







项目地址
爬取京东苏宁商品信息(手机 笔记本电脑) 以及商品的评论 然后继承到web上,实现了价格评价的比较 并且对每件商品评论进行了情感分析,绘制了评论的词云
https://github.com/ccclll777/JDSNCompare
如果觉得有用,请点个star
项目地址:http://39.105.44.114:38888/comparePrice/index.html
京东爬虫
在这里,我爬取了京东的搜索界面,通过关键字“手机”,“和笔记本电脑”,搜索到的信息,目标站点的url为
https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&wq=%E6%89%8B%E6%9C%BA&pvid=15b7aa9229e8404c8c157db86b8563d8
https://search.jd.com/Searchkeyword=%E7%AC%94%E8%AE%B0%E6%9C%AC%E7%94%B5%E8%84%91&enc=utf-8&wq=bi%20ji%20ben&pvid=65b38d2ff9634a078f7d7d3825a39b5d
【1】京东网站界面分析
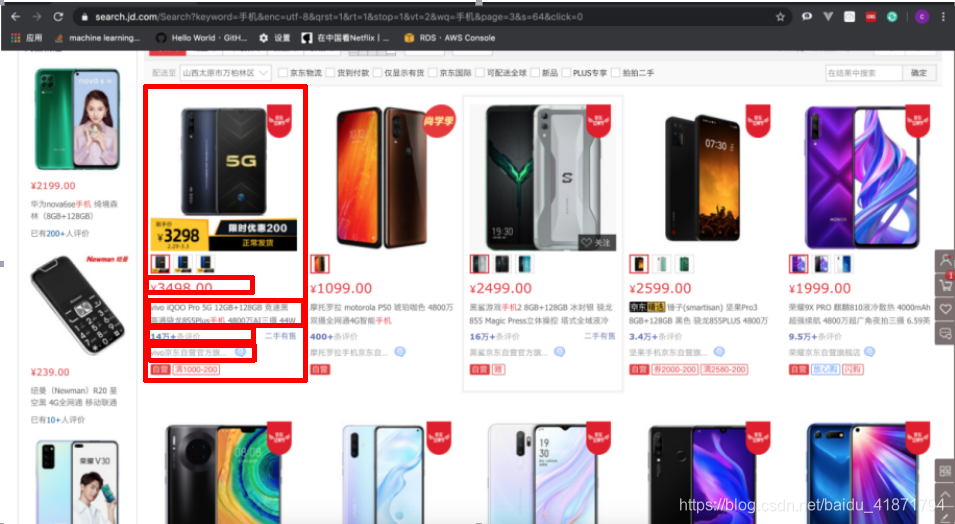
