内的 psql。这种方式可以避免端口映射或 psql 和 Postgres 服务器版本不匹配的问题。
pg_container_id=$(docker ps --filter expose=5432 --format "{{.ID}}")
docker exec -it $pg_container_id psql -U postgres
我们可以通过筛选暴露 5432 端口的容器来获取正在运行的 Postgres 容器 ID,并将获取的 ID 替换 docker exec 命令中 的 pg_container_id,执行后,可打开 psql shell 交互界面。这里使用 -U postgres 是因为官方 Docker 镜像中的默认 Postgres 用户是 postgres,而不是 psql 默认的 root 用户。
命令执行成功的话,可以看到类似如下的内容:
psql (16.3 (Debian 16.3-1.pgdg120+1))
Type "help" for help.
postgres=#
现在我们来创建新数据库并加载数据:
create database blogdb;
\c blogdb;
create table countries (
id integer primary key generated always as identity,
name text not null unique,
alpha_2 char(2) not null,
alpha_3 char(3) not null,
numeric_3 char(3) not null,
iso_3166_2 text not null,
region text,
sub_region text,
intermediate_region text,
region_code char(3),
sub_region_code char(3),
intermediate_region_code char(3)
);
copy countries (
name,
alpha_2,
alpha_3,
numeric_3,
iso_3166_2,
region,
sub_region,
intermediate_region,
region_code,
sub_region_code,
intermediate_region_code
)
from '/var/lib/postgresql/data/countries.csv'
delimiter ',' csv header;
-- Check that the data got loaded into the table ok.
select * from countries limit 10;
-- Should say 249.
select count(*) from countries;
数据导入成功后,就得到了一个 249 行的表,其索引与 name 列唯一性约束相对应。
查看文件
让我们再看一下 base/ 文件夹:
$ ls -l pg-data/base
drwx------ - 1/
drwx------ - 4/
drwx------ - 5/
drwx------ - 16388/
在这个例子中,很明显我们的 blogdb 是 16388,但如果你在同一个集群上处理大量数据库,blogdb 可能就无从知晓。如果你也在一起操作,可能值会不同。你可以通过以下命令找到:
postgres=# select oid, datname from pg_database;
oid | datname
-------+-----------
5 | postgres
16388 | blogdb
1 | template1
4 | template0
(4 rows)
让我们看看这个文件夹里有什么:
$ cd pg-data/base/16388
$ ls -l .
.rw------- 8.2k 112
.rw------- 8.2k 113
.rw------- 8.2k 174
.rw------- 8.2k 175
.rw------- 8.2k 548
.rw------- 8.2k 549
.rw------- 0 826
.rw------- 8.2k 827
.rw------- 8.2k 828
.rw------- 123k 1247
.rw------- 25k 1247_fsm
.rw------- 8.2k 1247_vm
.rw------- 475k 1249
.rw------- 25k 1249_fsm
...
.rw------- 25k 16390_fsm
.rw------- 0 16393
.rw------- 8.2k 16394
.rw------- 16k 16395
.rw------- 16k 16397
.rw------- 524 pg_filenode.map
.rw------- 160k pg_internal.init
.rw------- 3 PG_VERSION
$ ls -l | wc -l
306
$ du -h .
7.6M .
考虑到我们只有 249 行数据,但这里的输出结果却有惊人数量的文件。那么到底发生了什么?
我们可以通过系统目录来解释这点:
-- First, let's get the OID of the 'public' namespace that our table lives in - you need
-- to run this in the 'blogdb' database, otherwise you'll get the OID of the 'public'
-- namespace for the database you're currently connected to.
blogdb=# select to_regnamespace('public')::oid;
to_regnamespace
-----------------
2200
(1 row)
-- Now let's list all the tables, indexes, etc. that live in this namespace.
