







背景前摇(省流可以跳过这部分)
实习的时候厚脸皮请教了一位办公室负责做爬虫这块的老师,给我推荐了Scrapy框架。
我之前学过一些爬虫基础,但是用的是比较常见的BeautifulSoup和Request,于是得到Scrapy这个关键词后,先问了一下Kimi这些爬虫框架的区别和优劣:

可以看出,BeautifulSoup适合学校教授课程用的小项目,但遇到大型的爬虫还是需要技术老师推荐的Scrapy。
时间充裕的话可以先从BeautifulSoup入门学起来。
以前BeautifulSoup我学的时候B站有个UP讲得挺好的,手把手教实操,结果今天一看都找不到视频了,实在是可惜。所以这次我学习Scrapy就决定把看到的好教程和遇到的问题都记下来。
不过,很幸运的是,在写完这篇帖子的几天以后,我又刷到了这位up的视频:
【【爬虫策略】20分钟掌握beautifulsoup | 手把手新人向 | 大学生编程 | 程序员 | 爬虫基础入门-哔哩哔哩】 https://b23.tv/avKQhdV
【【保姆级】陪你看官方文档 | BeautifulSoup4 | 爬虫快速入门 | 手把手新人向 | 爬虫策略 | 豆瓣爬虫 | bs4-哔哩哔哩】 https://b23.tv/9nN5kUz
另外,关于BeautifulSoup我还发现了一个很好的入门帖子:
http://t.csdnimg.cn/9clGT
传送门
菜鸟教程
链接:https://www.runoob.com/w3cnote/scrapy-detail.html
点此进入菜鸟教程
这个算是我看过的教程帖子里面比较通俗易懂、简明扼要又流程规范的了,当然也不是十全十美,跟着步骤操作还是会遇到一些小问题。
1.安装库

这一步没啥问题,正常按着步骤装就是,我电脑环境算是复杂的,都没遇到奇怪的报错。但是有条件的话建议装个Anaconda,然后为Scrapy专门建一个虚拟环境,免得日后跟其他库不兼容的情况发生。
以下步骤展示的是有Anaconda的情况下安装虚拟环境,没有Anaconda的可以跳过这步。



从创建项目这一步开始,就可以和菜鸟教程介绍的流程第一步接上了。

菜鸟教程的第二步没什么问题,跟这做就行。

到了第三步这里,有一个地方需要做一点小改动。
运行到这一步,会发现一直报一个莫名其妙的错误:


AI的方法并没有什么卵用,可见这错误多半不是我们该背的锅。

解决方案也很简单——将写入模式改为 ‘wb+’ 就不会报错了
参考链接:https://zoyi14.smartapps.cn/pages/note/index?origin=share&slug=b53ac2effb85&_swebfr=1&_swebFromHost=baiduboxapp
简书大神的回答

然后继续往下走菜鸟教程,直到执行完爬虫,这个时候应该文件目录里会存在一个html文件。


但是,千万不要双击该html文件直接打开!!否则你会惊喜地发现——什么也没有。
(很奇怪我这次的文件居然打开有内容,之前尝试点开好几次都是白板……不知道触发了什么奇怪的buff)

如果确实遇到了白板也别害怕,用Pycharm或者VScode这类支持写程序的软件打开看看,你就会发现其实爬取是成功了的。
这一步能看见网页源代码的话,继续跟着菜鸟教程走就是了。

直到有一个步骤的命令有一个奇怪的$符号打头,询问Kimi后发现并没有什么意义,我猜或许是编写教程的人手误?不管这个符号,正常输入命令就行:

附上我的示例执行效果图:

最后看到Spider Closed就是OK了(我的代码是最终版,加了一些命令,所以输出比较多,看不见这句话“”传智播客官网-好口碑IT培训机构,一样的教育,不一样的品质”,如果正常走到这一步的话能在黑窗口看见这句话顺利打印出来。