首先,我需要现在主界面中,获取到商品id,商品的详细界面的url,以及商品的价格,即。
然后,根据获取到的商品详细界面的url,进入每个商品的商品详情界面。商品详情的url中,数字部分就是这个商品的id,对于不同型号的商品都会有不同的id,进入商品详情界面后,就可以获取商品的标题,品牌,型号,店名等信息。

最后,在商品详情界面爬取商品的评论,在这里可以获取到评论的内容,评论的商品的标签,评论时间以及回复数量等
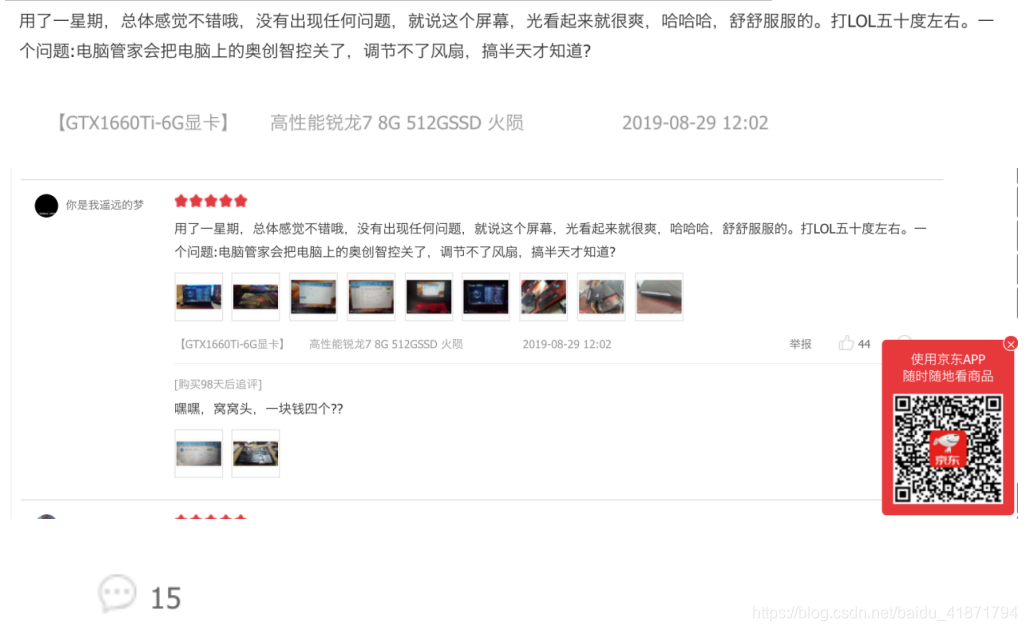
经过总结之后,发现两者的共同点,可以根据任意参数搜索信息。
商品详情界面的商品评论,通过搜索评论的内容,发现的获取评论信息的接口,返回的数据是json格式的
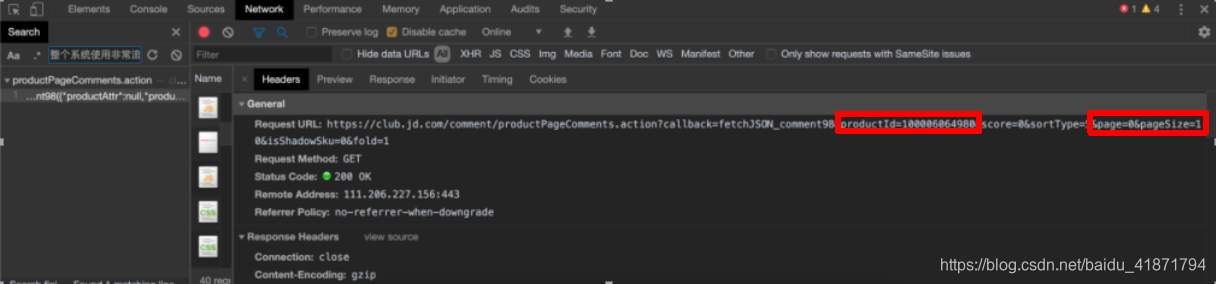
https://club.jd.com/comment/productPageComments.action?productId={}&score=0&sortType=5&page={}&pageSize=10&isShadowSku=0&fold=1
只需更改参数productId(商品的id),以及page(爬取第几页评论),这两个参数即可
【2】操作过程
(1)京东搜索主界面内容的网页源代码分析

