






决策树
-
机器学习中分类和预测算法的评估
- 准确率
- 速度
- 强壮性
- 可规模性
- 可解释性
-
决策树/判定数
- 类似于流程图的树结构:内部节点表示属性上的测试,每一个分支表示属性输出,树叶节点代表类或类分布


从上图可见,第一层根据天气分类
分类时需要设置阈值
Play 和 Don’t Play 表示是否游玩,共14个例子
最终把某一类变成全部Play或Don’t Play
- 熵(entropy)
- 信息量的度量等于不确定性的多少:越不确定的事情所需的信息量越大
- 使用bit(值为0/1)来衡量信息的多少
- 变量的不确定性越大,熵越大

上图为信息量/熵的计算公式
H(X)表示信息量
P(X)表示概率
决策树归纳算法
- ID3算法
- 选择属性判断节点
- 信息获取量(information gain):Gain(A) = Info(D) - Info_A(D)
- Gain(A) 表示A的信息获取量
- Info(D) 表示数据集中没有A的信息量
- Info_A(D) 根据A分类后的信息量

buys_compouter 表示是否买电脑 no不买 yes 买
得到信息量/熵 Info(D) = 0.74 bits
若A表示年龄,则 Info_A(D) 为 中年信息熵 + 青年信息熵 + 老年信息熵之和
及算法得到 Info_A(D) = 0.694
最后得到Gain(A) = 0.984 - 0.694 = 0.246
对比其他属性的信息获取量,Age属性的信息获取量最高,因此将Age最为第一节点分类

