







本博客将介绍最简单的表格型方法(tabular methods)来讲解如何使用value-based方法求解强化学习过程。
1. Q表格 Q-table
Q表格是应用于无模型马尔科夫决策过程(Model-Free MDP) 的一种方法。顾名思义,Q-表格就是一张表格,如果Q-表格已经训练好了的话,就可以通过这个表格来比较某个状态下不同动作的价值,从而选择动作。

上表中Q函数的值表示当Agent在某个状态时选择了某个动作,后续总共能得到多少反馈。根据这个表格,Agent就可以知道在当前的状态下选择哪个动作可以得到更大的价值。
例如在Agent处于状态 s 4 s_4 s4时,选择动作 a 4 a_4 a4就会有最大的价值 Q ( s t = s 4 , a t = a 4 ) = 23.5 Q(s_t=s_4,a_t=a_4)=23.5 Q(st=s4,at=a4)=23.5
Q表格的应用使得强化学习的目标具有很强的导向性,环境给出的反馈是一个非常重要的指导因素,Agent就是根据环境的反馈(或者说动作的价值)去选择动作的。
显然,应用Q表格的前提是能够计算出Agent在某一环节下采取某一策略可以得到的反馈。
2. 无模型预测 Model-free Prediction
无模型预测是在无模型的马尔科夫决策过程中估计某个给定策略价值的方法,一般有以下两种方法:
- 蒙特卡罗策略评估(Monte Carlo policy evaluation, MC)
- 时序差分学习(Temporal Difference learning, TD)
2.1. 蒙特卡洛策略评估 Monte-Carlo Policy Evaluation
蒙特卡罗(Monte-Carlo,MC)方法是基于采样的方法,让Agent跟环境进行交互,得到很多轨迹,每个轨迹都有对应的总反馈: G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . G_t=R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3}+... Gt=Rt+1+γRt+2+γ2Rt+3+...取所有轨迹总反馈的均值,就可以知道某一个策略下对应状态的价值。
2.1.1. 有终止的马尔科夫决策过程
MC方法应用在有终止的马尔科夫决策过程时,价值估算的步骤如下:
在多个轨迹中,如果某个轨迹访问了状态 s s s,那么:
- 状态 s s s 的总访问数 N ( s ) + = 1 N(s)+=1 N(s)+=1;
- 状态 s s s 的总反馈值 R ( s ) + = G t R(s)+=G_t R(s)+=Gt;
循环此过程直到遍历完所有轨迹。
此时状态 s s s的价值通过计算总反馈之和的均值来估算,即 v ( s ) = R ( s ) N ( s ) v(s)=\frac{R(s)}{N(s)} v(s)=N(s)R(s);
根据大数定律,只要我们得到足够多的轨迹, v ( s ) v(s) v(s)就会向这个策略对应的真实价值收敛,即: lim N ( s ) → ∞ v ( s ) = v π ( s ) \lim_{N(s)\to \infty}v(s)=v^\pi(s) N(s)→∞limv(s)=vπ(s)
2.1.2. 持续性的马尔科夫决策过程
MC方法也可以应用在无终止的马尔科夫决策过程,即马尔科夫决策过程一直持续,没有最终结果。
假设现在有轨迹 τ = ( s 1 , a 1 , r 1 , . . . , s t , a t , r t ) \tau=(s_1,a_1,r_1,...,s_t,a_t,r_t) τ=(s1,a1,r1,...,st,at,rt),Agent处于状态 s 1 , s 2 , . . . , s t s_1,s_2,...,s_t s1,s2,...,st 时对应的总反馈分别为 g 1 , g 2 , . . . , g t g_1,g_2,...,g_t g1,g2,...,gt,则该轨迹的价值 v ( s t ) v(s_t) v(st) 可以用增量平均(Incremental