blogdb=# select * from pg_class
blogdb-# where relnamespace = to_regnamespace('public')::oid;
oid | relname | relnamespace | reltype | reloftype | relowner | relam | relfilenode | reltablespace | relpages | reltuples | relallvisible | reltoastrelid | relhasindex | relisshared | relpersistence | relkind | relnatts | relchecks | relhasrules | relhastriggers | relhassubclass | relrowsecurity | relforcerowsecurity | relispopulated | relreplident | relispartition | relrewrite | relfrozenxid | relminmxid | relacl | reloptions | relpartbound
-------+--------------------+--------------+---------+-----------+----------+-------+-------------+---------------+----------+-----------+---------------+---------------+-------------+-------------+----------------+---------+----------+-----------+-------------+----------------+----------------+----------------+---------------------+----------------+--------------+----------------+------------+--------------+------------+--------+------------+--------------
16389 | countries_id_seq | 2200 | 0 | 0 | 10 | 0 | 16389 | 0 | 1 | 1 | 0 | 0 | f | f | p | S | 3 | 0 | f | f | f | f | f | t | n | f | 0 | 0 | 0 | | |
16390 | countries | 2200 | 16392 | 0 | 10 | 2 | 16390 | 0 | 4 | 249 | 0 | 16393 | t | f | p | r | 12 | 0 | f | f | f | f | f | t | d | f | 0 | 743 | 1 | | |
16395 | countries_pkey | 2200 | 0 | 0 | 10 | 403 | 16395 | 0 | 2 | 249 | 0 | 0 | f | f | p | i | 1 | 0 | f | f | f | f | f | t | n | f | 0 | 0 | 0 | | |
16397 | countries_name_key | 2200 | 0 | 0 | 10 | 403 | 16397 | 0 | 2 | 249 | 0 | 0 | f | f | p | i | 1 | 0 | f | f | f | f | f | t | n | f | 0 | 0 | 0 | | |
(4 rows)
我们看到这里只有 4 个类似表的对象,这个文件夹里的其他文件都是样板文件。如果你查看 template0、template1 或 postgres(即 1/,2/,或 5/)的数据库文件夹,你会发现几乎所有文件都和我们的 blogdb 数据库完全一样。
那么这些 pg_class 对象是什么,它们和这些文件有什么关系?
我们可以看到 countries 表的 oid 和 relfilenode 值为 16390,这是实际表数据。还有 countries_pkey 的 oid 和 relfilenode 值为 16395 ——这是主键的索引。countries_name_key 为 16397 —— 这是 name 唯一约束的索引,最后是 countries_id_seq 为 16389,用于生成新 ID 值的序列。这里我们使用 primary key generated always as identity,就像 serial 一样按数值递增生成新值。
relfilenode 对应对象的“文件节点”,即磁盘上文件的名称。让我们从 countries 表开始。
$ ls -l 16390*
.rw-------@ 33k 16390
.rw-------@ 25k 16390_fsm
对于通用对象,你可能会看到三个或更多文件:
{filenode}– Postgres 将大对象拆分为多个称为段的文件,以避免某些操作系统处理大文件时出现问题(主要是历史原因导致的)。这些文件默认大小为 1 GB,且可配置。这是第一个段文件。{filenode}.1,{filenode}.2– 这是后续的段文件。我们的示例中还没有超过 1 GB 的数据,所以没有这些文件。{filenode}_fsm– 这是对象的空闲空间映射(FSM)文件,包含一个二叉树,会告诉你堆的每个页面有多少空闲空间。别担心,后面会解释什么是堆和页面。{filenode}_vm– 这是对象的可见性映射(VM)文件,告诉你页面中元组(tuples)的可见性。稍后我们会详细讨论这一点。
什么是堆?
所有这些主段数据文件(不包括 FSM 和 VM)都称为 堆(heap)。
对于表来说,一个非常重要但并不引人注目的事实是,即使表可能带有有序主键,但表也不是有序的。因此我们需要单独的序列对象生成顺序的 ID 值。因此,表有时被称为 a bag of rows,在 Postgres 中叫做 堆(heap)。对于任何被添加、更新和清理过的实际表,堆中的行不会按主键顺序排列。
重要的是,Postgres 中的堆与系统内存中的堆(与堆栈相对)并不相同。它们是相关概念,如果你熟悉内存中的堆与堆栈结构,你可能会发现下一节中的图很熟悉,但要记住它们是完全不同的概念。
对象堆由许多不同的页面(也称为块)顺序存储在文件中。
那么,什么是页面?