后面按着教程来,输出json,csv文件啥的步骤都没什么问题。

(思考题这弱弱问一句,我咋没找到yield函数在哪呢???
不过这个问题不大,上网查查别的教程或者问问Kimi都行,菜鸟这里自带的补充学习链接也可以看看。)

我会把我照着菜鸟教程写的项目打包上传CSDN存档,有需要的朋友可以自行下载。
(我每次都设置了免费不需要积分,但是好像CSDN会自动调整价格……)
菜鸟教程部分到此结束
下面进入B站视频部分
这个视频也是我自己看了一些后觉得讲的很清楚并且流程很规范的,从零开始建工程目录,而且涉及到翻页爬虫的处理。
链接:https://www.bilibili.com/list/watchlater?oid=30493305&bvid=BV1es411F73F&spm_id_from=333.337.top_right_bar_window_view_later.content.click
B站传送门
3分钟左右的时候在settings.py里加了一行LOG_LEVEL = ‘WARN’,起一个减少日志负担的作用。


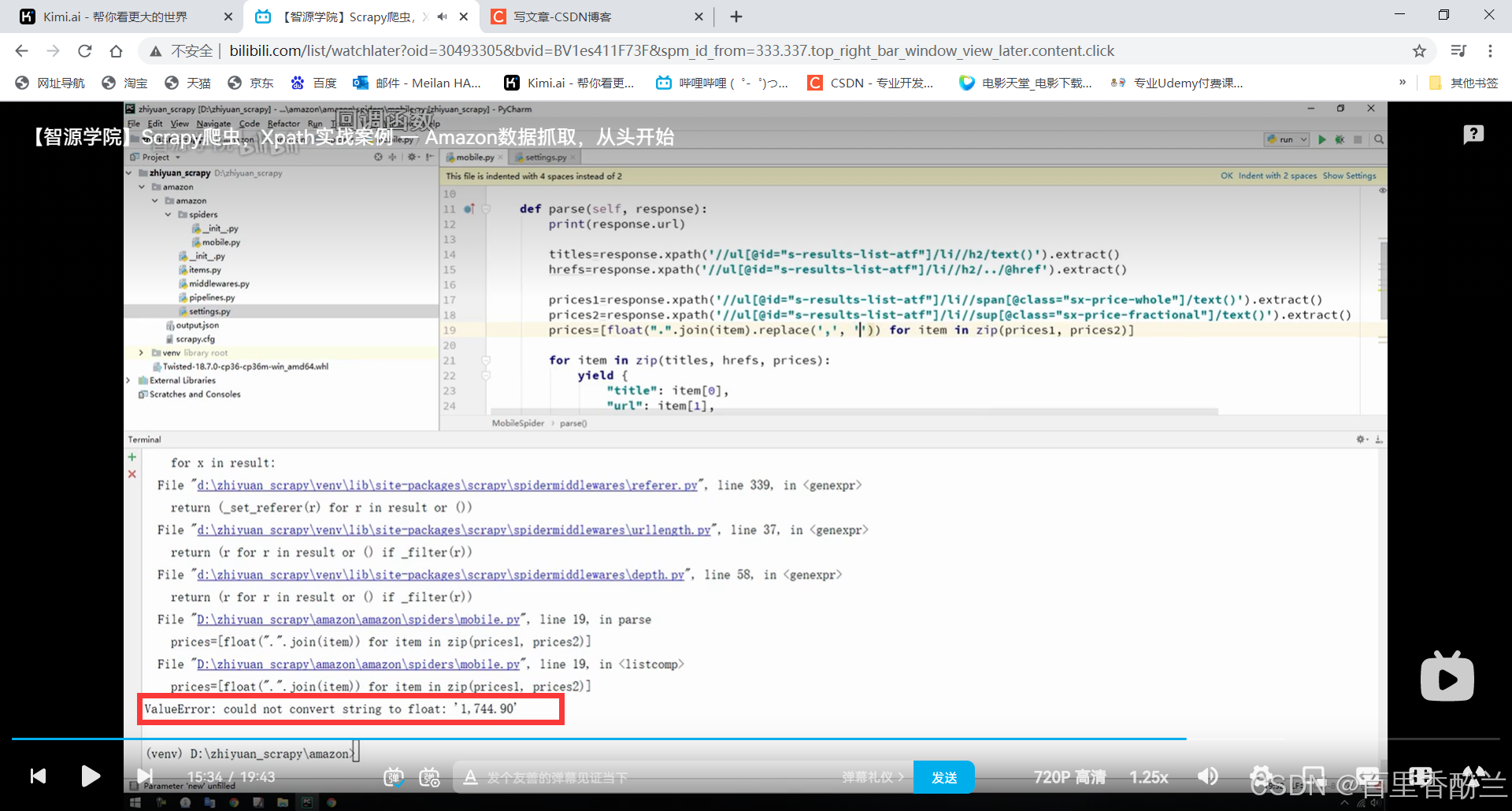
很不幸的是我和评论区的这位遇到了一模一样的问题,我也还没有找到靠谱的解决方案,但是没关系,重点学视频里翻页爬取的方法,把代码思路写熟手以后,下次复用到其他网页就不一定会遇到503错误了