通过对翻页的url进行分析,得到了共同的url
https://search.jd.com/Search?keyword={}&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq={}&page={}&s=51&click=0
其中{}中可以替换成搜索的关键字以及页数(京东搜索出的内容会展示100页)
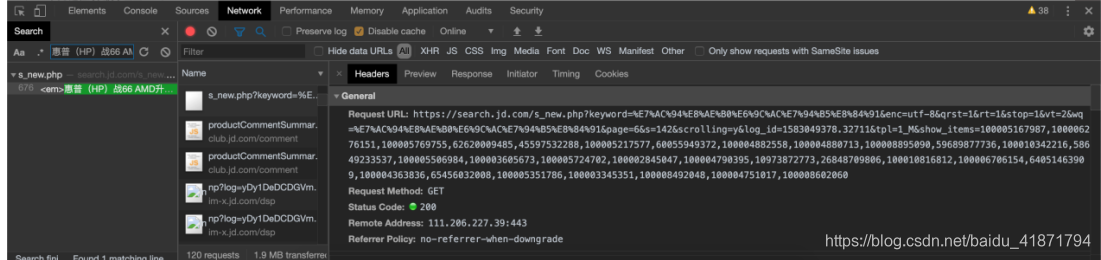
通过向下翻页,发现页面下面的内容是异步加载出来的
需要在爬取页面前半部分时,构造后半部分的url,从而爬取网页的后半部分
https://search.jd.com/s_new.php?keyword=%s&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%s&page=%d&s=76&scrolling=y&log_id=1582951658.11616&tpl=1_M&show_items=%s
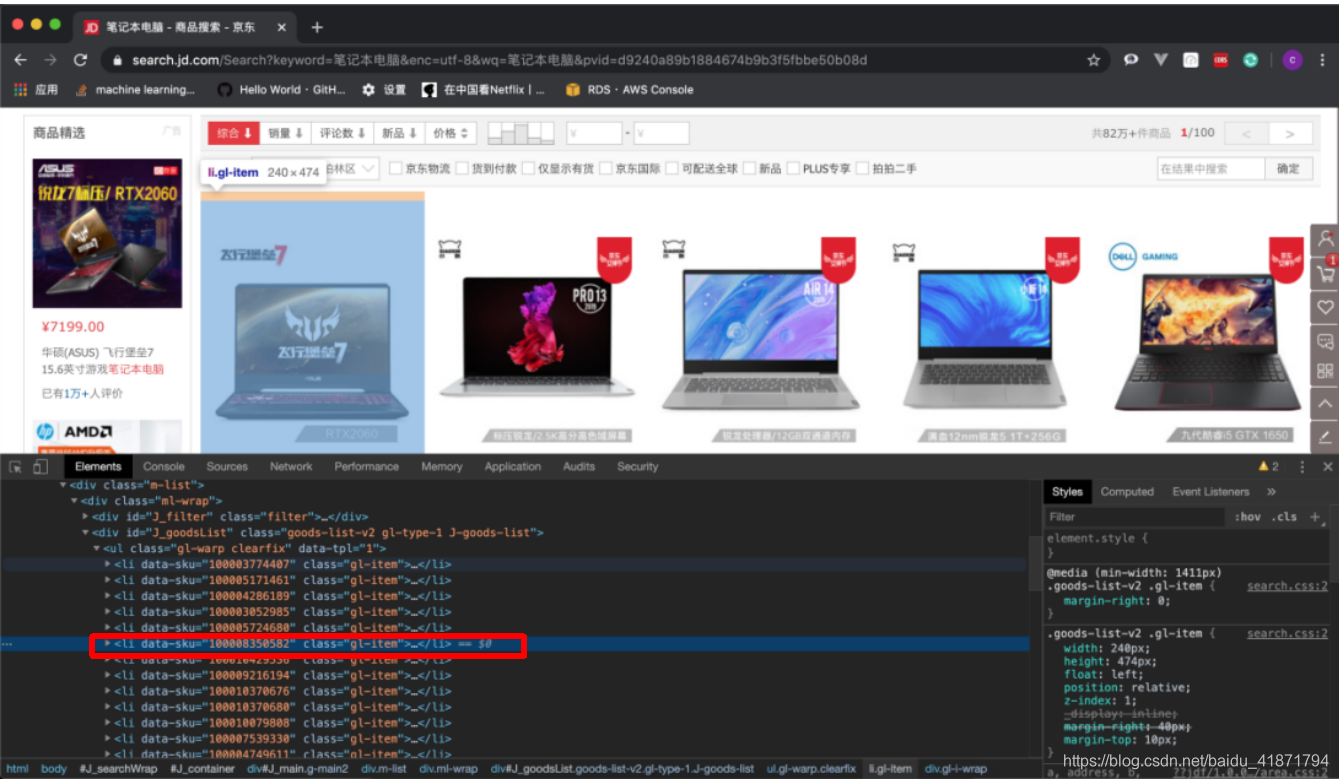
网页中的每一个商品都在一个li标签之中。我们在li标签之中提取我们需要的内容。
- 商品详情的url:
根据dom树的位置,通过class选择器层层选择