在一个段文件中,你会发现这是由多个固定大小的页面拼接在一起。默认情况下,一个页面的大小为 8 KB,所以我们可以得知所有对象文件都是 8 KB 的倍数。在这个例子中,表文件大小为 32 KB,这意味着其中有 4 个页面。
你可能会想为什么使用页面?为什么不是每个段只有一个页面?答案是每个页面以一个原子操作写入,页面越大,写入过程中出现写入失败的可能性越大。页面越大,数据库性能越好,但页面越大,写入失败的可能性也越大。Postgres 维护者选择 8 KB 作为默认值,他们很清楚自己在做什么,所以通常没有理由改变这个值。
这个图表显示了页面的结构,以及它与段和整个对象的关系。
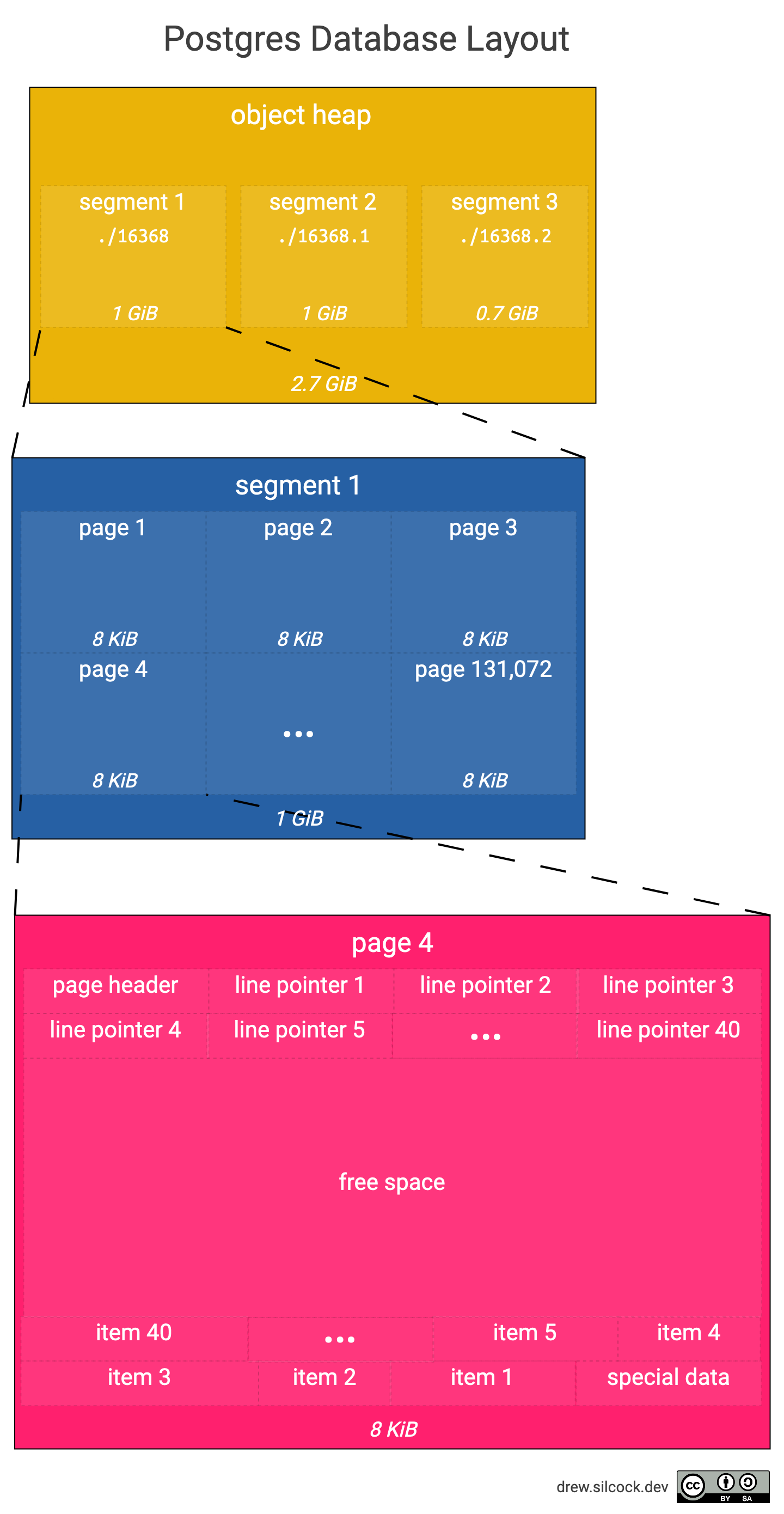
在我们的例子中,我们的主表为 2.7 GiB,需要 3 个 1 GiB 的独立段。每 1 GiB 中有 131,072 个大小为 8 KiB 的页面,每个页面大约包含 40 个 items(基于每个 item 占用约 200 字节)。
页面布局
接下来,我们深入了解下页面布局。
可以看到页面有三个区域:
- Page header 和 line pointer,它们的地址自低向高增长,这意味着 line pointer n+1 的初始偏移量比 line pointer n 高,最后一个 line pointer 的末端被称为“lower”。
- 特殊数据和 items 的地址自高向低增长,这意味着 item n+1 的初始偏移量比 item n 低,最后一个 item 的末端被称为“upper”。
- 空闲空间位于最后一个 line pointer 和最后一个 item 之间,即从“lower”到“upper”,您可以通过公式“upper” - “lower”来计算页面剩余的空闲空间。
Page header 本身包含以下内容:
- 页面校验和
- Line pointer 末端的偏移量(又称“lower”)
- 空闲空间末端的偏移量(即 item 的开始,又称“upper”)
- 特殊空间的起始偏移量
- 版本信息
实际上,有一个内置的扩展程序称为 pageinspect,我们可以使用它来查看 page header 信息:
blogdb=# create extension pageinspect;
CREATE EXTENSION
blogdb=# select * from page_header(get_raw_page('countries', 0));
lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid
-----------+----------+-------+-------+-------+---------+----------+---------+-----------
0/1983F70 | 0 | 0 | 292 | 376 | 8192 | 8192 | 4 | 0
(1 row)
blogdb=# select * from page_header(get_raw_page('countries', 1));
lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid
-----------+----------+-------+-------+-------+---------+----------+---------+-----------
0/19858E0 | 0 | 0 | 308 | 408 | 8192 | 8192 | 4 | 0
(1 row)
blogdb=# select * from page_header(get_raw_page('countries', 2));
lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid
-----------+----------+-------+-------+-------+---------+----------+---------+-----------
0/1987278 | 0 | 0 | 296 | 416 | 8192 | 8192 | 4 | 0
(1 row)
blogdb=# select * from page_header(get_raw_page('countries', 3));
lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid
-----------+----------+-------+-------+-------+---------+----------+---------+-----------
0/19882C8 | 0 | 0 | 196 | 3288 | 8192 | 8192 | 4 | 0
(1 row)
您可能首先注意到的是,special 与 pagesize 相同,这只是表明此页面没有特殊数据部分。特殊数据部分仅用于其他类型的页面,如索引,存储二叉树结构的信息。
您可能想知道为什么所有 checksum 值都为 0。事实证明,Postgres 出于性能考虑,默认情况下会禁用校验和保护,您必须手动启用它。
如果我们比较这些页面的 lower 和 upper 值,我们可以看到:
- 页面 0 有 376 - 292 = 84 字节的空闲空间
- 页面 1 有 408 - 308 = 100 字节的空闲空间
- 页面 2 有 416 - 296 = 120 字节的空闲空间