我这搜罗了一些可能的解决办法给大家参考,如果有成功解决的小伙伴可以评论区分享一下。
https://docs.pingcode.com/ask/218781.html
可以试试,不保证结果

没有源码,特别难打的这句话我手敲了:
print(respomse.xpath(‘//ul[@id=“s-results-list-atf”]/li//h2/text()’).extract())

关于这部分HTML和XPath我之前学BeautifulSoup的时候有一些基础,所以就没有看该视频之前的内容,可以去这位UP的主页自行寻找,或者遇事不决问Kimi。
我个人感觉BeautifulSoup和Scrapy的思路很相似,都是给url,然后获取html内容,再通过类似正则表达式的思路把需要的文字提取出来,放在变量里,再把同类的变量归类到列表里,排得整整齐齐,就得到了结构化的数据。
这个价格分为了整数和小数两部分,UP的处理方法可以学习和参考,我觉得是个很好的思路,可以积累经验,下次遇到就知道怎么处理了。(还有一些类似的小细节,比如ul下级是li这种HTML知识)
分别获取小数点前和小数点后的数据price1,price2,然后拼起来。
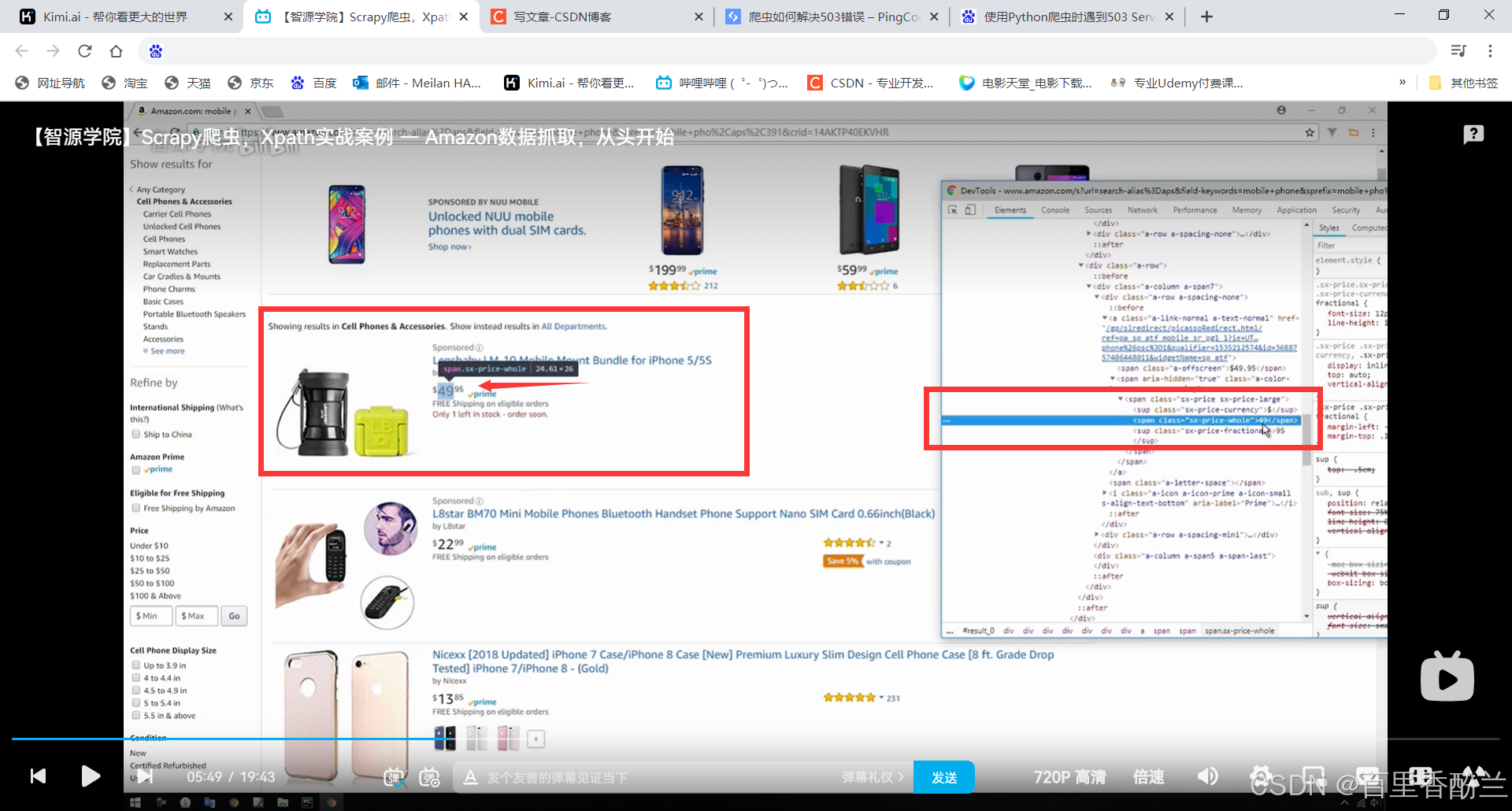


