







一.绪论
很久之前就学习了KMP算法 , 也在网上查阅了许多的资料 , 但是一直对KMP算法的代码不甚熟悉 . 如果单纯靠背诵代码 , 而不理解其本质 , 是舍本逐末 . 所以今天力求用简短之篇幅讲解KMP算法 , 一是回顾知识 , 二来希望能让本文的读者有一点启发 .
二 : KMP算法讲解
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/find-the-index-of-the-first-occurrence-in-a-string
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
KMP算法 , 主要适用于这样的场景 , 即字符串A中是否包括字符串B .
解决这一问题 , 我们可以暴力匹配 , 如下图所示 , i和j分别从主串和子串的开头进行匹配 :

当两者走到下图所示位置时 , 发现匹配失败了 . 此时i和j都需要进行回溯 ;

j回溯到子串开头位置 , i回溯到主串下标为1的地方 , 再次开始匹配 .
暴力算法 , 就是重复上述的过程 , 直到我们找到一组匹配的结果为为止 . 代码如下 :
int ViolentMatch(char* s, char* p)
{
int sLen = strlen(s);
int pLen = strlen(p);
int i = 0;
int j = 0;
while (i < sLen && j < pLen)
{
if (s[i] == p[j])
{
//①如果当前字符匹配成功(即S[i] == P[j]),则i++,j++
i++;
j++;
}
else
{
//②如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0
i = i - j + 1;
j = 0;
}
}
//匹配成功,返回模式串p在文本串s中的位置,否则返回-1
if (j == pLen)
return i - j;
else
return -1;
}
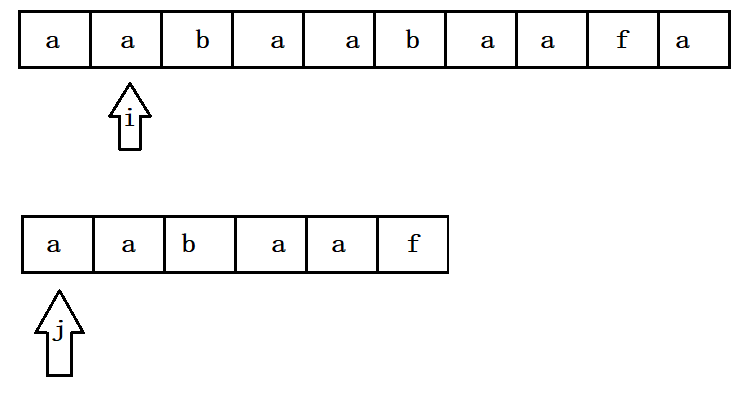
而KMP算法 , 它利用之前已经部分匹配这个有效信息,保持i 不回溯,通过修改j 的位置,让模式串尽量地移动到有效的位置。还是上面的例子 , 在第一轮匹配中 , i和j走到了下图所示的位置 , 并发现失配 :
此时i不回溯 , j回溯到子串下标为2的位置 , 继续开始匹配 :
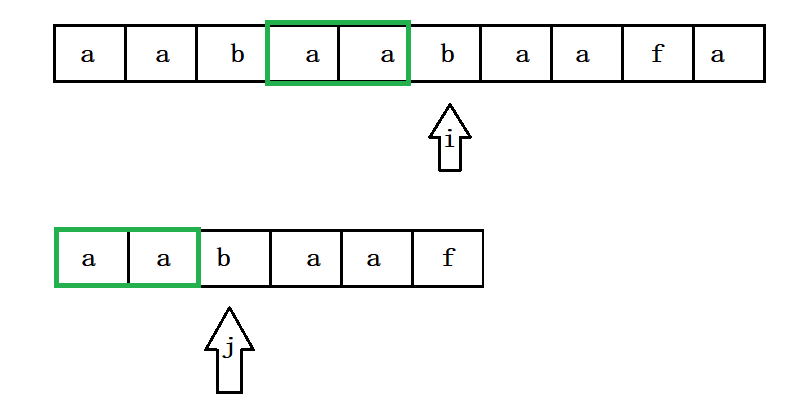
i和j继续向后走 , 发现j走到了子串的末尾 , 此时在主串中找到了匹配的结果 :
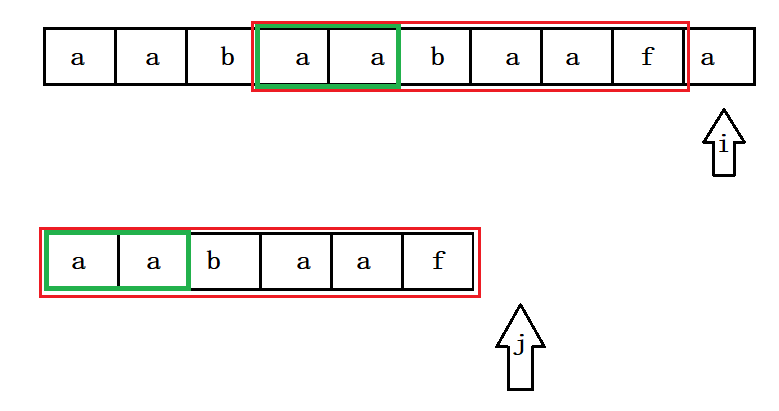
这么做果然快多了 ! 现在有一个疑问了 , 我前面直接说 , j回溯到子串下标为2的位置 , 此时有两个疑问 :
1.为什么? —> 为什么回溯到这个位置 ?
2.怎么做? —> 如何找到这个位置 ?
此处我们先插播几个概念 , 后面可能会用到 :
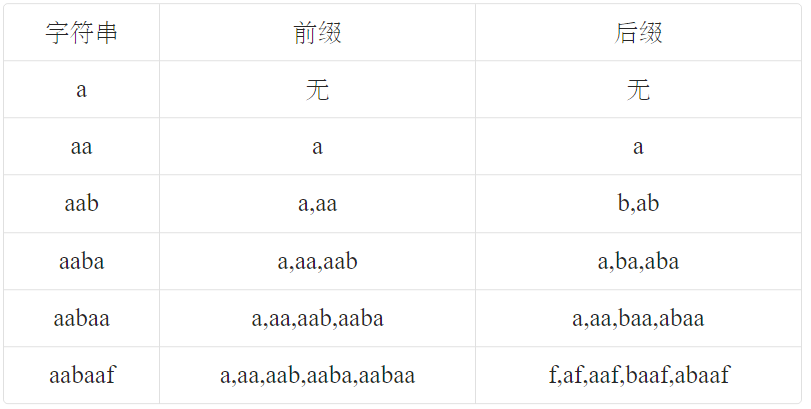
- 前缀 : 包含首位字符但不包含末位字符的子串
- 后缀 : 包含末位字符但不包含首位字符的子串
- 相等前后缀 : 就是前缀和后缀一样
- 最长相等前后缀 : 一个字符串可能会有多个前缀和后缀相等 , 这里就是指最长的那个 .