- 页面 3 有 3288 - 196 = 3092 字节的空闲空间
据此,我们可以推断:
- countries 表中的行大小约为 100 字节,因为这就是完整页面中剩余的空间。
- 页面 3 是最后一个页面,因为其中还有大量空间剩余。
我们可以使用 pageinspect 中的 heap_page_items() 函数来确认行大小:
blogdb=# select lp, lp_off, lp_len, t_ctid, t_data
blogdb-# from heap_page_items(get_raw_page('countries', 1))
blogdb-# limit 10;
lp | lp_off | lp_len | t_ctid | t_data
----+--------+--------+--------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1 | 8064 | 123 | (1,1) | \x440000002545717561746f7269616c204775696e656107475109474e51093232361d49534f20333136362d323a47510f416672696361275375622d5361686172616e204166726963611d4d6964646c6520416672696361093030320932303209303137
2 | 7944 | 114 | (1,2) | \x45000000114572697472656107455209455249093233321d49534f20333136362d323a45520f416672696361275375622d5361686172616e204166726963611f4561737465726e20416672696361093030320932303209303134
3 | 7840 | 97 | (1,3) | \x46000000114573746f6e696107454509455354093233331d49534f20333136362d323a45450f4575726f7065214e6f72746865726e204575726f706503093135300931353409202020
4 | 7720 | 116 | (1,4) | \x47000000134573776174696e6907535a0953575a093734381d49534f20333136362d323a535a0f416672696361275375622d5361686172616e2041667269636121536f75746865726e20416672696361093030320932303209303138
5 | 7600 | 115 | (1,5) | \x4800000013457468696f70696107455409455448093233311d49534f20333136362d323a45540f416672696361275375622d5361686172616e204166726963611f4561737465726e20416672696361093030320932303209303134
6 | 7448 | 148 | (1,6) | \x490000003946616c6b6c616e642049736c616e647320284d616c76696e61732907464b09464c4b093233381d49534f20333136362d323a464b13416d657269636173414c6174696e20416d657269636120616e64207468652043617269626265616e1d536f75746820416d6572696361093031390934313909303035
7 | 7344 | 103 | (1,7) | \x4a0000001d4661726f652049736c616e647307464f0946524f093233341d49534f20333136362d323a464f0f4575726f7065214e6f72746865726e204575726f706503093135300931353409202020
8 | 7248 | 89 | (1,8) | \x4b0000000b46696a6907464a09464a49093234321d49534f20333136362d323a464a114f6365616e6961154d656c616e6573696103093030390930353409202020
9 | 7144 | 97 | (1,9) | \x4c0000001146696e6c616e640746490946494e093234361d49534f20333136362d323a46490f4575726f7065214e6f72746865726e204575726f706503093135300931353409202020
10 | 7048 | 95 | (1,10) | \x4d0000000f4672616e636507465209465241093235301d49534f20333136362d323a46520f4575726f70651f5765737465726e204575726f706503093135300931353509202020