别忘了设置为float,存进数据库(如果有)的话更容易处理(比如比较大小)。
后面遇到比较大的数有逗号碍事(比如’1,299’这种),就用replace方法,通过空字符串替代’,',避免组合遇到困难。

比较难打的代码块:
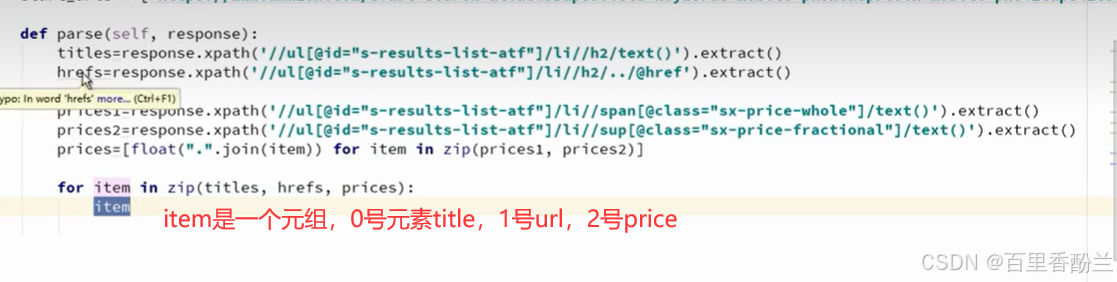
def parse(self, response):
titles = response.xpath('//ul[@id="s-results-list-atf"]/li//h2/text()').extract()