Mean)来表达,如下式所示: v ( s t ) = 1 t ∑ i = 1 t G i = 1 t ( G t + ∑ i = 1 t − 1 G i ) = 1 t ( G t + ( t − 1 ) μ t − 1 ) = 1 t ( G t + t v ( s t − 1 ) − v ( s t − 1 ) ) = v ( s t − 1 ) + 1 t ( G t − v ( s t − 1 ) ) \begin{aligned} v(s_t) & = \frac{1}{t}\sum_{i=1}^{t}G_i \\ & = \frac{1}{t}(G_t+\sum_{i=1}^{t-1}G_i) \\ & = \frac{1}{t}(G_t+(t-1)\mu_{t-1}) \\ & = \frac{1}{t}(G_t+tv(s_{t-1})-v(s_{t-1})) \\ & = v(s_{t-1})+\frac{1}{t}(G_t-v(s_{t-1})) \end{aligned} v(st)=t1i=1∑tGi=t1(Gt+i=1∑t−1Gi)=t1(Gt+(t−1)μt−1)=t1(Gt+tv(st−1)−v(st−1))=v(st−1)+t1(Gt−v(st−1))其中: G t − v ( s t − 1 ) G_t-v(s_{t-1}) Gt−v(st−1)指的是残差, 1 t \frac{1}{t} t1是值该状态出现的次数。通过这个公式可以把上一时刻的价值 μ t − 1 \mu_{t-1} μt−1 与当前时刻的价值 μ t \mu_t μt 建立联系,从而处理连续不断的马尔科夫决策过程。
此时MC方法的价值估算的步骤如下:
首先采集数据,得到一个新的轨迹 τ = ( s 1 , a 1 , r 1 , . . . , s t , a t , r t ) \tau=(s_1,a_1,r_1,...,s_t,a_t,r_t) τ=(s1,a1,r1,...,st,at,rt);
采用增量的方法对轨迹 τ \tau τ进行更新,如下式所示:
- 某一状态 s t s_t st 的总访问数 N ( s t ) ← N ( s t ) + 1 N(s_t) \leftarrow N(s_t)+1 N(st)←N(st)+1
- 某一状态 s t s_t st 的价值 v ( s t ) ← v ( s t ) + 1 N ( s t ) ( G t − v ( s t ) ) v(s_t) \leftarrow v(s_t)+\frac{1}{N(s_t)}(G_t-v(s_t)) v(st)←v(st)+N(st)1(Gt−v(st))
也可以直接把公式中的 1 N ( S t ) \frac{1}{N(S_t)} N(St)1替换成 α \alpha α(学习率),用于控制更新的速率。
2.2. 时序差分学习 Temporal Difference Learning
时序差分学习借用了梯度下降的思想,在重复试验的过程中,环境下一个状态的价值会不断地去强化影响上一个状态的价值。
我们在 Gridworld_td 中演示下一个状态影响上一个状态的动态过程。
GridWorld时序差分学习可视化过程
在训练的过程中,我们可以看到小黄球(Agent)在不断地在地图上进行探索,在探索的过程中会先迅速地发现有Reward的地方(图中有两种Reward,+1和-1)。最开始的时候,只是这些有Reward的格子才有价值。当不断地重复走这些路线的时候,这些有价值的格子可以去慢慢地影响它附近的格子(被影响的格子都是轨迹中的格子,因为Agent的轨迹非常多所以可以认为周围都被影响了)的价值,可以类比于一座高山或者一个盆地,山顶和谷底就是有价值的状态,周围的地貌也会被这些有价值的状态影响。

反复训练之后,这些有Reward 的格子周围的格子的状态就会慢慢地被正向或负向地强化。最终所有状态都会收敛到一种最优的状态,此时Agent自然就知道了通向高价值状态的路径。
TD介于蒙特卡洛方法和动态规划方法之间,不需要MDP的转移矩阵和反馈函数,可以从不完整的轨迹中进行学习。
