







本来想直接在SPDK的example/下添加一个新的文件夹,放我自己写的代码。
但是这样SPDK项目无法编译到我自建的文件夹。所以,想增加自己的示例并被SPDK编译,需要在/example下已有的文件夹中放自己的代码文件。如下图所示:
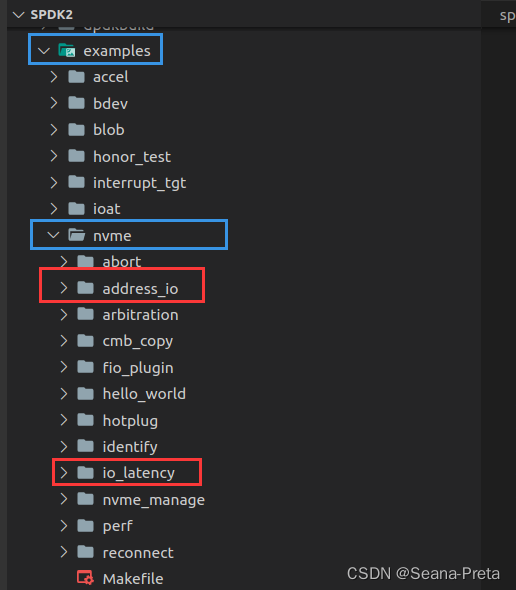
我自己编写的代码文件夹放在了examples/nvme之下。
而如果直接在examples/下放自己的代码文件,是不会被编译的。不过肯定是可以调整的,但是我还没弄明白。
1. 进行指定地址读写
思路
基于SPDK中的示例代码examples/nvme/hello_world/hello_world.c,改写为代码文件examples/nvme/address_io/address_io.c。
经过阅读代码后,知道hello_world.c的功能就是将一串字符串写入到设备的指定地址中,再从中读出来。其中关键的函数是两个:spdk_nvme_ns_cmd_write()和spdk_nvme_ns_cmd_read()
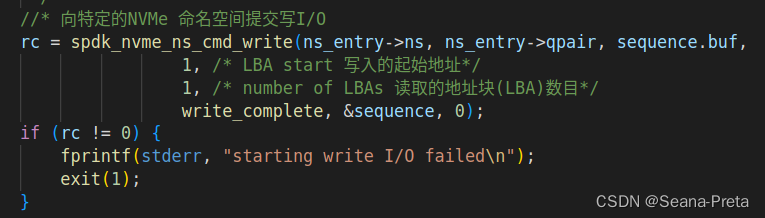
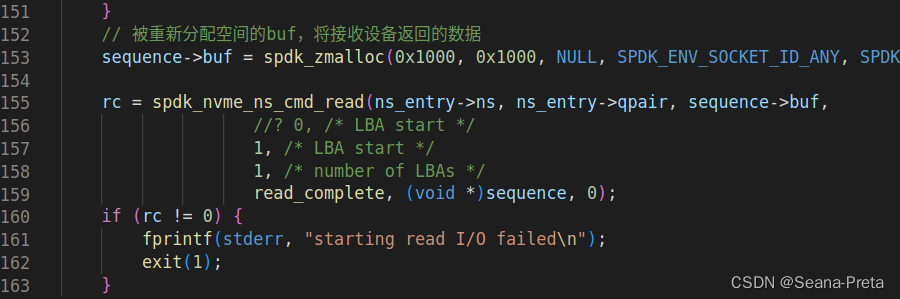
spdk_nvme_ns_cmd_write()的功能是向一个指定的LBA(Logic Base Address)写入一个buf。
相反,spdk_nvme_ns_cmd_read()的功能是从一个指定的LBA读取一定长度的数据到buf中。
在该截图中,此LBA起始地址都是1.