hrefs = response.xpath('//ul[@id="s-results-list-atf"]/li//h2/../@href').extract()
prices1 = response.xpath('//ul[@id="s-results-list-atf"]/li//span[@class="sx-price-whole"]/text()').extract()
prices2 = response.xpath('//ul[@id="s-results-list-atf"]/li//sup[@class="sx-price-fractional"]/text()').extract()
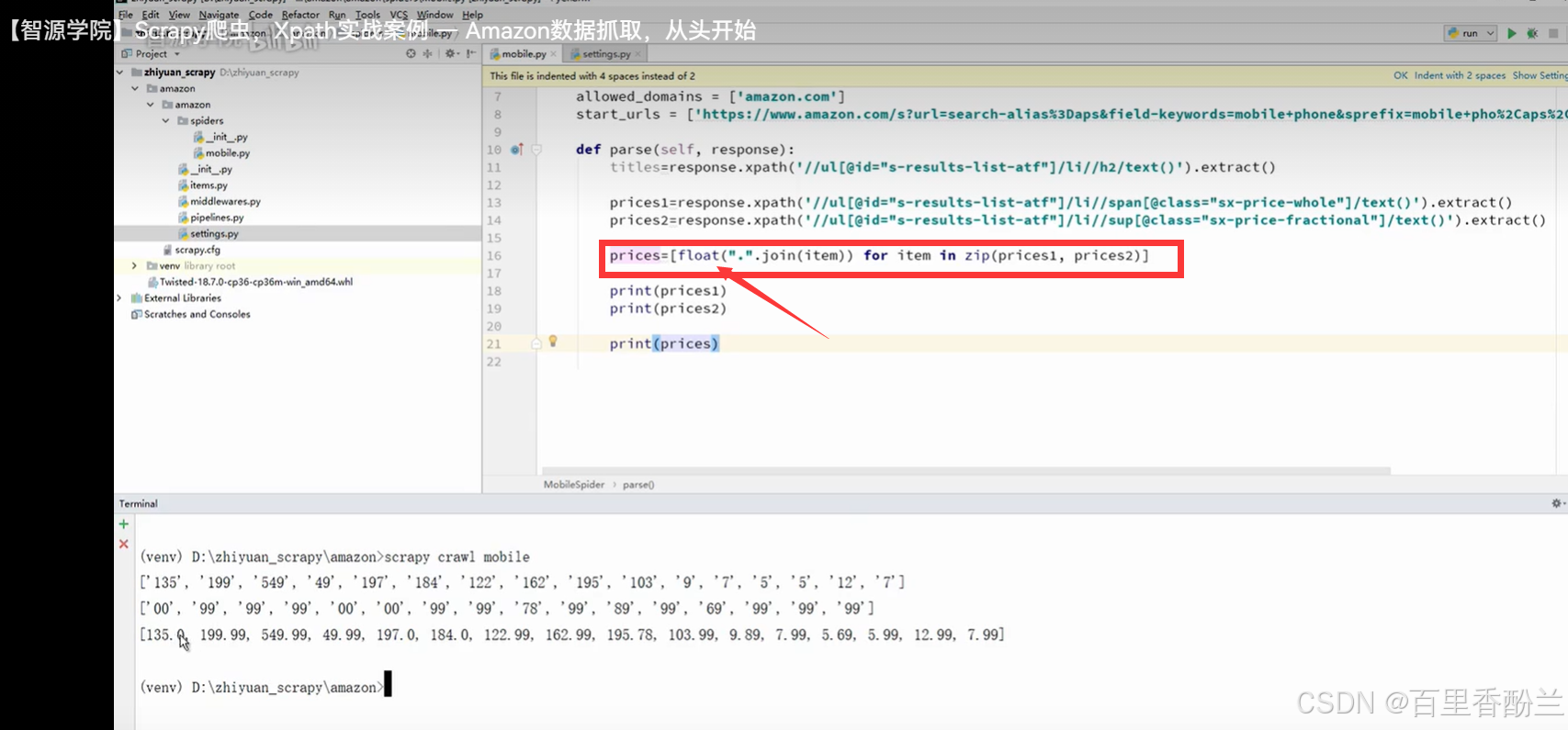
price = [float(".".join(item)) for item in zip(price1,price2)]
print(prices1)
print(prices2)
print(price)
把获取到的信息通过zip函数整理打包成元组:
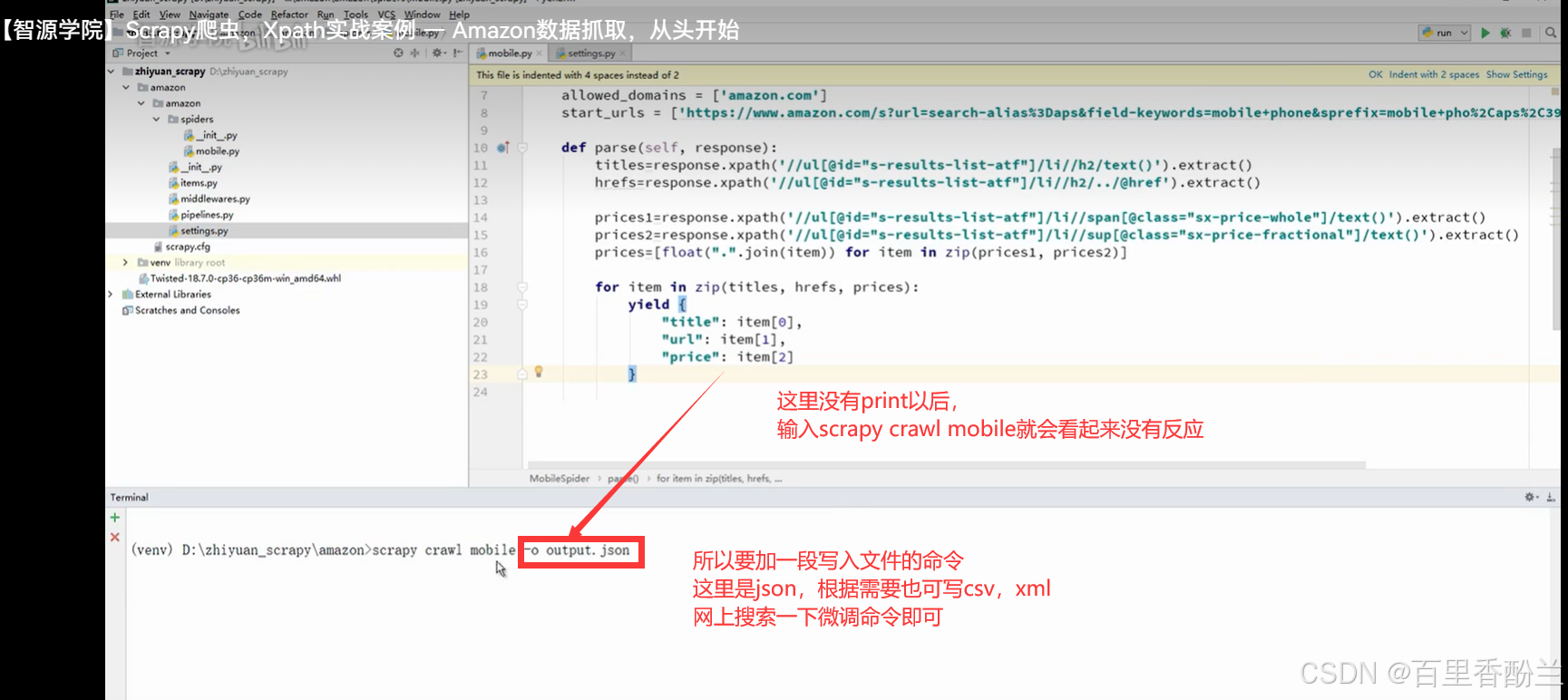
爬取多页的话就需要获取点击下一页的按钮,这也正是我看中这个教程的地方,前面写到Scrapy本身就更适合大规模数据爬取,那只爬一页也太屈才了。

