






 主动学习通过迭代选择最具价值的样本进行标注,降低数据标注成本。不稳定性采样策略关注模型对样本预测的不稳定性,利用历史模型的差异来挑选样本,尤其在深度学习场景下,能有效提升模型性能。实验表明,不稳定性采样在多数情况下优于随机采样和其他不确定性采样方法,但模型数量过多可能影响效果。
主动学习通过迭代选择最具价值的样本进行标注,降低数据标注成本。不稳定性采样策略关注模型对样本预测的不稳定性,利用历史模型的差异来挑选样本,尤其在深度学习场景下,能有效提升模型性能。实验表明,不稳定性采样在多数情况下优于随机采样和其他不确定性采样方法,但模型数量过多可能影响效果。
背景
在现实应用场景中,训练一个有效的深度模型依赖大量已标注样本,而准确标注大规模数据往往耗时耗力且代价高昂。为降低模型对数据的依赖,相继提出无监督学习,半监督学习以及弱监督学习等领域的学习方法。在这些方法中,主动学习是降低样本标注代价的主要途径之一。
主动学习:通过迭代方式,选择最有价值的样本进行标注后加入训练,用最小的标注代价有效提高模型性能。
采样策略
设计策略使所查询的信息对改进目标模型有帮助。目前已提出了许多主动学习方法:一些方法是挑选信息量最大的样本进行查询。信息量可用不同标准来衡量,如不确定性、泛化误差减少量,但该类方法只考虑了模型对样本的需求,可能导致挑选的样本分布与数据集真实分布存在差异。另一些方法是查询具有代表性样本的标签,其代表性可以根据聚类结构或者密度来估计,但该类方法挑选的是最能够代表样本分布的样本,忽略了模型本身对样本分类性能的信息。
不确定性采样策略,包括最低置信度采样、边缘采样和熵采样。核心思想:是用模型对样本的预测后验概率来估计该样本的不确定性。模型在未标记样本上的预测概率越均衡(样本属于多个类别的概率差不多),越难以判断该样本所属的类别,将其加入训练将有效提高模型的分类性能(在进行数据分类时,越靠近分类面的样本,越具有不确定性,其含有的信息量也越大)以二分类任务为例, 熵采样策略通常选择后验概率最接近0.5的样本。
信息量与代表性相结合的方式可分为三类:
- 串行结合方式,依次使用每个挑选策略来过滤“低价值”样本。常用做法为先从无标注样本集中挑选最有信息量的一批样
本,然后用聚类算法对这一批样本进行聚类,得到的聚类中心即为待查询样本。
-
概率选择方式,在每轮主动学习迭代中,依据概率参数决定当前轮迭代使用的采样策略。
- 并行结合方式,目前最流行的主动学习策略结合方式,使用不同采样策略标准的加权求和或多目标优化方法计算混合得分,根据分数对未标注样本进行排序,挑选得分最高的一批样本。
不稳定性采样
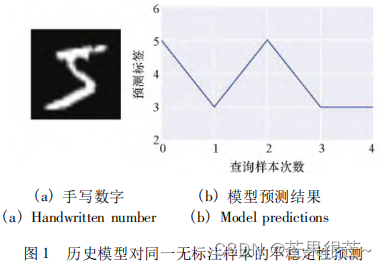
上述方法试图估计样本对改进模型的潜在价值,但只用当前模型对无标注样本进行评估,忽略了历史模型所蕴含的对未标注样本预测稳定性的信息。不同迭代周期中,目标模型对同一样本的识别效果是变化的(分类模型对该样本的识别能力的不稳定性)。量化变化信息,挑选出模型识别效果最不稳定的样本,选择这类样本进行标注加入训练对提升目标模型泛化性能提供更多有效信息。忽略历史模型的潜在价值将导致主动学习策略挑选的并不一定是最有价值的样本。因此,在主动采样的过程中,除了考虑当前模型对未标注样本的预测,还应考虑以往模型预测的差异。
不稳定性采样的主动学习方法,根据模型在整个学习过程中对无标注样本的预测差异 来衡量未标注样本对提升模型性能的潜在效用。计算最近的 N 个模型对无标注样本预测后验概率的差异 衡量其不稳定性,并选择最不稳定的样本进行标注。

不稳定性指标定义
问题设定和学习框架(流程图)
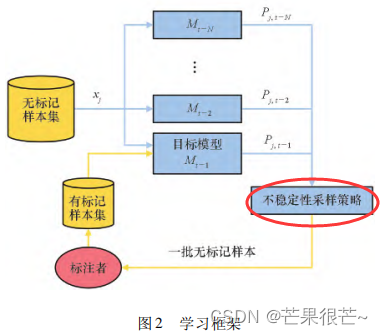
除第一轮主动学习迭代,采用随机采样挑选样本,之后的每轮迭代,都使用离当前轮次最近的 N 个历史分类模型{ Mt - 1,Mt - 2,…,Mt - N}对每一个无标注样本 xj进行预测,得到 N 个后验概率。再使用不稳定性采样来估计每个无标注样本的不稳定性,并挑选最不稳定的样本进行标注。
不稳定性采样策略(方法)
主动学习第 t 轮迭代 中,以往的模型,即{ Mt - 1,Mt - 2,…,Mt - N } 对无标注样本 xj 预测结果不稳定,这表明目标模型对该样本的识别能力不足。预测越不稳定,该样本越难以被有效地识别。因而,应尽可能挑选最不稳定的样本进行查询。
- 用度量模型计算识别能力:用信息熵衡量模型预测的不确定性,模型越难判断样本所属类别,识别能力越低。
- 用后验概率分布差异衡量模型识别能力变弱的程度:分布差异的度量方式有 KL 散度、JS 散度和 asserstein 距离。