(10 rows)
这里 lp 表示 line pointer,lp_off 表示 item 开始的偏移量,lp_len 是 item 的大小(以字节为单位),t_ctid 指的是 item 的 ctid。ctid(Current Tuple ID)展示了 item 的位置,格式为(page index, item index within page),所以 (1, 1) 表示页面 1 中的第一个 item(页面从 0 开始,item 索引却并非如此)。
我们还可以看到 item 的实际数据:这个很长的十六进制字符串就是 Postgres 存储在磁盘上的字节。让我们用 Python 检查一下我们正在查看哪一行:
$ row_data=$(docker exec $pg_container_id psql -U postgres blogdb --tuples-only -c "select t_data from heap_page_items(get_raw_page('countries', 1)) limit 1;")
$ python3 -c "print(bytearray.fromhex(r'$row_data'.strip().replace('\\\\x', '')).decode('utf-8', errors='ignore'))" > row_data.bin
$ cat row_data.bin
D%Equatorial GuineaGQ GNQ 226ISO 3166-2:GQAfrica'Sub-Saharan AfricaMiddle Africa 002 202 017
$ hexyl row_data.bin
┌────────┬─────────────────────────┬─────────────────────────┬────────┬────────┐
│00000000│ 44 00 00 00 25 45 71 75 ┊ 61 74 6f 72 69 61 6c 20 │D⋄⋄⋄%Equ┊atorial │
│00000010│ 47 75 69 6e 65 61 07 47 ┊ 51 09 47 4e 51 09 32 32 │Guinea•G┊Q_GNQ_22│
│00000020│ 36 1d 49 53 4f 20 33 31 ┊ 36 36 2d 32 3a 47 51 0f │6•ISO 31┊66-2:GQ•│
│00000030│ 41 66 72 69 63 61 27 53 ┊ 75 62 2d 53 61 68 61 72 │Africa'S┊ub-Sahar│
│00000040│ 61 6e 20 41 66 72 69 63 ┊ 61 1d 4d 69 64 64 6c 65 │an Afric┊a•Middle│
│00000050│ 20 41 66 72 69 63 61 09 ┊ 30 30 32 09 32 30 32 09 │ Africa_┊002_202_│
│00000060│ 30 31 37 0a ┊ │017_ ┊ │
└────────┴─────────────────────────┴─────────────────────────┴────────┴────────┘
$ docker exec $pg_container_id psql -U postgres blogdb -c "select * from countries where name = 'Equatorial Guinea';"
ctid | id | name | alpha_2 | alpha_3 | numeric_3 | iso_3166_2 | region | sub_region | intermediate_region | region_code | sub_region_code | intermediate_region_code
-------+----+-------------------+---------+---------+-----------+---------------+--------+--------------------+---------------------+-------------+-----------------+--------------------------
(1,1) | 68 | Equatorial Guinea | GQ | GNQ | 226 | ISO 3166-2:GQ | Africa | Sub-Saharan Africa | Middle Africa | 002 | 202 | 017
(1 row)
我们正在查看赤道几内亚的数据,这是非洲大陆上唯一以西班牙语为官方语言的国家。如果您想知道为什么 (1,1) 不是 ID 为 1 的阿富汗,记住页面是从 0 开始的,阿富汗在 (0,1)。
我们可以看到,每个列都是紧挨着存储的,中间有一个随机字节。让我们深入研究一下:
0x 44 00 00 00=68(必须是小端序),所以前 4 个字节是行 ID。- 然后是一个随机字节,如
0x25或0x07,之后是列数据,其余列都是字符串类型,所以它们都以 UTF-8 编码存储。
单个值如果因为太大而无法在此处(例如,大于 8 KiB),则会存储在一个单独的关系中。
当一行数据被修改或删除时会发生什么?