再根据注释,这两个函数的参数作用已经很明晰了。修改第四个参数LBA Start(操作地址),即可完成对指定逻辑块地址的IO操作。
步骤
于是乎,修改步骤如下:
- 将
hello_world.c的代码复制到address_io.c中。 - 根据需求,修改
spdk_nvme_ns_cmd_write()以及spdk_nvme_ns_cmd_read()的LBA地址参数。
2. 进行io时延测试
思路
此代码将基于examples/nvme/perf/perf.c修改。产出代码examples/nvme/io_latency/io_latency.c。
首先,我们的需求是:
- 能够模拟大规模的I/O操作;
- 能够拿到每次I/O操作的时延;
- 计算某个时延值区间中的IO操作的占比。
SPDK的perf工具就是用来测试硬盘性能的。一个基本用法是在指定的时间内,发起大规模的I/O操作,最终计算出SSD的IOPS、average latency(平均时延)等指标。一种典型的测试用法如下:
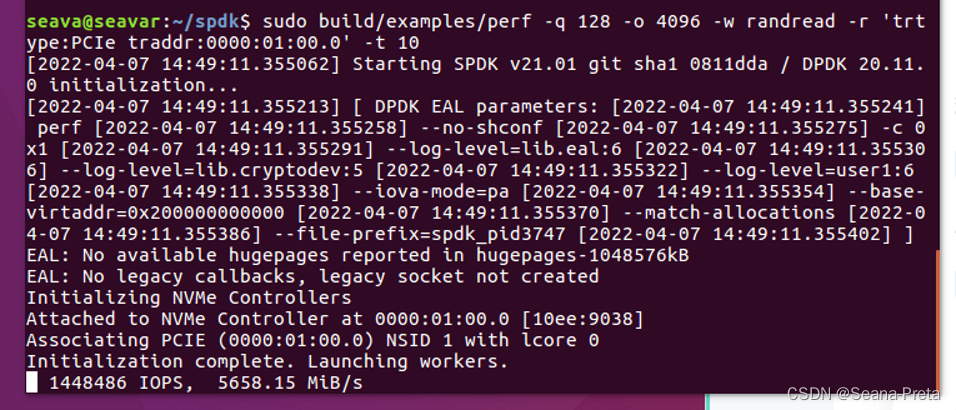
既然能够拿到平均时延,那必然是有个每次IO操作时延累加的过程的,最终才能求平均数。
于是寻找计算时延的方法。
从输出信息来找。输出Latency()us的地方。