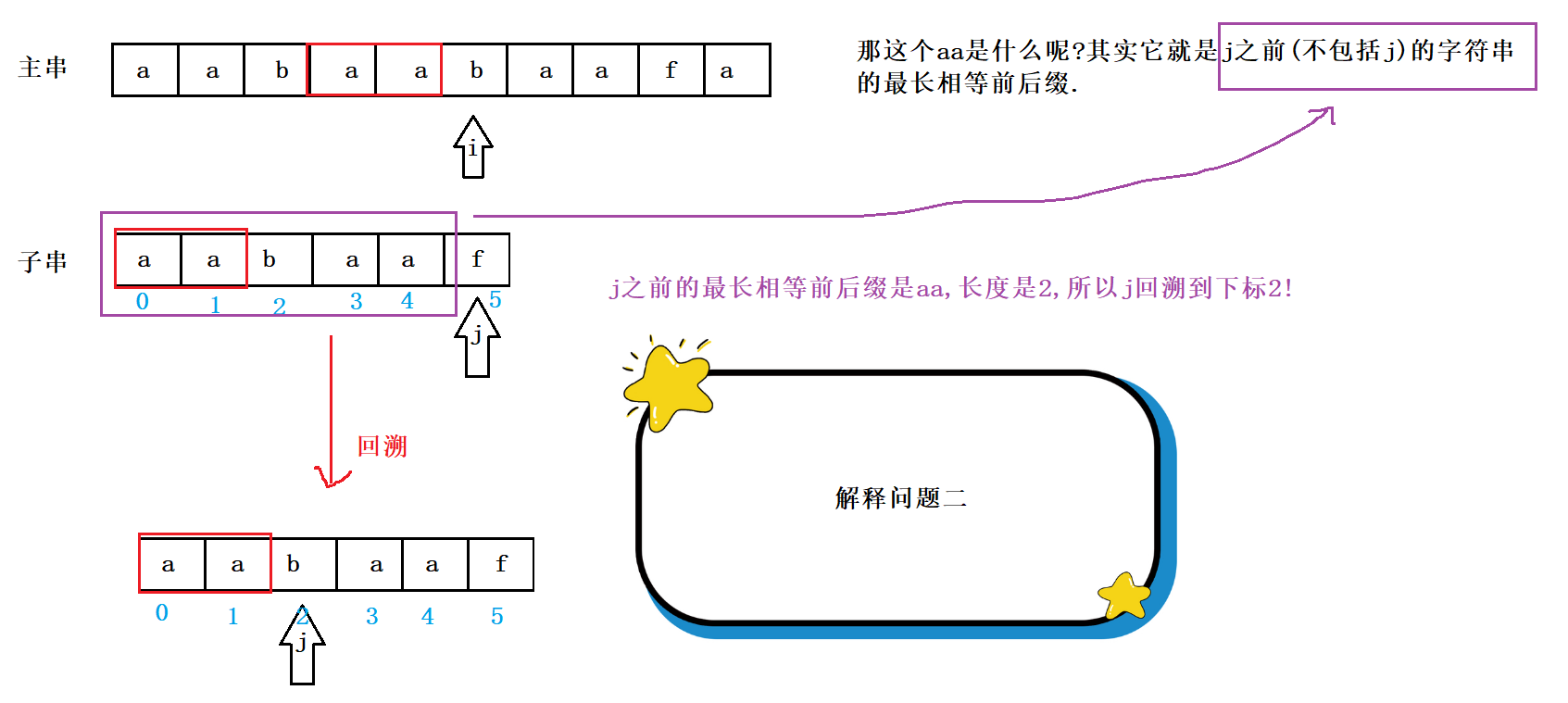
所以现在的关键问题就是 , 我们需要有这样一个数组 , 通常就叫next数组 , 这个数组记录了当子串中下标为j的字符与主串失配后 , j应该回溯到的位置 . 比如上面的例子中 , 当j = 5 时 , 失配 , 此时next[5] = 2 , 所以j回溯到下标2的位置 , 这个2也是j = 5 之前的子串的最长相等前后缀 .
比如 , 下面这个字符串 , 它的next数组就是这样的 :