Postgres 使用 MVCC(多版本并发控制)来处理对数据的并发访问。“多版本”意味着当一个事务到来并修改一行时,它完全不触碰磁盘上现有的元组。相反,它会在最后一页的末尾创建一个新的元组,并包含修改后的行。当它提交更新时,它将新事务所看到的数据版本从旧元组(tuple)切换到新元组。
我们来看看这个过程:
blogdb=# select ctid from countries where name = 'Antarctica';
ctid
-------
(0,9)
(1 row)
blogdb=# update countries set region = 'The South Pole' where name = 'Antarctica';
UPDATE 1
blogdb=# select ctid from countries where name = 'Antarctica';
ctid
--------
(3,44)
(1 row)
blogdb=# select lp, lp_off, lp_len, t_ctid, t_data
blogdb-# from heap_page_items(get_raw_page('countries', 0))
blogdb-# offset 8 limit 1;
lp | lp_off | lp_len | t_ctid | t_data
----+--------+--------+--------+--------
9 | 0 | 0 | |
(1 row)
可以看到,一旦更新行,它的 ctid 从 (0,9) 变为 (3,44)(这可能位于最后一页的末尾)。旧数据和 ctid 也从旧项位置中清除。
删除情况如何?可执行以下命令来查看:
blogdb=# delete from countries where name = 'Equatorial Guinea';
DELETE 1
blogdb=# select lp, lp_off, lp_len, t_ctid, t_data
blogdb-# from heap_page_items(get_raw_page('countries', 1))
blogdb-# limit 1;
lp | lp_off | lp_len | t_ctid | t_data
----+--------+--------+--------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1 | 8064 | 123 | (1,1) | \x440000002545717561746f7269616c204775696e656107475109474e51093232361d49534f20333136362d323a47510f416672696361275375622d5361686172616e204166726963611d4d6964646c6520416672696361093030320932303209303137
(1 row)
数据仍然存在。这是因为 Postgres 不会真正删除数据,而是将数据标记为已删除。但你可能会想,如果行不断被删除和添加,就会产生不断增加的包含已删除数据的段文件(在 Postgres 术语中称为“dead tuples”)。这就是清理(vacuuming)发挥作用的地方。我们再触发一次手动清理,看看会发生什么。
blogdb=# vacuum full;
VACUUM
blogdb=# select lp, lp_off, lp_len, t_ctid, t_data
blogdb-# from heap_page_items(get_raw_page('countries', 1))
blogdb-# limit 1; -- This used to be the dead tuple where 'Equatorial Guinea' was.
lp | lp_off | lp_len | t_ctid | t_data
----+--------+--------+--------+------------------------------------------------------------------------------------------------------------------------------------------------------
1 | 8088 | 97 | (1,1) | \x46000000114573746f6e696107454509455354093233331d49534f20333136362d323a45450f4575726f7065214e6f72746865726e204575726f706503093135300931353409202020
(1 row)
blogdb=# select lp, lp_off, lp_len, t_ctid, t_data
blogdb-# from heap_page_items(get_raw_page('countries', 0))
blogdb-# offset 8 limit 1; -- This used to be the dead tuple where the old 'Antarctica' version was.