TD算法的框架可以表示如下:
最简单的TD算法:TD(0)
每往前走一步,就用得到的反馈值来更新上一时刻的反馈值: v ( s t ) ← v ( s t ) + α ( R t + 1 + γ v ( s t + 1 ) − v ( s t ) ) v(s_t)\leftarrow v(s_t)+\alpha(R_{t+1}+\gamma v(s_{t+1})-v(s_{t})) v(st)←v(st)+α(Rt+1+γv(st+1)−v(st))其中 R t + 1 + γ v ( s t + 1 ) R_{t+1}+\gamma v(s_{t+1}) Rt+1+γv(st+1)是指当前时刻动作的折扣收益 G t n G_t^n Gtn,由两部分组成:
- 走了某一步后得到的实际奖励: R t + 1 R_{t+1} Rt+1;
- 折扣后的估计反馈 γ v ( s t + 1 ) \gamma v(s_{t+1}) γv(st+1)
上面的TD算法框架介绍的是TD(0),即1-step TD。增加步数可以变成 n-step TD,比如 TD(2),即往前走两步才得到一个反馈。如果 n= ∞ \infty ∞, 即整个过程结束过后,再进行得到最终反馈对价值进行更新,那么TD 就转变成了 MC: T D ( ∞ ) ⇐ ⇒ M C TD(\infty)\Leftarrow\Rightarrow MC TD(∞)⇐⇒MC
n-step TD的折扣收益如下式所示: G t n = R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . + γ n − 1 R t + n + γ n v ( s t + n ) G_t^n=R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3}+...+\gamma^{n-1} R_{t+n}+\gamma^nv(s_{t+n}) Gtn=Rt+1+γRt+2+γ2Rt+3+...+γn−1Rt+n+γnv(st+n)
得到折扣收益之后,价值更新式可以表达为: v ( s t ) ← v ( s t ) + α ( G t n − v ( s t ) ) v(s_t)\leftarrow v(s_t)+\alpha(G_t^n-v(s_t)) v(st)←v(st)+α(Gtn−v(st))
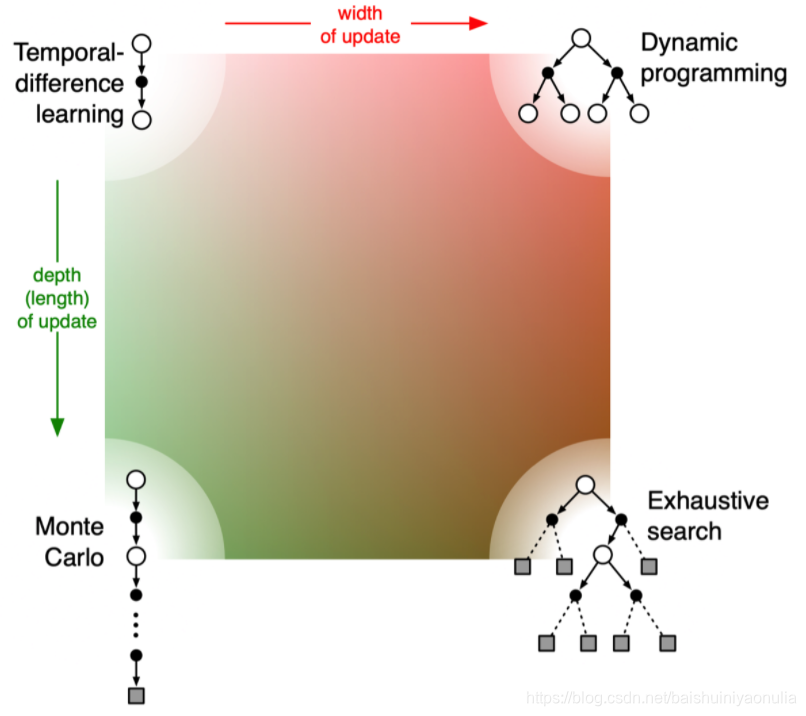
2.3. 动态规划(DP)、蒙特卡洛(MC)、时序差分(TD)的比较
| DP | MC | TD | |
|---|---|---|---|
| Bootstrapping 更新方式 | 使用了Bootstrapping | 没有使用Bootstrapping,而是根据实际的反馈来进行更新 | 使用了Bootstrapping |
| Sampling 采用方式 | 没有使用Sampling,而是用贝尔曼期望等式来更新状态价值 | 纯Sampling | 使用了Sampling,价值由两部分组成,一部分使用Sampling方法,一部分使用Bootstrapping方法 |
| State 状态处理 | 把环境所有相关的状态都进行求和 | 采样一个轨迹,计算该轨迹上的所有状态 | 从当前状态开始,每往前进一步就计算一次状态 |

它们的相互转换:
- 如果 TD 加大广度,就变成了 DP(因为 DP 是把所有状态都考虑进去来进行更新)。
- 如果 TD 加大深度,就变成了 MC。
- 如果 TD 加大深度,就变成了穷举(Exhaustive Search),穷举的方法既需要很深度的信息,又需要很广度的信息。
3. 无模型控制 Model-free Control
无模型控制是在无模型的马尔科夫决策过程中优化价值函数得到最佳策略的方法。我们可以把策略迭代(Policy Iteration)进行推广,使它能够兼容 MC 和 TD 的方法,即得到通用策略迭代(Generalized Policy Iteration, GPI)。
策略迭代由两个步骤组成:
- 根据给定的当前的策略 π \pi π来估计价值函数;
- 得到估计的价值函数后,通过贪心策略来改进原策略: π ′ = g r e e d y ( v π ) \pi'=greedy(v_\pi) π′=greedy(vπ)
通过策略迭代可以得到价值函数,但却无法知道相应的反馈函数 R ( s , a ) R(s,a) R(s,a)和状态转移函数 P ( s ′ ∣ s , a ) P(s'|s,a) P(s′∣s,a),所以这里有一个问题:当我们不知道奖励函数 R ( s , a ) R(s,a) R(s,a)和状态转移函数 P ( s ′ ∣ s , a ) P(s'|s,a) P(s′∣s,a)时,如何进行策略的优化?
通用策略迭代方法,用MC的方法代替DP的方法去估计Q函数就可以解决这个问题:
q π i = R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) v π i ( s ′ ) π i + 1 ( s ) = arg max a q π i ( s , a ) \begin{aligned} q_{\pi_i} & =R(s,a)+\gamma\sum_{s'\in S}P(s'|s,a)v_{\pi_i}(s') \\ \pi_{i+1}(s) & =\argmax_a q_{\pi_i}(s,a) \\ \end{aligned} qπiπi+1(s)=R(s,a)+γs′∈S∑P(s′∣s,a)vπi(s′)=aargmaxqπi(s,a)
下述算法即是用MC估计Q函数的算法:
Initialize:
\qquad π ( s ) ∈ A ( s ) , for all s ∈ S \pi(s)\in A(s),\text{for all }s\in S π(s)∈A(s),for all s∈S
\qquad Q ( s , a ) ∈ R , for all s ∈ S , a ∈ A ( s ) Q(s,a)\in \mathbb{R},\text{for all}s\in S,a\in A(s) Q(s,a)∈R,for alls∈S,a∈A(s)
\qquad R e t u r n s ( s , a ) ← empty list , for all s ∈ S , a ∈ A ( s ) Returns(s,a)\leftarrow \text{empty list},\text{for all}s\in S,a\in A(s) Returns(s,a)←empty list,for alls∈S,a∈A(s)Loop forever (for each episode):
\qquad choose S 0 ∈ S , A 0 ∈ A ( S 0 ) S_0\in S,A_0\in A(S_0) S0∈S,A0∈A(S0) randomly such that all pairs have probability > 0 >0 >0
\qquad Generate an episode from S 0 , A 0 S_0,A_0 S0,A0,following π : S 0 , A 0 , R 1 , . . . , S T − 1 , A T − 1 , R T \pi:S_0,A_0,R_1,...,S_{T-1},A_{T-1},R_T π:S0,A0,R1,...,ST−1,AT−1,RT
\qquad G ← 0 G\leftarrow 0 G←0
\qquad Loop for each step of episode, t = T − 1 , T − 2 , . . . , 0 : t=T-1,T-2,...,0: t=T−1,T−2,...,0:
\qquad \qquad G ← γ G + R t + 1 G\leftarrow \gamma G + R_{t+1} G←γG+Rt+1
\qquad \qquad Unless the pair S t , A t S_t,A_t St,At appears in S 0 , A 0 , S 1 , A 1 , . . . , S t − 1 , A t − 1 : S_0,A_0,S_1,A_1,...,S_{t-1},A_{t-1}: S0,A0,S1,A1,...,St−1,At−1:
\qquad \qquad \qquad Append G G G to R e t u r n s ( S t , A t ) Returns(S_t,A_t) Returns(St,At)
\qquad \qquad \qquad Q ( S t , A t ) ← average ( R e t u r n s ( S t , A t ) ) Q(S_t,A_t)\leftarrow \text{average}(Returns(S_t,A_t)) Q(St,At)←average(Returns(St,At))
\qquad \qquad \qquad π ( S t ) ← arg max a Q ( S t , a ) \pi(S_t)\leftarrow \argmax_a Q(S_t,a) π(St)←aargmaxQ(St,a)
下面是一个通俗的讲解:
- 假设每一个episode都有一个探索起点(Exploring Start, ES),ES保证所有的状态和动作在无限步的执行后也能被采样到
- 算法通过MC的方法产生了很多的轨迹,每个轨迹都可以算出它的价值,然后计算Q函数的均值。Q函数可以看成一个Q表格,通过采样的方法把Q表格每个单元上的值都填上,然后使用策略改进(Policy Improvement)的方法来选取更好的策略。
当得到Q函数后,就可以通过贪心方法去改进它。为了确保MC方法能够产生足够的轨迹,可以使用 ε \varepsilon ε-贪心进行策略探索。
ε \varepsilon ε-贪心的意思是说有 1 − ε 1-\varepsilon 1−ε的概率会按照Q函数来决定策略,有 ε \varepsilon ε的概率采取随机策略。通常在实现上 ε \varepsilon ε会随着时间递减。在最开始的时候,由于还不知道那个策略是最佳的,所以需要花一些代价去探索策略,随着训练的次数越来越多,最佳策略也会逐渐明了,此时就可以把 ε \varepsilon ε的值调小,让Q函数成为选择策略的主导。 π ( a ∣ s ) = { ε ∣ A ∣ + 1 − ε , if a ∗ = arg max a ∈ A Q ( s , a ) ε ∣ A ∣ , otherwise \pi(a|s) = \begin{cases} \frac{\varepsilon}{|A|}+1-\varepsilon, & \text{if $a^*=\argmax_{a\in A}Q(s,a)$} \\[2ex] \frac{\varepsilon}{|A|}, & \text{otherwise} \end{cases} π(a∣s)=⎩⎨⎧∣A∣ε+1−ε,∣A∣ε,if a∗=a∈AargmaxQ(s,a)otherwise
当我们使用MC方法和 ε \varepsilon ε-贪心来探索策略时,可以确保价值函数是单调的、不断改进的。
下述代码是融合 ε \varepsilon ε贪心的MC算法:
Initialize Q ( S , A ) = 0 , N ( S , A ) = 0 , ϵ = 1 , k = 1 Q(S,A)=0,N(S,A)=0,\epsilon=1,k=1 Q(S,A)=0,N(S,A)=0,ϵ=1,k=1
π k = ϵ -greedy ( Q ) \pi_k=\epsilon\text{-greedy}(Q) πk=ϵ-greedy(Q)
loop
\qquad Sample k -th k\text{-th} k-th episode ( S 1 , A 1 , R 2 , . . . , S T ) ∼ π k (S_1,A_1,R_2,...,S_T)\sim\pi_k (S1,A1,R2,...,ST)∼πk
\qquad for each state S t S_t St and action A t A_t At in the episode do