.gl-warp .gl-item .gl-i-wrap .p-name a::attr(href)
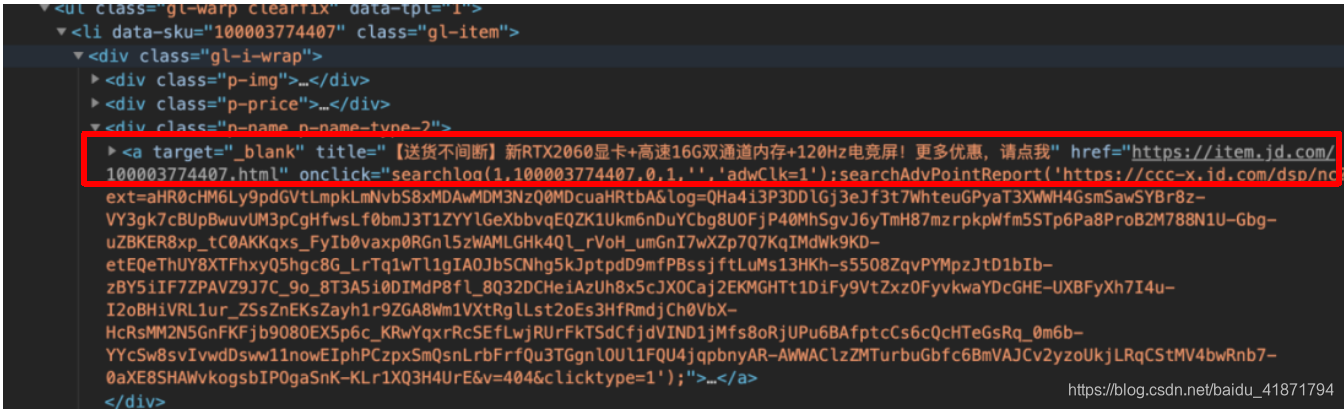
- 商品价格
根据dom树的位置,通过class选择器层层选择,
.gl-warp .gl-item .gl-i-wrap .p-price strong i::text
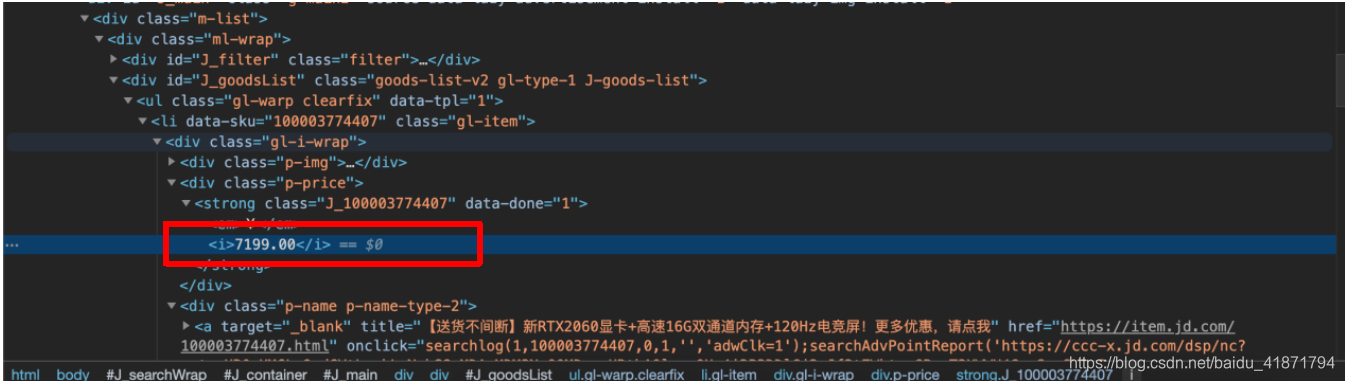
- 商品的id 即data_sku中的信息
根据dom树的位置,通过class选择器层层选择
.gl-warp .gl-item::attr(data-sku)

(2)商品的详情界面

- 商品的品牌
.inner .border .head a::text
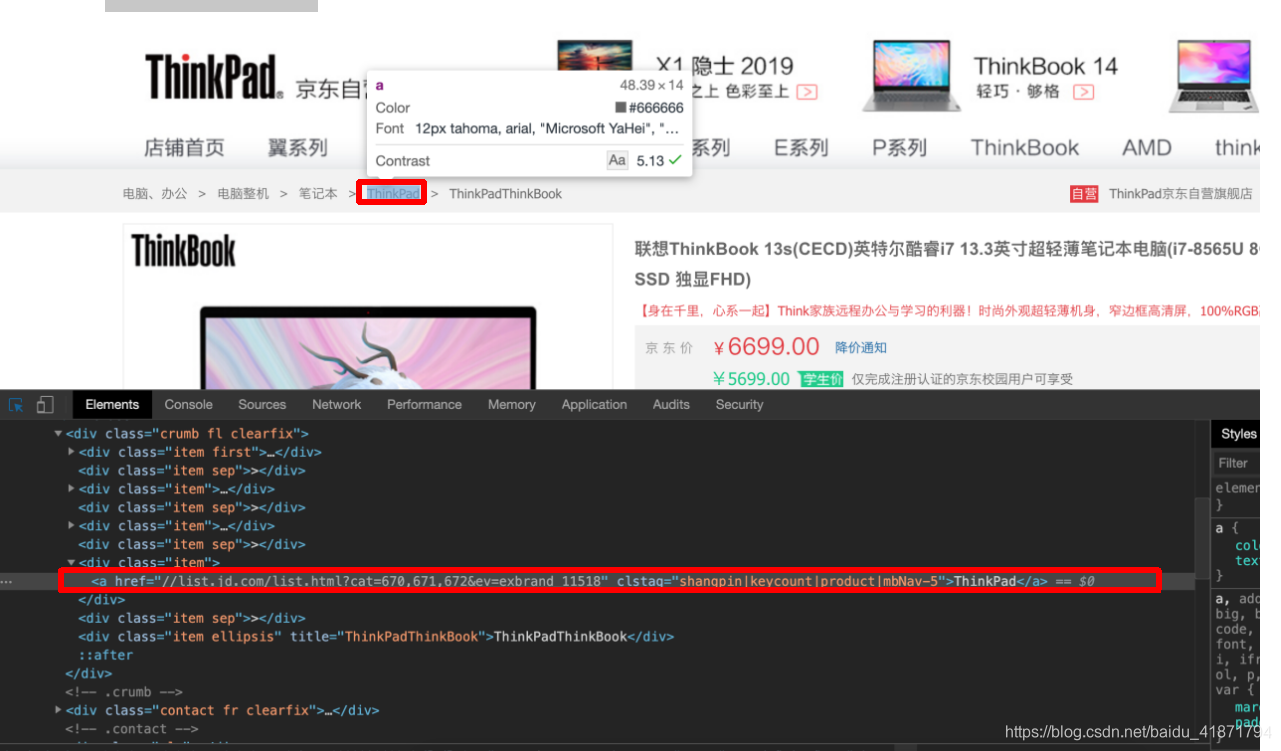
- 商品的型号
.item .ellipsis::text
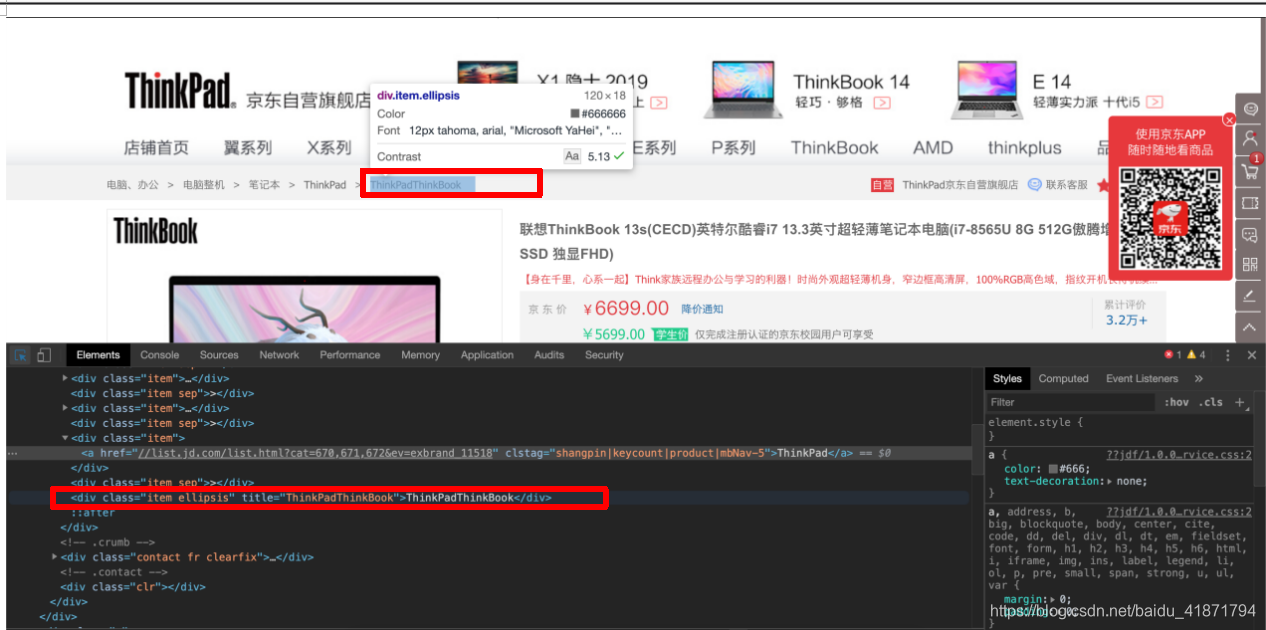
- 店铺名称
.J-hove-wrap .EDropdown .fr .item .name a::text
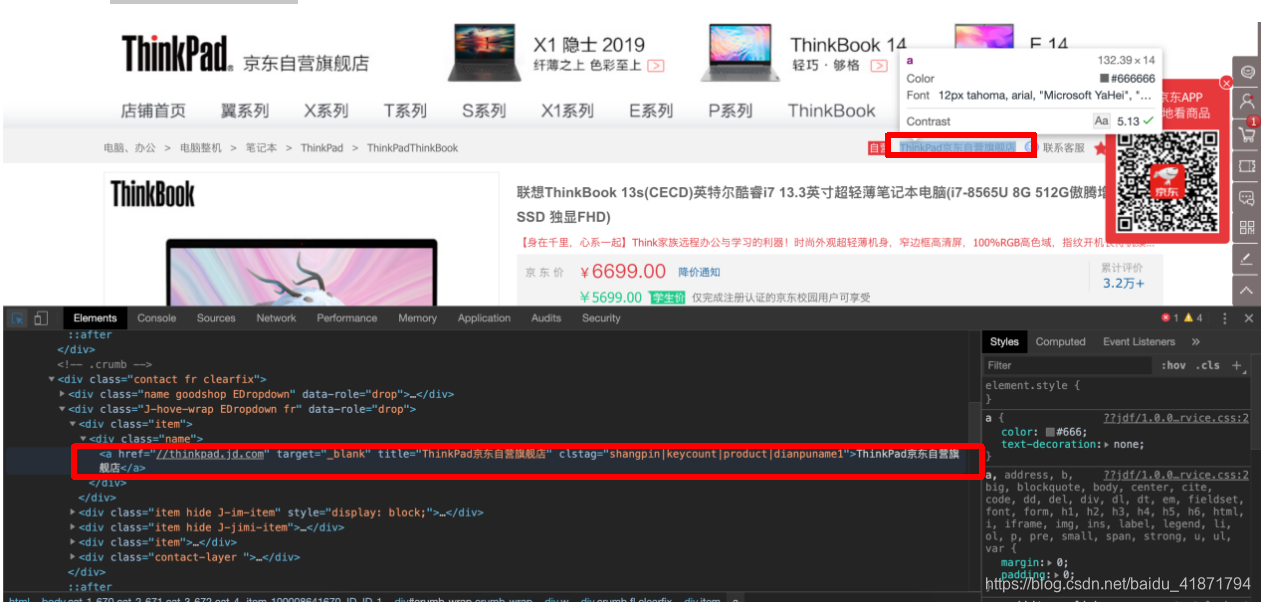
- 商品的标题