lp | lp_off | lp_len | t_ctid | t_data
----+--------+--------+--------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
9 | 7192 | 136 | (0,9) | \x0a00000029416e746967756120616e64204261726275646107414709415447093032381d49534f20333136362d323a414713416d657269636173414c6174696e20416d657269636120616e64207468652043617269626265616e1543617269626265616e093031390934313909303239
(1 row)
blogdb=# select ctid, name from countries
blogdb-# where name = 'Antarctica' or ctid = '(0,9)' or ctid = '(1,1)';
ctid | name
--------+---------------------
(0,9) | Antigua and Barbuda
(1,1) | Estonia
(3,42) | Antarctica
(3 rows)
现在表数据已经清理过了,发生了几件事:
- 第一版本中南极洲所处的 dead tuple 的位置现在被安提瓜和巴布达替代。
- 位于赤道几内亚行的 dead tuple 现在被爱沙尼亚替代。
- 南极洲的 ctid 从
(3,44)移动到(3,42),因为前面有两个 dead tuples 已被清理,南极洲行可以向下移动两个位置。
那么索引呢?
索引和表的工作方式完全一样。唯一的区别是,存储在每个页面的元组包含索引数据,而不是完整的行数据,同时特殊数据包含二叉树的兄弟节点信息。
给读者的练习:找到 name 列的唯一索引的段文件,并研究每个页面中的 t_data 和“特殊数据”的值。
为什么需要了解这些?
有几个原因:
- 当然是因为这很有趣!
- 它有助于理解 Postgres 如何在磁盘上查询你的数据,MVCC 如何工作,以及其他很多对于深入了解数据库工作原理和优化性能很有用的知识。
- 在某些罕见情况下,了解数据库存储和索引在数据恢复中很有用,比如以下场景:
- 有人由于缺乏相关知识或出于恶意,决定通过删除或损坏几个磁盘文件,破坏你的数据库。Postgres 则无法再读取这个数据库,所以启动 Postgres 只会导致数据库状态损坏。你可以运用知识手动恢复数据,不过这仍然是一项相当大的工程。在现实场景中,你可能需要找专业的数据恢复专家。但在文章中的假设场景中,你的公司可能负担不起这样的支出,所以你不得不自己动手恢复。
- 有人不小心将生产数据库上的超级重要的客户表设置为 不记录日志(unlogged),然后服务器崩溃了。因为在 unlogged 表中,变更不会写入 WAL,使用逻辑复制无法恢复任何 unlogged 表的数据。如果重启服务器,Postgres 会将整个 unlogged 表清空,因为 Postgres 会从 WAL 还原数据库状态。但是,如果你复制出原始的数据库文件,你就可以利用从这篇文章中学到的知识来恢复数据内容。(可能已经有工具能做到这一点,但如果没有,你也可以自己编写一个,这也将是个有趣的项目…)
- 这是一个在聚会上搭讪的好话题。
延伸阅读
- Ketan Singh: How Postgres Stores Rows
- PostgreSQL Documentation – Chapter 73. Database Physical Storage
- Advanced SQL (Summer 2020), U Tübingen – DB2 — Chapter 03 — Video #09 — Row storage in PostgreSQL, heap file page layout
- 15-445/645 Intro to Database Systems (Fall 2019), Carnegie Mellon University – 03 - Database Storage I
- Structure of Heap Table in PostgreSQL
- pgPedia – Data Directory
原文链接:https://drew.silcock.dev/blog/how-postgres-stores-data-on-disk/#user-content-fnref-1
End
KubeBlocks 已发布 v0.9.0!KubeBlocks v0.9.0 全面升级了 API,构建一个 Cluster 更像是在用 Component “搭积木”!新增 topologies 字段,支持多种部署形态。InstanceSet 代替了 StatefulSet 来管理 Pods,支持将指定的 Pod 下线、Pod 原地更新,同时也支持数据库主从架构里主库和从库采用不同的 Pod spec。v0.9.0 还新增了 Reids 集群模式(分片模式),系统的容量、性能以及可用性显著提升!还支持了 MySQL 主备,资源的要求更少,数据复制的开销也更小!快来试试看!
小猿姐诚邀各位体验 KubeBlocks,也欢迎您成为产品的使用者和项目的贡献者。跟我们一起构建云原生数据基础设施吧!
💻 官网: www.kubeblocks.io
🌟 GitHub: https://github.com/apecloud/kubeblocks
🚀 Get started: https://cn.kubeblocks.io/docs/preview/user-docs/try-out-on-playground/try-kubeblocks-on-local-host
☁️ Cloud 试用:https://console.apecloud.cn/
关注小猿姐,一起学习更多云原生技术干货。















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