\qquad \qquad N ( S t , A t ) ← N ( S t , A t ) + 1 N(S_t,A_t)\leftarrow N(S_t,A_t)+1 N(St,At)←N(St,At)+1
\qquad \qquad Q ( S t , A t ) ← Q ( S t , A t ) + 1 N ( S t , A t ) ( G t − Q ( S t , A t ) ) Q(S_t,A_t)\leftarrow Q(S_t,A_t)+\frac{1}{N(S_t,A_t)}(G_t-Q(S_t,A_t)) Q(St,At)←Q(St,At)+N(St,At)1(Gt−Q(St,At))
\qquad end for
end loop
4.1. On-policy策略: Sarsa
Sarsa是一种同策略TD控制(On-policy TD Control)算法。在On-policy在学习的过程中只存在一种策略。Sarsa算法用这种策略去选取动作,也用这种策略去优化动作。
从2.2. 时序差分学习中可以知道,TD 是根据一个给定的策略去估计价值函数。接着我们要考虑怎么用TD框架来估计Q函数。这里提出一种方法叫Saras,Sarasota将原本TD更新价值的过程,变成了更新Q,如下式所示:
Q
(
S
t
,
A
t
)
←
Q
(
S
t
,
A
t
)
+
α
[
R
t
+
1
+
γ
Q
(
S
t
+
1
,
A
t
+
1
)
−
Q
(
S
t
,
A
t
)
]
Q(S_t,A_t)\leftarrow Q(S_t,A_t)+\alpha[R_{t+1}+\gamma Q(S_{t+1},A_{t+1})-Q(S_t,A_t)]
Q(St,At)←Q(St,At)+α[Rt+1+γQ(St+1,At+1)−Q(St,At)]
这个公式就是说可以用下一步的Q值
Q
(
S
t
+
1
,
A
t
+
1
)
Q(S_{t+1},A_{t+1})
Q(St+1,At+1)来更新当前的Q值
Q
(
S
t
,
A
t
)
Q(S_t,A_t)
Q(St,At)。为了理解这个公式,如下图所示,我们先把
R
t
+
1
+
γ
Q
(
S
t
+
1
,
A
t
+
1
)
R_{t+1}+\gamma Q(S_{t+1},A_{t+1})
Rt+1+γQ(St+1,At+1)当作是一个目标值(TD target),也就是
Q
(
S
t
,
A
t
)
Q(S_t,A_t)
Q(St,At)要去逼近的值。

Sarsa采用软更新的方式来逼近目标值,也就是每次只根据学习率 α \alpha α更新一点点。最终,Q值会慢慢地逼近到真实的目标值。
该算法由于每次更新值函数需要知道当前的状态(state)、当前的动作(action)、奖励(reward)、下一步的状态(state)、下一步的动作(action),即 ( S t , A t , R t + 1 , S t + 1 , A t + 1 ) (S_t,A_t,R_{t+1},S_{t+1},A_{t+1}) (St,At,Rt+1,St+1,At+1)这几个值 ,由此得名 Sarsa算法。每得到一次 ( S t , A t , R t + 1 , S t + 1 , A t + 1 ) (S_t,A_t,R_{t+1},S_{t+1},A_{t+1}) (St,At,Rt+1,St+1,At+1)就可以做一次更新
Sarsa属于单步更新算法,也就是说每执行一个动作,就会更新一次价值和策略。如果不进行单步更新,而是采取 n n n 步更新或者回合更新,即在执行 n n n 步之后再来更新价值和策略,这样就得到了 n n n 步 Sarsa(n-step Sarsa)。
具体来说,对于Sarsa,在
t
t
t 时刻其价值的计算公式为:
1-step Sarsa:
q
t
(
1
)
=
R
t
+
1
+
γ
Q
(
S
t
+
1
,
A
t
+
1
)
2-step Sarsa:
q
t
(
2
)
=
R
t
+
1
+
γ
R
t
+
2
+
γ
2
Q
(
S
t
+
2
,
A
t
+
2
)
.