- 对于第一个a , 它前面什么都没有 , 所以next[0]默认为-1 ;
- 对于第二个a , 它前面是一个a , 而一个a的最长公共前后缀长度是0 , 所以next[1] = 0 ;
- 对于第三个b , 它前面是aa , 其最长公共前后缀长度是1 , 所以next[2] = 1 .
- …
这是我们手动求next数组 , 那当然很简单 . 我们现在需要的 , 是用代码实现next数组的求解 , 这就是我们的下一个重点任务 !
三 : 求next数组
定义 : next 数组考虑的是除当前字符外的最长相同前缀后缀 .
初始化 : next[0] = -1 , next[1] = 0 .
遍历顺序 : 从前往后 , 因为求后面的next值是要用到前面的next值的 .
计算 : 假设我们已知next[ j ] = k , 说明 j 之前的字符串的最长相等前后缀长度是 k . 此时我们的目标是求next[ j + 1 ] . 整个字符串为p :


我们来详细解说一下 :


到这儿就解说得差不多了 , 上面的图片也是帮助大家以形式化方式理解这一操作过程的 . 根据我们的分析 , 写出代码 :
private void getNext(int[] next, String p) {
next[0] = -1;//next[0]其实没有意义,
int pLen = p.length();
int j = 0;
int k = -1;//next[j]=k,所以j=0时,k=next[0]=-1
/*j从0开始,因为while循环中j是先++再赋值,所以j从0开始,后面就是先给1下标位置
赋值.我们前面分析next[1] = 0,那为什么不直接初始化呢?因为p字符串长度未必大于1,
在while循环中进行赋值,可以省去一步判断,如果p.length()<=1,那么while就进不来*/
while(j < pLen - 1) {
/*一样的原因,后面是给j++进行赋值,所以j=pLen-2时进入循环,
就给next[pLen-1]赋值了*/
if(k == - 1 || p.charAt(j) == p.charAt(k)) {
/*
当p[j]==p[k],此时next[j+1] = k+1,也就是下面这三行代码
*/
k++;
j++;
next[j] = k;
} else {
/*否则,将next[k]赋值给k*/
k = next[k];
}
}
}
求next数组纯享版 :
private void getNext(int[] next, String p) {
int pLen = p.length();
next[0] = -1;
int k = -1;
int j = 0;
while(j < pLen - 1) {
if(k == - 1 || p.charAt(j) == p.charAt(k)) {
k++;
j++;
next[j] = k;
} else {
k = next[k];
}
}
}
得到next数组了 , 结合我们前面对KMP算法的分析 , 就可以写出寻找子串的代码了 :
public int strStr(String haystack, String needle) {
char[] s = haystack.toCharArray();
char[] p = needle.toCharArray();
int i = 0;
int j = 0;
int sLen = haystack.length();
int pLen = needle.length();
int[] next = new int[pLen];
getNext(next, needle);
while(i < sLen && j < pLen) {
if(j == -1 || s[i] == p[j]) {//匹配成功,i和j同步前进
i++;
j++;
} else {//匹配失败,i不动,j回溯到next[j]位置
j = next[j];
}
}
if(j == pLen) {//如果j走到末尾,匹配成功,返回主串中匹配成功的初始位置
return i - j;
} else {
return -1;//否则返回-1
}
}
这也是力扣这题的答案 .
至此 , KMP算法就整个讲解完了 . 当然KMP算法还有一些优化的策略 , 你大可以查阅其他资料进行进一步学习 . 本文仅仅是最初阶的KMP算法的实现罢了 .
本文到此结束 !
















 1727
1727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









