







 超级会员免费看
超级会员免费看
在上一篇文章【1】中,我们已经得到了与最大熵模型之学习等价的带约束的最优化问题:
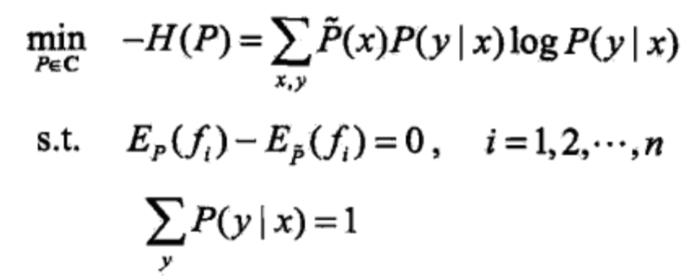
注意上述公式中还隐含一个不等式约束即 P(y|x)≥0。求解这个带约束的最优化问题,所得之解即为最大熵模型学习的解。本文就来完成这个推导。
现在这里需要使用拉格朗日乘数法,并将带约束的最优化之原始问题转换为无约束的最优化之对偶问题,并通过求解对偶问题来求解原始问题。首先,引入拉格朗日乘子,并定义拉格朗日函数L(P, w):
 本文详细介绍了最大熵模型的学习过程,利用拉格朗日乘数法将带约束的最优化问题转换为无约束的对偶问题。通过对偶问题的求解,探讨了最大熵模型与多元逻辑回归的关系,并证明了对偶函数极大化等价于最大熵模型的极大似然估计。最后,阐述了如何将最大熵模型的学习问题转化为求解对数似然函数极大化的问题。
本文详细介绍了最大熵模型的学习过程,利用拉格朗日乘数法将带约束的最优化问题转换为无约束的对偶问题。通过对偶问题的求解,探讨了最大熵模型与多元逻辑回归的关系,并证明了对偶函数极大化等价于最大熵模型的极大似然估计。最后,阐述了如何将最大熵模型的学习问题转化为求解对数似然函数极大化的问题。
在上一篇文章【1】中,我们已经得到了与最大熵模型之学习等价的带约束的最优化问题:
注意上述公式中还隐含一个不等式约束即 P(y|x)≥0。求解这个带约束的最优化问题,所得之解即为最大熵模型学习的解。本文就来完成这个推导。
现在这里需要使用拉格朗日乘数法,并将带约束的最优化之原始问题转换为无约束的最优化之对偶问题,并通过求解对偶问题来求解原始问题。首先,引入拉格朗日乘子,并定义拉格朗日函数L(P, w):
 2080
2080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




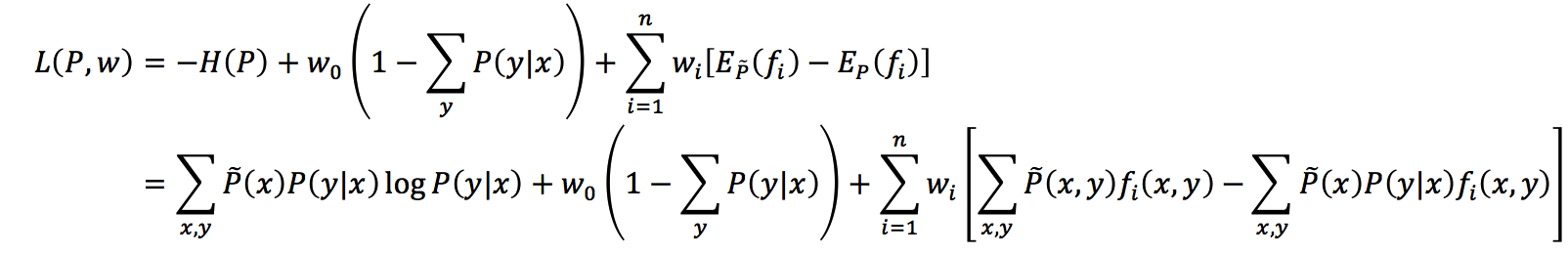

 订阅专栏 解锁全文
订阅专栏 解锁全文
