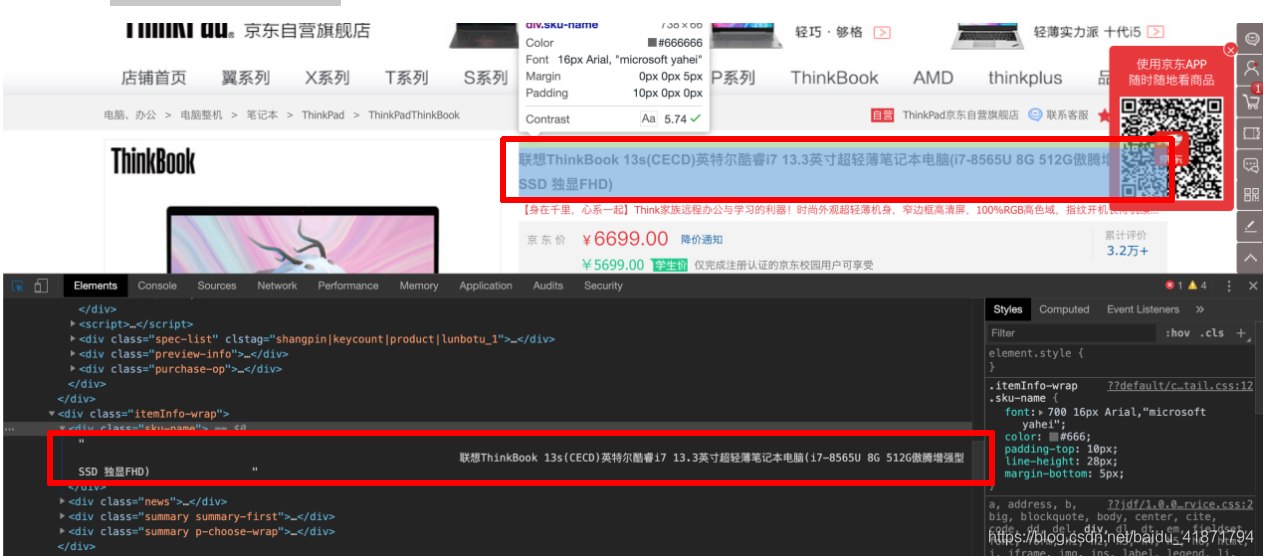
根据dom树的位置,通过class选择器层层选择,
.w .product-intro .itemInfo-wrap #spec-img::attr(alt)
(3)商品评价
根据对商品评论在console中进行搜索,发现的获取评论的接口
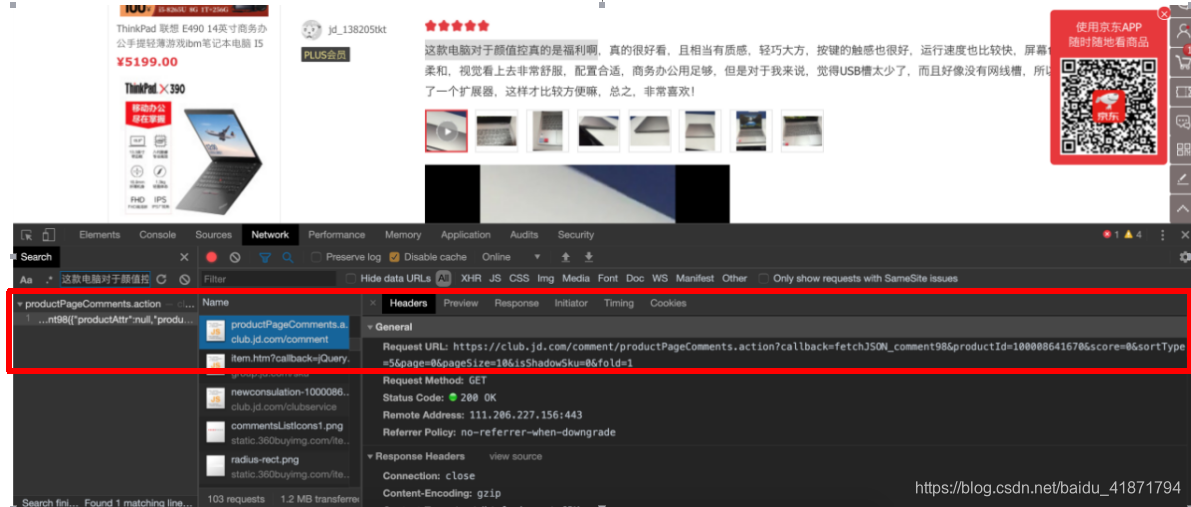
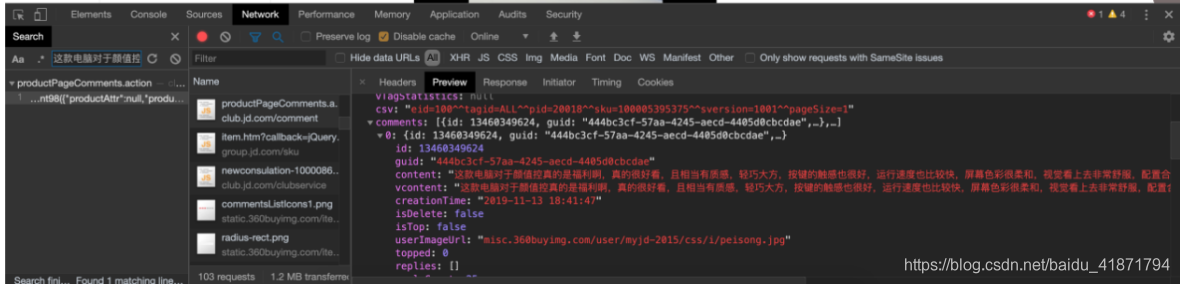
里面有相应的评论信息。通过对翻页的分析,获取到爬取评论的规律。
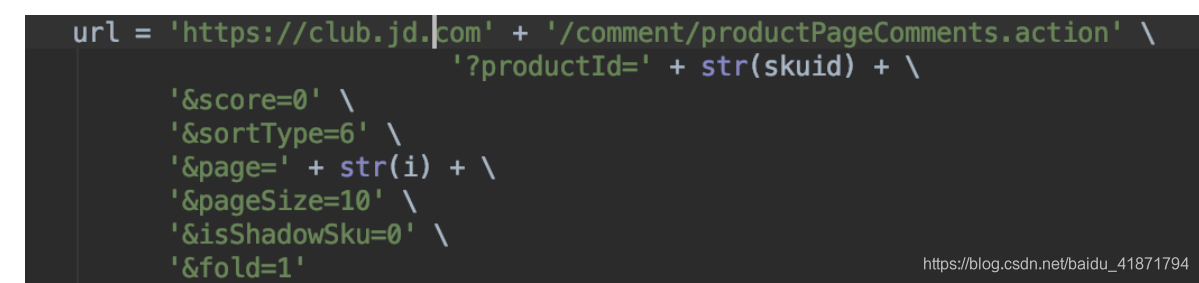
skuid为商品的id page为页数
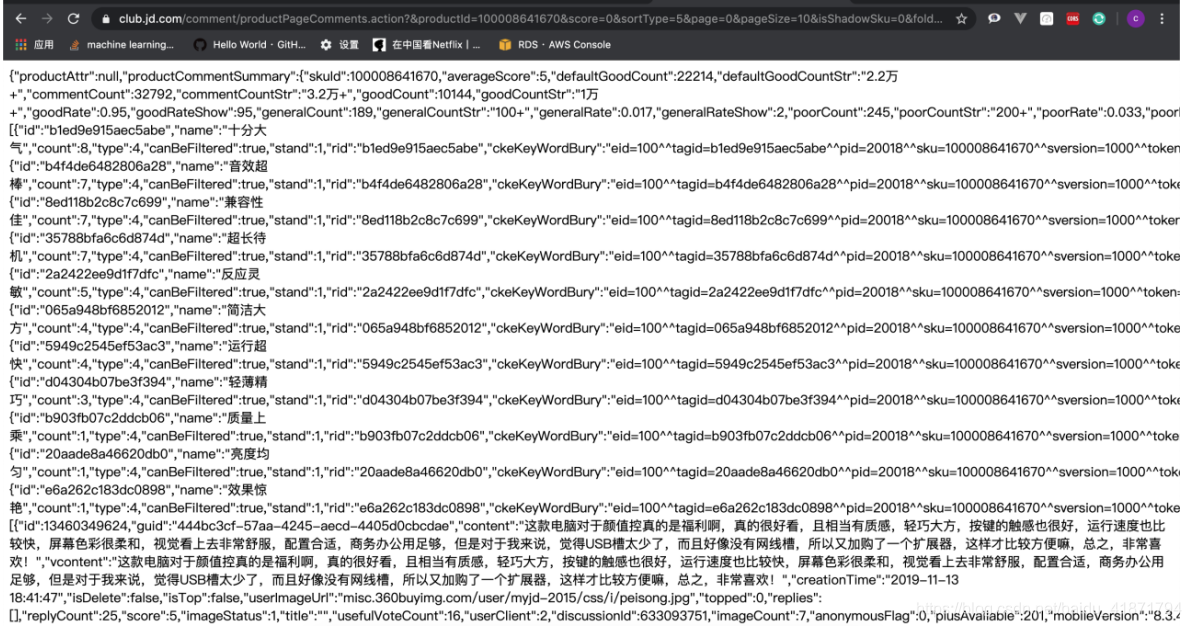
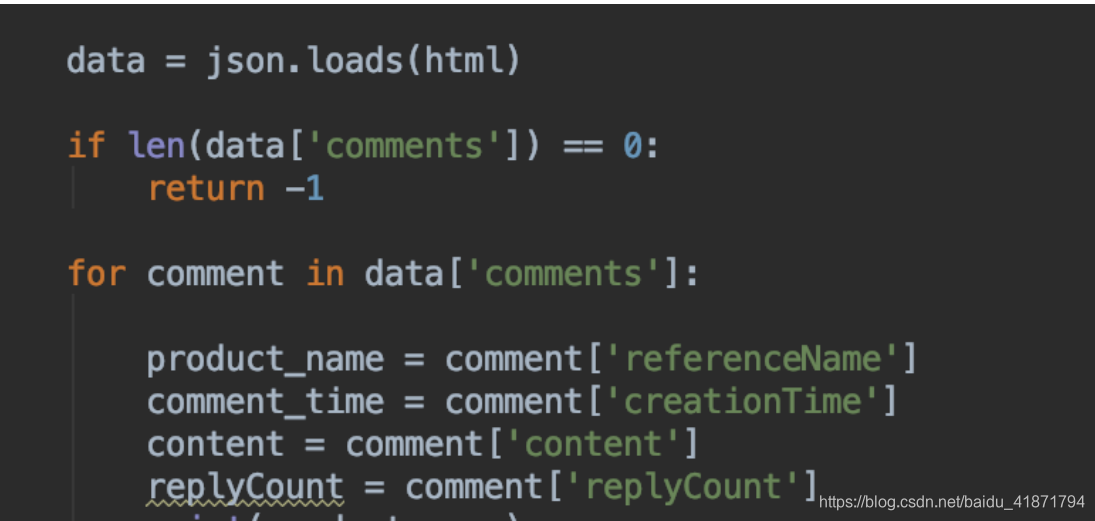
【3】数据库表的设计
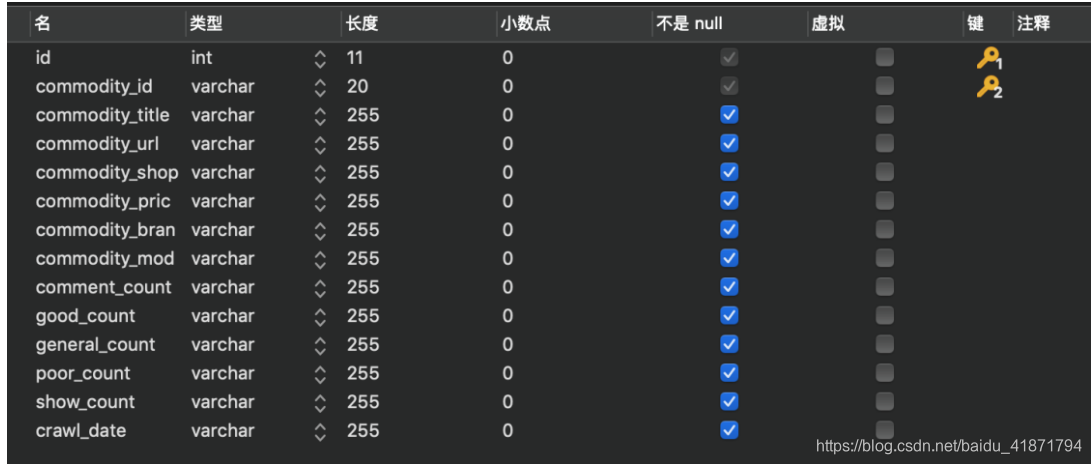
商品id (commodity_id)
商品标题 (commodity_title)
商品详情页网址 (commodity_url)
商品的网店名称 (commodity_shop_name)
商品价格 (commodity_price)