.
.
n-step Sarsa:
q
t
(
2
)
=
R
t
+
1
+
γ
R
t
+
2
+
.
.
.
+
γ
n
−
1
R
t
+
n
+
γ
n
Q
(
S
t
+
n
,
A
t
+
n
)
\begin{aligned} \text{1-step Sarsa:}\qquad q_t^{(1)} & = R_{t+1}+\gamma Q(S_{t+1},A_{t+1}) \\ \text{2-step Sarsa:}\qquad q_t^{(2)} & = R_{t+1}+\gamma R_{t+2}+\gamma^2 Q(S_{t+2},A_{t+2}) \\ ... \\ \text{n-step Sarsa:}\qquad q_t^{(2)} & = R_{t+1}+\gamma R_{t+2}+...+\gamma^{n-1}R_{t+n}+\gamma^n Q(S_{t+n},A_{t+n}) \\ \end{aligned}
1-step Sarsa:qt(1)2-step Sarsa:qt(2)...n-step Sarsa:qt(2)=Rt+1+γQ(St+1,At+1)=Rt+1+γRt+2+γ2Q(St+2,At+2)=Rt+1+γRt+2+...+γn−1Rt+n+γnQ(St+n,At+n)
对于 S a r s a ( n ) Sarsa(n) Sarsa(n),它的更新策略为: Q ( S t , A t ) ← Q ( S t , A t ) + α ( q t ( n ) − Q ( S t , A t ) ) Q(S_t,A_t)\leftarrow Q(S_t,A_t)+\alpha(q_t^{(n)}-Q(S_t,A_t)) Q(St,At)←Q(St,At)+α(qt(n)−Q(St,At))
如果给 q t ( n ) q_t^{(n)} qt(n)加上衰减因子 λ \lambda λ 并进行求和,即可得到 S a r s a ( λ ) Sarsa(\lambda) Sarsa(λ) 的Q收获: q t λ = ( 1 − λ ) ∑ n = 1 ∞ λ n − 1 q t ( n ) q_t^\lambda=(1-\lambda)\sum_{n=1}^{\infty}\lambda^{n-1}q_t^{(n)} qtλ=(1−λ)n=1∑∞λn−1qt(n)
此时, n n n 步 S a r s a ( λ ) Sarsa(\lambda) Sarsa(λ) 的更新策略可以表示为: Q ( S t , A t ) ← Q ( S t , A t ) + α ( q t λ − Q ( S t , A t ) ) Q(S_t,A_t)\leftarrow Q(S_t,A_t)+\alpha(q_t^{\lambda}-Q(S_t,A_t)) Q(St,At)←Q(St,At)+α(qtλ−Q(St,At))
4.2. Off-policy策略: Q-learning
Q-learning是一种离策略TD控制(Off-policy TD Control)算法。
Off-policy 有很多好处:
- 可以利用策略探索来找到一个最佳的策略,学习效率高;
- 可以让Agent学习其他Agent的行为,进行模仿学习;
- 可以重用已有的策略产生的轨迹,以达到节省资源的目的。
在Off-policy在学习的过程中,有两种不同的策略:
- 目标策略
π
\pi
π Target Policy
目标策略根据已有经验来选择最优的策略,不需要和环境交互; - 行为策略
μ
\mu
μ Behavior Policy
行为策略可以在环境里面探索所有的动作、轨迹和经验,然后把这些经验交给目标策略去学习。
目标策略 π \pi π 直接在Q表格上取下一步能得到的所有状态,如下式所示: π ( S t + 1 ) = arg max a ′ Q ( S t + 1 , a ′ ) \pi(S_{t+1})=\argmax_{a'} Q(S_{t+1},a') π(St+1)=a′argmaxQ(St+1,a′)
行为策略 μ \mu μ 是一个随机的策略,一般会采用 ε \varepsilon ε-贪心策略,这时的行为策略 μ \mu μ 就不是一个完全随机的策略。
