







希尔排序是直接插入排序的升级版,实质上是一种分组的插入排序,根据增量进行分组然后进行插入排序,克服插入排序的效率低的劣势,但是它依然是不稳定的排序方式,希尔算法在最优和最坏情况下时间复杂度相差不多。
下面根据一个例子进行解释:
假设数据集合为
data=[3,2,5,7,1,8,4,6]
增量选取为4,2,1
当增量为4时:
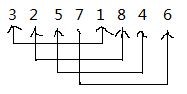
从第一点开始,每次增加4,确定为一组进行插入比较,即分成(3,1),(2,8),(5,4),(7,6)四组。
当增量为2时 :
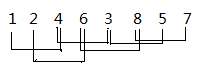
当增量为1时,就挺熟悉了,这就是插入排序了
实现1是我自己实现的希尔排序,比较麻烦,考虑边界问题,实现二是根据别人思想写的,比较简便。(学习过程中一定要有自己实现代码的过程不能一味的抄写别人的,根据别人的改进这是一个过程)
实现1:
#include <iostream>
using namespace std;
int main()
{
int data[8] = {2, 5, 8, 3, 1, 4, 7, 6};
int n = 8;
for (int delta = n/2; delta>0; delta/=2) //设定间隔delta
{
for (int i = 0; i < n; i++)
{
for (int j = i+delta; j>0; j-=delta)
{
if (j<8 && (j-delta)>=0) //判断是否越界
{
if (data[j]<data[j-delta])
{
int temp = data[j];
data[j] = data[j-delta];
data[j-delta] = temp;
}
}
}
}
}
for (int i = 0; i < 8; i++)
cout << data[i] << " ";
cout << endl;
return 0;
}实现2:
#include <iostream>
using namespace std;
int main111()
{
int array[8]={6,8,7,3,1,2,5,4};
int i, j, gap;
int n = 8;
for (gap = n / 2; gap > 0; gap /= 2)
{
for (i = gap; i < n; i++)
{
for (j = i - gap; j >= 0; j -= gap)
{
if (array[j] > array[j + gap])
{
int temp = array[j];
array[j] = array[j + gap];
array[j + gap] = temp;
}
}
}
}
for(int i=0;i<8;i++)
cout<<array[i]<<" ";
cout<<endl;
return 0;
}















 2325
2325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