perf.c中有个print_performance()方法:
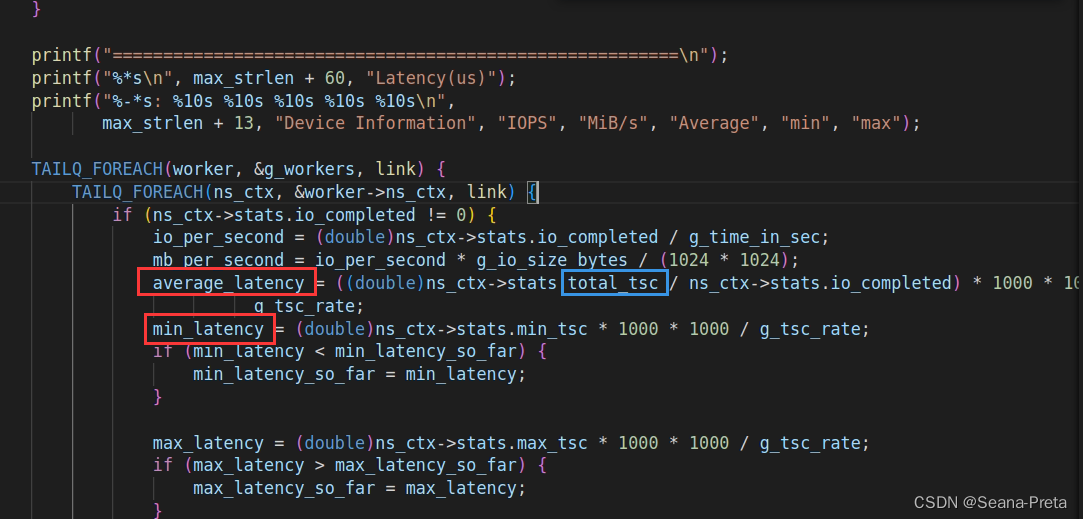
计算average_latency的语句中,有一个total_tsc变量,就是一定时间内,所有I/O操作产生的总时延。
再寻找total_tsc是在哪儿被赋值的。
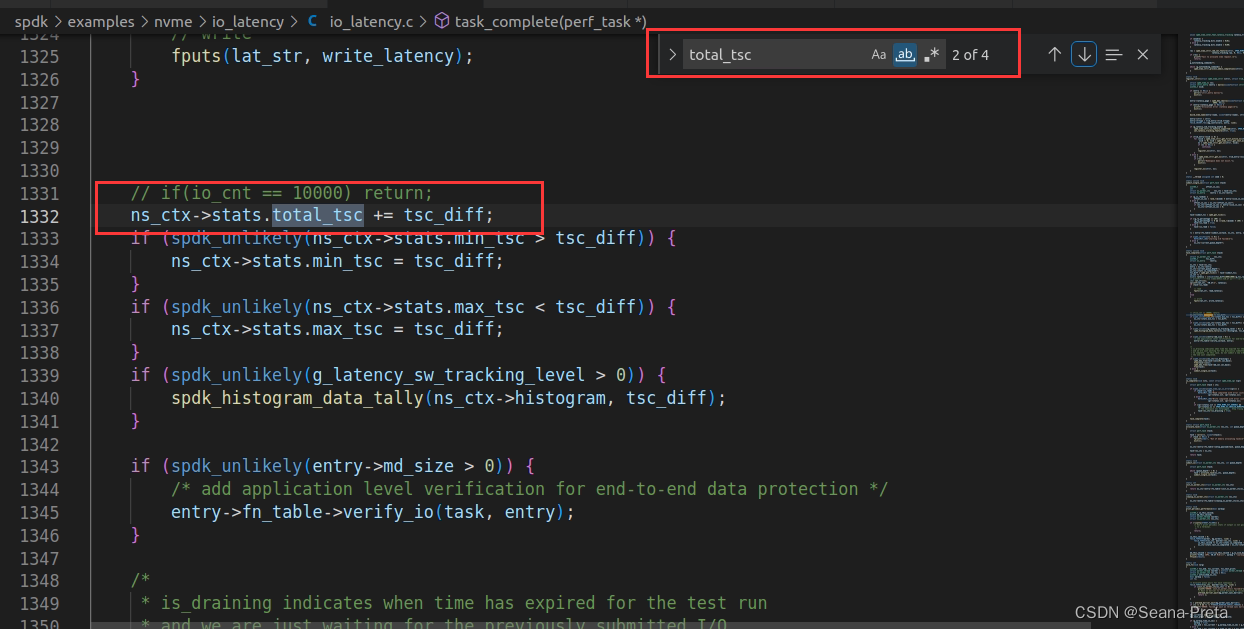
很自然,total_tsc是由tsc_diff累加而来的。
tsc_diff就是每次I/O操作产生的时延。其在task_complete()中被计算。
但是不能直接输出它。要想将之转换为以us为单位的时间值,参考对于average_latency的计算方式。
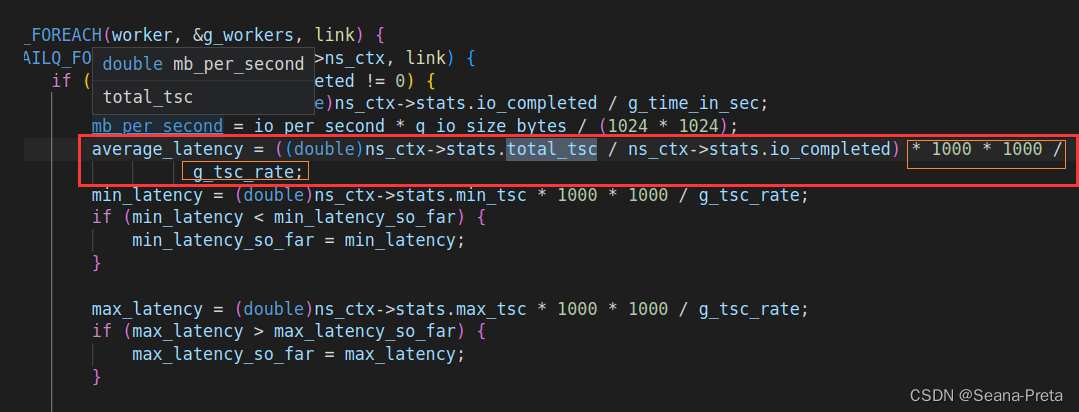
于是乎,输出代码如下:
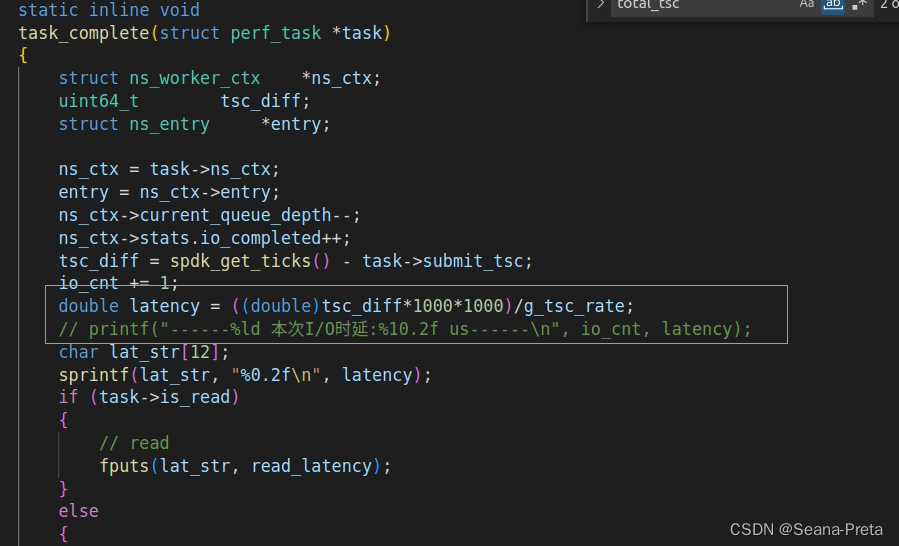
这样,每次的时延值能够拿到了。
然后利用C语言的文件结构FILE,在每次拿到一个时延,都将其存储倒一个txt中。
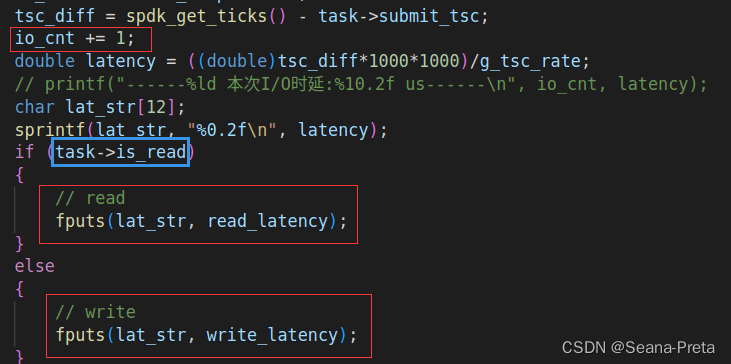
这段代码也在task_complete(strcut perf_task *task)中。
其参数task有一个属性is_read表示本次IO操作是否为读操作,可以用来区分读写操作,分别存入到不同的txt中。
图中最上方的io_cnt是为每次IO计数的。
那么也就是第二个问题:如何产生大规模的IO请求?需要定量吗?
由于这些I/O请求的处理都是异步的,不好去控制具体的IO操作数量。
笔者曾尝试设置一个宏IO_NUM,在work_fn()做判断,达到这个IO数目限制就退出程序,但是每次退出的时候处理的IO操作都比预期值多很多。
于是放弃定量IO操作。
减少执行的时间,有多少IO时延结果就存多少,最后使用python统一处理txt文件,计算每个时延挡位的占比。
步骤
总结一下步骤:
- 复制
perf.c的代码到io_latency.c中; - 根据
perf工具打印的内容,在perf.c中定位到计算平均时延的代码; - 从平均时延的代码找到计算单个时延的代码;
- 将每次IO的时延,根据
is_read的判断,输出到不同的txt文件中; - 利用python处理得到的时延txt文件,计算不同挡位的时延值。















 359
359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