通过age分类,得到上述图片
重复上述的信息量计算,获得另一最高信息获取量属性,再分类
-
总结步骤
- 树以代表训练样本的单个节点开始
- 如果样本都在同一个类,则该节点成为树叶,并用该类标号
- 否则,算法使用称为信息增益的基于熵的度量最为启发信息,选择能够组好的捋样本分类属性
- 所有的属性都是分类的,即离散值。连续属性必须离散化
- 对测试属性和已知的值,创建一个分支,并划分样本
- 算法使用痒痛的过程,递归的形成每个划分上的样本判定树。一旦一个属性出现在一个节点上的值都相同,就不必再考虑该节点属性(例如:上图中Age分类之后,三大类的数据集的age属性都相同,往后就不再考虑age属性)
- 停止条件
- 给定节点和所有样本属于同一类(上图中,目标class都为yes)
- 没有剩余属性来划分样本,用多数表决分类
-
其他算法
- C4.5
- Classifcation and Regression Tress(CART)
- 相同点:贪心算法,从上往下
- 区别:属性选择度量方法不同
-
树剪枝叶(避免overfitting)
- 先剪枝
- 后剪枝
-
决策树优点:直观、便于理解、小规模数据集有效
-
决策树缺点:处理连续变量不好(因为属性必须离散化)、类别较多时错误增加的比较快、可归模型一般(数据量大的时候不适用,复杂度高)
决策树的应用
- python 基础
- python机器学习的库:scikit-learn
- 特性
- 简单高效的数据挖掘,机器学习分析
- 基于numpy、Scipy和matplotlib
- 开源
- 覆盖领域问题
- 分类
- 回归
- 具类
- 降维
- 模型选择
- 预处理
- 特性
pip install -U scikit-learn
安装 scikit learn 库
- 安装Graphviz来讲dot文件转为pdf可视化决策树
| RID | age | income | student | credit_rating | class_buys_computer |
|---|---|---|---|---|---|
| 1 | youth | high | no | fair | no |
| 2 | youth | high | no | excellent | no |
| 3 | middle_aged | high | no | fair | yes |
| 4 | senior | medium | no | fair | yes |
| 5 | senior | low | yes | fair | yes |
| 6 | senior | low | yes | excellent | no |
| 7 | middle_aged | low | yes | excellent | yes |
| 8 | youth | medium | no | fair | no |
| 9 | youth | low | yes | fair | yes |
| 10 | senior | medium | yes | fair | yes |
| 11 | youth | medium | yes | excellent | yes |
| 12 | middle_aged | medium | no | excellent | yes |
| 13 | middle_aged | high | yes | fair | yes |
| 14 | senior | medium | no | excellent | no |
上面为下面代码所用数据
#coding=utf-8
import numpy as np
from sklearn.feature_extraction import DictVectorizer
# sklearn对数据格式有要求,DicVectorizer来转换输入格式为sklearn可识别的格式
import csv
from sklearn import preprocessing
from sklearn import tree
from sklearn.externals.six import StringIO
allElectronicsData = open(r'./resources/AllElectronics.csv', 'rb')
reader = csv.reader(allElectronicsData)
headers = reader.next()
# 读取csv文件,reader.next()表示读取一行并将指针移动至下一行
# 因为第一行是标头,所以使用headers存储表头
featureList = []
labelList = []
for row in reader:
labelList.append(row[len(row)-1])
rowDict = {}
for i in range(1, len(row)-1):
rowDict[headers[i]] = row[i]
featureList.append(rowDict)
# 这里将每行数据按存入字典中,再将字典存入到列表中
vec = DictVectorizer()
dummyX = vec.fit_transform(featureList) .toarray()
print("dummyX: " + str(dummyX))
print(vec.get_feature_names())
print("labelList: " + str(labelList))
# vectorize class labels
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY: " + str(dummyY))
# 使用DictVectorizer转换数据
clf = tree.DecisionTreeClassifier(criterion='entropy')
# 指定决策树算法 criterion='entropy' 为信息熵算法
clf = clf.fit(dummyX, dummyY)
print("clf: " + str(clf))
# Visualize model
with open("./resources/allElectronicInformationGainOri.dot", 'w') as f:
f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file=f)
# 上面建立好决策树
oneRowX = dummyX[0, :]
print("oneRowX: " + str(oneRowX))
# oneRowX: [0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]
# 下面修改旧数据做成新数据,使用上面的决策树来预测
newRowX = oneRowX
newRowX[0] = 1
newRowX[2] = 0
print("newRowX: " + str(newRowX))
# newRowX: [1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
predictedY = clf.predict(np.array(newRowX).reshape(1, -1))
print("predictedY: " + str(predictedY)) # 1
DictVectorizer()转换字典为scikit-learn可识别数据格式
例如:一列只有三种值:mid、small、big,则DictVectorizer转换001表示small、010表示mid,100表示big
跑出来的allElectronicInformationGainOri.dot文件使用
dot -T pdf allElectronicInformationGainOri.dot -o output.pdf来转换成决策树图
安装 graphlab creator
- 安装anaconda
- 去官网注册认证
- 从官网下载
- windows下
activate gl-env进入虚拟环境ipython notebook启动notebook- enter是换行
- ctrl + enter 是运行当前框
可能遇到的问题:https://blog.csdn.net/u013569000/article/details/53886656
修改conda国内镜像:conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
修改pip国内镜像:-i https://pypi.tuna.tsinghua.edu.cn/simple
在graphlab中使用python
- people.csv 内容如下
| First Name | Last Name | Country | age |
|---|---|---|---|
| Bob | Smith | US | 24 |
| Alice | Wili | Candata | 25 |
| Mal | Jone | England | 26 |
| Felix | Borwn | USA | 27 |
| ALex | Coooper | POland | 28 |
| Tod | Cam | US | 29 |
| Derek | Ward | Sitzerland | 30 |
import graphlab
# 读取文件
sf = graphlab.SFrame('people.csv')
sf
# 查看前几行
sf.head
# 查看尾几行
sf.tail
# GraphLab Canvas,在Graphlab中对数据有个直观的了解
sf.show()
# 将GraphLab Canvas输出重定向到本页面,就不会跳转页面这么麻烦了
graphlab.canvas.set_target("ipynb"); # 将输出显示到ipynb中
sf['age'].show(view='Categorical') # 年龄显示,分类比例
# 操作列数据
sf['Country']
sf['age']
# 列上的简单运算
sf['age'].mean() # 计算平均值
sf['age'].max() # 计算最大值
# 新增列
sf['FUll Name'] = sf['First Name'] + " "+ sf['Last Name'] # 新增全称列,定义全程列为first name 加上 last name
sf
# 列元素运算
sf['age'] + 2 # 所有age列元素都加上2
sf['age'] * sf['age']
sf
# 应用apply函数来转换数据,实现逐行应用某一个给定函数的功能
# 这里假设 US和 表示相同的国家,但是很明显程序认为US和USA表示不同国家,因此需要手动书写代码让USA和US表示相同国家
def transform_country(country):
if country == 'USA':
return "US"
else :
return country
sf['Country'].apply(transform_country) # 将所有的USA都转换成了US,但是没有赋值回去改变数据集
sf['Country'] = sf['Country'].apply(transform_country) # 赋值回去sf