商品牌子 (commodity_brand)
商品型号 (commodity_model)
商品评论数量 (comment_count)
商品好评数 (good_count)
商品中评数 (general_count)
商品差评数 (poor_count)
商品展示数 (show_count)
爬取时间(crawl_date)
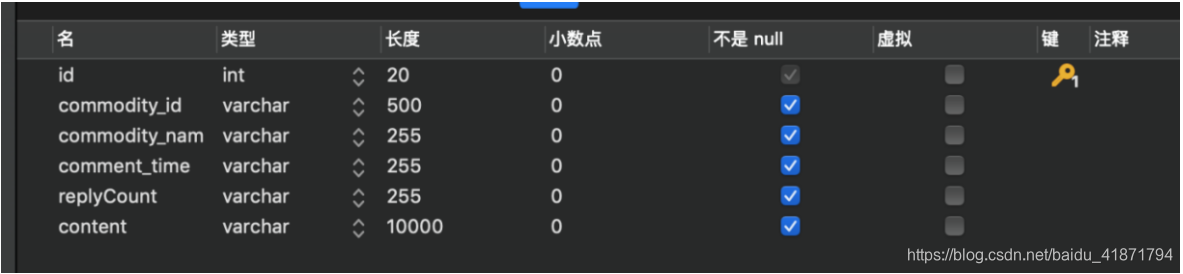
商品id (commodity_id)
商品标签 (commodity_name)
评论时间 (commodity_time)
评论的评论数 (replyCount)
评论内容(content)
【4】代码实现
项目代码在github ,如果觉得有用,请点个star
https://github.com/ccclll777/JDSNCompare
(1)扫码登陆京东
通过请求接口,将后端返回的base64编码的图片解析出来,扫描之后成功登陆,会把cookie保存在本地,如果下次登陆时,cookie没有失效,则不用再次扫码登录
import json
import os
import pickle
import re
import random
import time
import requests
from bs4 import BeautifulSoup
class Assistant(object):
def __init__(self):
self.username = ''
self.nick_name = ''
self.is_login = False
self.User_Agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36"
self.headers = {
'User-Agent': self.User_Agent
}
self.sess = requests.session()
self.item_cat = dict()
self.item_vender_ids = dict() # 记录商家id
self.item_states = dict() # 记录商品上架状态
self.risk_control = ''
try:
self.load_cookies()
except Exception:
pass
#保存coookie
def load_cookies(self):
cookies_file = ''
for name in os.listdir('./cookies'):
if name.endswith('.cookies'):
cookies_file = './cookies/{0}'.format(name)
break
with open(cookies_file, 'rb') as f:
local_cookies = pickle.load(f)
self.sess.cookies.update(local_cookies)
self.is_login = self._validate_cookies()
#验证cookie是否有效
def _validate_cookies(self):
url = 'https://order.jd.com/center/list.action'
payload = {
'rid': str(int(time.time() * 1000)),
}
try:
resp = self.sess.get(url=url, params=payload, allow_redirects=False)
if resp.status_code == requests.codes.OK:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1072
1072

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