Q-learning目标值,由于Q-learning的下一个动作都是通过 arg max \argmax argmax 操作来选出来的,因此可以得到下式: R t + 1 + γ Q ( S t + 1 , A ′ ) = R t + 1 + γ Q ( S t + 1 , arg max Q ( S t + 1 , a ′ ) ) = R t + 1 + γ arg max a ′ Q ( S t + 1 , a ′ ) \begin{aligned} R_{t+1}+\gamma Q(S_{t+1},A') &=R_{t+1}+\gamma Q(S_{t+1},\argmax Q(S_{t+1},a')) \\ &= R_{t+1}+\gamma\argmax_{a'} Q(S_{t+1},a')\\ \end{aligned} Rt+1+γQ(St+1,A′)=Rt+1+γQ(St+1,argmaxQ(St+1,a′))=Rt+1+γa′argmaxQ(St+1,a′)
然后把Q-learning更新写成增量学习的形式,这样TD目标值就变成了 max \max max的值,即: Q ( S t , A t ) ← Q ( S t , A t ) + α [ R t + 1 + γ max a Q ( S t + 1 , a ) − Q ( S t , A t ) ] Q(S_t,A_t)\leftarrow Q(S_t,A_t)+\alpha[R_{t+1}+\gamma\max_{a}Q(S_{t+1},a)-Q(S_t,A_t)] Q(St,At)←Q(St,At)+α[Rt+1+γamaxQ(St+1,a)−Q(St,At)]
4.2. Sarsa与Q-learning的对比
Sarsa 是On-policy的时序差分学习方法,当Sarsa更新Q表格时需要用到下一步实际执行的动作 A t + 1 A_{t+1} At+1。 A t + 1 A_{t+1} At+1有可能是 ε \varepsilon ε-贪心方法采样出来的值,也有可能是 max Q \max Q maxQ 对应的动作,也有可能是随机选取的动作。
Q-learning是Off-policy 的时序差分学习方法,当Q-learning更新Q表格时需要用到 Q ( S ′ , a ) Q(S',a) Q(S′,a)对应的动作 A t + 1 A_{t+1} At+1, A t + 1 A_{t+1} At+1不一定是下一步执行的实际的动作,而是一个探索动作。Q-learning 默认的下一动作不是通过行为策略来选取的,而是在Q表格中选取最大值,所以Q-learning在学习的过程中不需要传入 A t + 1 A_{t+1} At+1。
事实上,Q-learning算法被提出的时间更早,Sarsa算法是Q-learning算法的改进。Sarsa 和 Q-learning 的更新公式都是一样的,区别只在目标值计算的这一部分:
- Sarsa是
R
t
+
1
+
γ
Q
(
S
t
+
1
,
A
t
+
1
)
R_{t+1}+\gamma Q(S_{t+1},A_{t+1})
Rt+1+γQ(St+1,At+1)
Sarsa是用自己的策略产生了 ( S t , A t , R t + 1 , S t + 1 , A t + 1 ) (S_t,A_t,R_{t+1},S_{t+1},A_{t+1}) (St,At,Rt+1,St+1,At+1)这一条轨迹,然后用 Q ( S t + 1 , A t + 1 ) Q(S_{t+1},A_{t+1}) Q(St+1,At+1)去更新原本的 Q ( S t , A t ) Q(S_t,A_t) Q(St,At) - Q-learning是
R
t
+
1
+
γ
max
a
Q
(
S
t
+
1
,
a
)
R_{t+1}+\gamma\max_{a} Q(S_{t+1},a)
Rt+1+γmaxaQ(St+1,a)
Q-learning按照最优的策略来去优化目标策略,同时可以寻找其他可能存在的更优路径


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