基于不稳定性采样的主动学习方法实验
实验设置
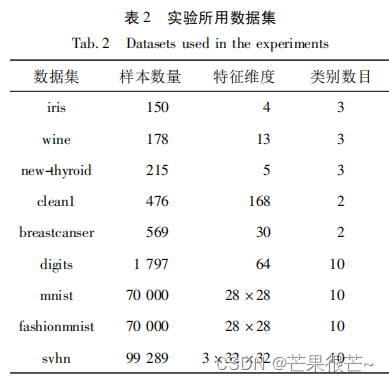

为了进一步验证所提出方法在传统模型和深度模型上的有效性,使用不同的基分类模型,逻辑斯蒂回归( logistic regression) 模型、LeNet-5 和ResNet18。所有实验使用的都是未经过预训练的初始化模型。将数据集划分为 70% 的训练样本和 30% 的测试样本。
对于传统模型:训练集随机采样 5% 的样本来初始化有标注样本集,在每轮主动学习迭代中,通过采样策略挑选 b = 1 个未标注样本进行标注并加入有标注集,总标注预算为 200。
对于深度模型:初始的已标注训练样本占整个训练集的0.5%,总标注预算为500;svhn 除外,其随机采样 1% 的样本来初始已标注集,总标注预算为2 000。深度模型在每轮主动学习迭代中挑选 b = 10 个样本进行标注。不同的标注预算依据实验最终的收敛情 况而定,以便于观察主动学习采样策略性能。
实验初始学习率设为 0.01,批量大小为 64, mnist 和 fashionmnist 数据集:每50 次迭代更新学习率为原来的10% ,svhn 数据集:每 20 次迭代更新学习率为原来的 90% 。重复进行 5 次实验,计算每轮主动学习迭代中目标模型的平均准确率,并绘制平均准确率随查询样本数的变化曲线,曲线提升得越快,说明采样策略性能越高。
实验结果与分析
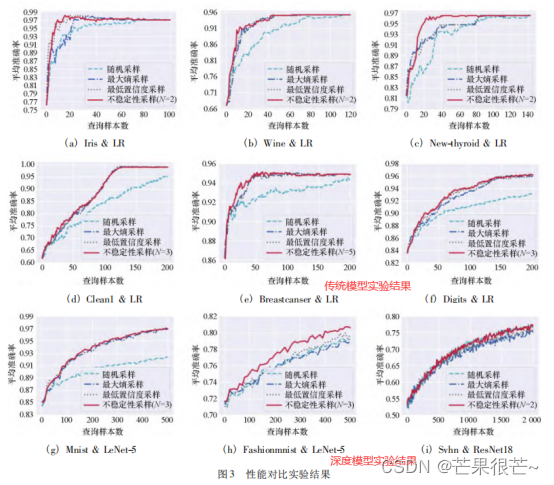
- 不稳定性采样方法在大多数情况下实现了最佳性能
- 不稳定性采样几乎在所有情况下都显著优于基准方法随机采样
-
不稳定性采样几乎在所有情况下都与不确定性采样方法( 最低置信度采样和最大熵采样) 表现相当或优于他们
总而言之,不稳定性采样能有效地挑选对模型最有用的样本,提升主动学习性能;同时说明了考虑历史模型预测不稳定性比仅基于当前模型挑选样本带来的潜在效用大。
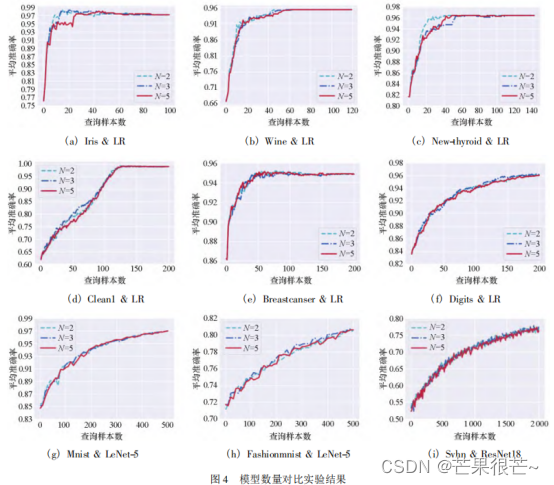
模型数量的影响
进一步研究历史模型数量 N 对实验结果的影响。分别设置 N = 2,3,5,展示出性能曲线。发现当 N = 5 时,不稳定性采样方法的性能比 N = 2 和 N = 3 的性能差。原因可能为 本文使用距当前主动学习轮次最近的前 N 个历史模型进行实验,随着主动学习迭代轮次的增加,前几轮训练得到的模型性能较弱,这些模型预测的后验概率准确率较低,计算得到的数据的不稳定都较高,使得筛选出的数据可能不是“预期的高质量数据”,最终导致随着 N 增大,方法的效果下降。
参考文献:基于不稳定性采样的主动学习方法

















 2354
2354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