上述代码逐行运行
回归
- 计算残差平法和最小的 y = ax + b

- 加入影响因素:单纯的一条直线可能不能够模拟房价,需要加入其他因素
- 可能使用二次函数、三次等,同样需要计算残差平法和
- 但不管如何都是线性回归
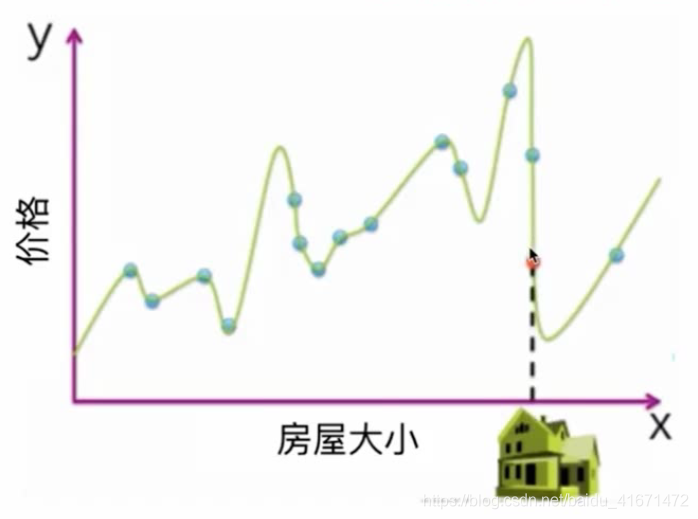
上图为极端情况,使用的是十三次函数,使得残差平方和降为0
这样看起来很好,但是这样称为过度拟合,即所计算出来的曲线是不真实存在的
过拟合计算出来的曲线可以完美适配你提供的训练数据,但是一旦加入新的数据则无法匹配
-
选择合适的模型阶数/复杂度
- 模拟预测:将数据集中的部分数据去除,将剩余数据进行拟合,当拟合模型完毕后与之前去除的数据进行比较
- 用于拟合的数据称为训练集,被去除的数据成为u测试集
-
训练/测试误差

- 加入其他特征
- 上述曲线仅仅通过房屋面积来模拟价格
- 现实状况是:面积、地段、房屋设置、布局……都是考虑范围
使用回归模型预测房价

分类模型
-
判断邮件是否为垃圾邮件、判断文本关于什么等
-
我想吃寿司,一家店的评论
- 寿司真好吃
- 拉面不好吃
- 我老婆喜欢这家店的寿司
-
构建餐厅评价系统
- 获得餐厅的所有评论
- 把所有评论拆分成句子
- 句子情感分类器:分离语句情感判断评论好坏