检查网页源代码,找到这个“下一页”按钮的源链接和id。

然后照样的套路,XPath获取到链接,不过这里是个相对地址。
《相对地址也没关系,前面的域名我们自己加就完了》这里确实能解决问题,但我还是想知道这种走捷径的方法如果有应付不了的时候,应该怎么办呢?

遇到这个NoneType问题,老师判断是取到头了,没有下一页的内容造成的。
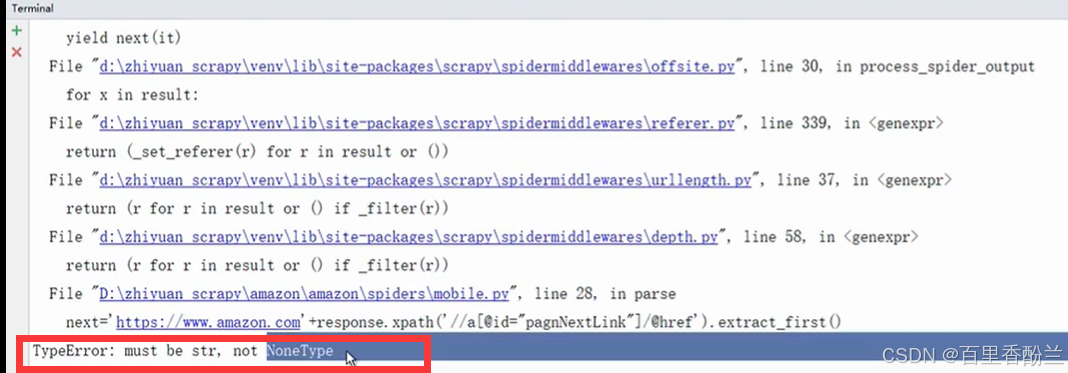
解决办法是在取下一页以前加个判断语句:

mobile.py完整代码:

import scrapy
from scrapy import Request
class MobileSpider(scrapy.Spider):
name = "mobile"
allowed_domains = ["amazon.com"]
start_urls = ["https://www.amazon.com/s?k=mobile+phone&__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&crid=266D1NQXSO7K4&sprefix=mobile+phon%2Caps%2C250&ref=nb_sb_noss_2"]
def parse(self, response):
print(response.url)
titles = response.xpath('//ul[@id="s-results-list-atf"]/li//h2/text()').extract()
hrefs = response.xpath('//ul[@id="s-results-list-atf"]/li//h2/../@href').extract()
prices1 = response.xpath('//ul[@id="s-results-list-atf"]/li//span[@class="sx-price-whole"]/text()').extract()
prices2 = response.xpath('//ul[@id="s-results-list-atf"]/li//sup[@class="sx-price-fractional"]/text()').extract()
prices = [float(".".join(item).replace(',','')) for item in zip(price1,price2)]
for item in zip(titles, hrefs, prices):
yield{
"title": item[0],
"url": item[1],
"price": item[2]
}
next = response.xpath('//a[@id="pagnNextLink"]/@href').extract_first()
if next != None:
next_url = 'https://www.amazon.com' + next
yield Request(next_url)
结合这两个案例,我找了个大陆能登上去的网站七禾网,自己写了一段Scrapy代码爬取测试,成功获取到了专栏文章标题。
被爬取的七禾网链接:https://www.7hcn.com//category/88-27.html
点击打开,这次爬取测试应该不会503错误了

成果展示:

爬取到的HTML:

爬取到的Json:

爬取到的XML:

爬取到的CSV:

唯一美中不足的是这个网站的翻页只有逐页翻或者直达下一页,没有Next Page这个选项,所以无法测试全部学到的功能,但用来做练习来说已经完全够用了。
我自己写的练习代码也会同步上传到CSDN,欢迎有需要的朋友下载~

。

















 1884
1884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









