







1. 条件熵
在这之前,我们先定义信息熵的概念,假设样本集合
D
D
D 中第
k
k
k 类样本所占的比例为
p
k
(
k
=
1
,
2
,
.
.
.
,
N
)
p_k(k=1,2,...,N)
pk(k=1,2,...,N) ,则
D
D
D 的信息熵定义为
E
n
t
(
D
)
=
−
∑
k
=
1
N
p
k
l
o
g
2
p
k
Ent(D)=-\sum_{k=1}^{N}p_klog_2p_k
Ent(D)=−k=1∑Npklog2pk
E
n
t
(
D
)
Ent(D)
Ent(D) 的值越小,则
D
D
D 的不确定性越高。
设
X
∈
{
x
1
,
x
2
,
⋯
,
x
n
}
,
Y
∈
{
y
1
,
y
2
,
⋯
,
y
m
}
X \in \{ x_1,x_2,\cdots,x_n\}, Y \in \{ y_1,y_2,\cdots,y_m\}
X∈{x1,x2,⋯,xn},Y∈{y1,y2,⋯,ym} ,则已知条件
X
X
X 下求
Y
Y
Y 的条件熵为:
H
(
Y
∣
X
)
=
∑
i
=
1
n
p
(
x
i
)
H
(
Y
∣
X
=
x
i
)
=
−
∑
i
=
1
n
p
(
x
i
)
∑
j
=
1
m
p
(
y
i
∣
x
i
)
log
p
(
y
i
∣
x
i
)
H(Y|X)=\sum_{i=1}^np(x_i)H(Y|X=x_i)=- \sum_{i=1}^np(x_i) \sum_{j=1}^mp(y_i|x_i) \log p(y_i|x_i)
H(Y∣X)=i=1∑np(xi)H(Y∣X=xi)=−i=1∑np(xi)j=1∑mp(yi∣xi)logp(yi∣xi)
2. 最大熵原理
最大熵原理指出,对一个随机事件的概率分布进行预测时,预测应当满足全部已知的约束,而对未知的情况不要做任何主观假设。在这种情况下,概率分布最均匀,预测的风险最小,因此得到的概率分布的熵是最大。
示例如下:


3. 最大熵模型定义
对于任意的特征函数
f
f
f,记
E
p
(
f
)
E_p( f )
Ep(f) 表示f在训练数据
T
T
T 上关于
p
(
x
,
y
)
p (x, y)
p(x,y) 的数学期望,有:
E
p
~
f
=
∑
x
,
y
p
~
(
x
,
y
)
f
(
x
,
y
)
E_{\widetilde{p}}f=\sum_{x,y} \widetilde{p}(x,y)f(x,y)
Ep
f=x,y∑p
(x,y)f(x,y)对于任意的特征函数
f
f
f,记
E
p
(
f
)
E_p( f )
Ep(f) 表示f在模型上关于
p
(
x
,
y
)
p (x, y)
p(x,y) 的数学期望,有:
E
p
f
=
∑
x
,
y
p
(
x
,
y
)
f
(
x
,
y
)
E_{p}f=\sum_{x,y} p(x,y)f(x,y)
Epf=x,y∑p(x,y)f(x,y)又因为式中
p
(
x
,
y
)
p(x,y)
p(x,y) 是未知的,并且我们建模的目标是
p
(
y
∣
x
)
p(y|x)
p(y∣x) ,所以我们可以使用条件概率公式得到
E
p
f
=
∑
x
,
y
p
~
(
x
)
p
(
y
∣
x
)
f
(
x
,
y
)
E_pf=\sum_{x,y} \widetilde{p}(x)p(y|x)f(x,y)
Epf=x,y∑p
(x)p(y∣x)f(x,y)我们期望从训练数据中得到的期望应该和模型中的期望是一样的,所以有如下的约束:
E
p
~
f
=
E
p
f
E_{\widetilde{p}}f=E_{p}f
Ep
f=Epf假设满足所有约束条件的模型集合为
{
E
P
(
f
i
)
=
E
p
~
(
f
i
)
}
\{E_P(f_i)= E_{\widetilde{p}}(f_i) \}
{EP(fi)=Ep
(fi)}设条件熵为
H
(
P
)
=
−
∑
x
,
y
P
~
(
x
)
P
(
y
∣
x
)
log
P
(
y
∣
x
)
H(P)=-\sum_{x,y} \widetilde{P}(x)P(y|x) \log P(y|x)
H(P)=−x,y∑P
(x)P(y∣x)logP(y∣x)在满足约束条件的集合中,使得条件熵最大的模型称之为最大熵模型。
4. 最大熵学习



具体例子如下:

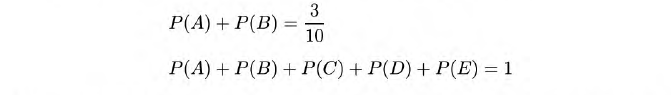
求其最大熵模型。


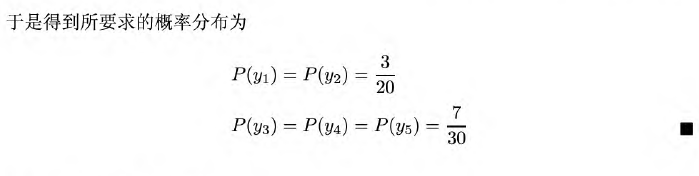















 944
944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