除开评论,垃圾邮箱、网页内容、图片分类等也可以使用分类器
-
分类器的问题
- 如何得到正面/负面的单词列表
- 词语的情感问题不同:Great和Good强度不同;考虑单词的情感程度
- 单独的单词不够:not 和 good 组合一起是负面的含义
- 词语的权重
-
线性分类器:
| 单词 | 权重 |
|---|---|
| good | 1.0 |
| great | 1.5 |
| awesome | 2.7 |
| bad | -1.0 |
| terrible | -2.1 |
| awful | -3.3 |
| we,the,that | 0 |
// 通过上述权重分析下面一条评论
Sushi was great.
the food was awesome.
but the service was terrible
Score = 1.5 + 2.7 - 2.1 > 0 // 得出改评论是正面的
-
决策边界
-
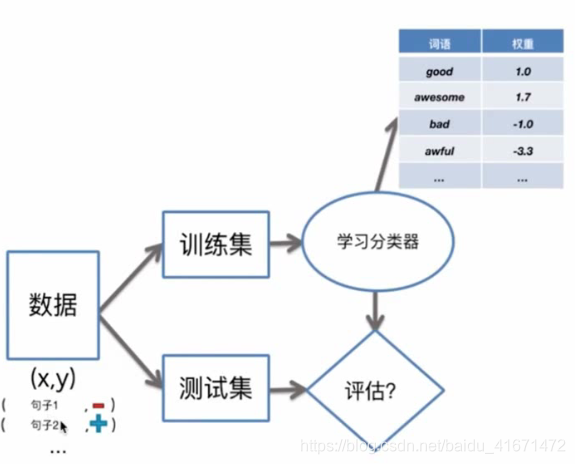
训练和评估分类器
- 训练分类器=学习权重
- 误差 = 错误数 / 句子样本数
- 精度 = 正确数 / 句子样本数
- 好的精度:
- 最差的情况下,分类器至少要比随机猜测好。即二元分类大于1/2的正确率,三元分类大于1/3
- 具体情况具体分析,多数类预测:分类器能分出90%的垃圾邮件,但实际上全是90%的邮件都是垃圾邮件,所以90%的精度并不够高
- 对报告出的的精度问题进行深度研究
- 好的精度:
- 误差(错误的种类)
- 混淆矩阵
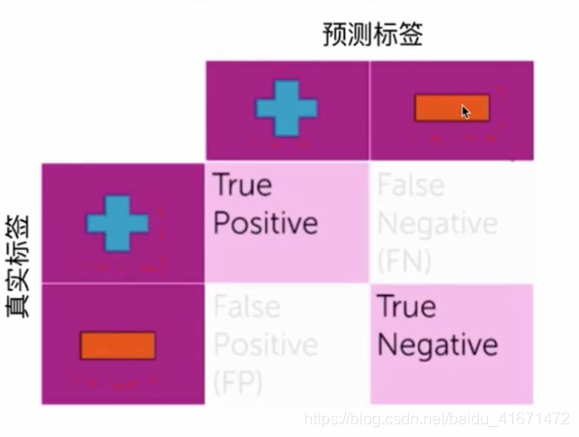
True 表示预测正确,False表示预测错误
False Positive 和 False Negative所代表的都是错误
但是两个造成的影响却不相同:
如果是垃圾邮件被认为是正常邮件那就是邮箱多了个垃圾邮件而已
如果是重要邮件被识别为垃圾邮件那么就失去了重要邮件
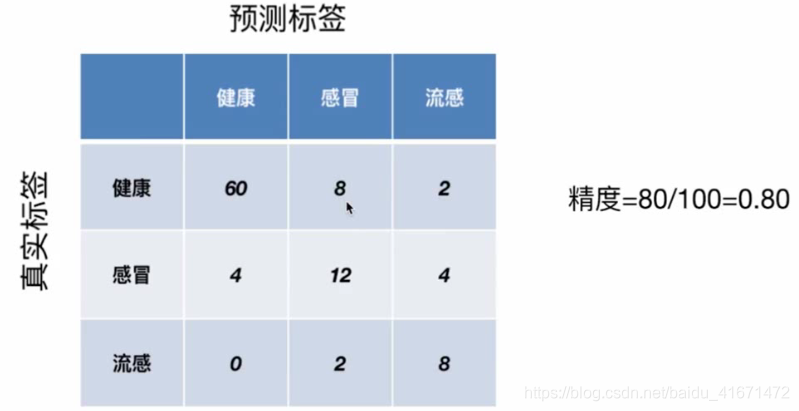
通过真实标签可知健康人数:70 感冒:20 流感 10
通过预测标签可知 精度为 (60 + 12 + 8) / 100 = 0.8
可以说这个分类器容易将:
健康人误诊为感冒、也有可能误诊为流感
感冒人误诊为:健康和流感都有可能
流感有可能误诊为感冒
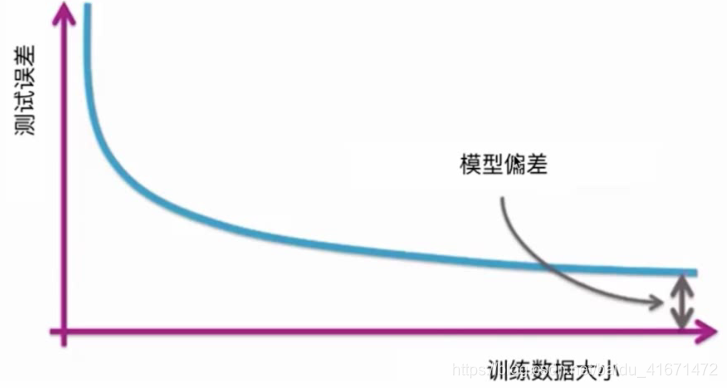
- 学习曲线:模型到底需要多少数据
- 在数据质量有保证的前提下是越多越好的
- 理论结果通常对对需要的数据定义一个界限
- 对于实际应用来说,界限通常太松
- 可以作为一个指导
- 在实践中
- 越复杂的模型 需要更多的数据
- 经验分析可以作为指导
分类器实践















 3629
3629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









